NATS vs Kafka Messaging Systems
In the realm of modern software structure, messaging solutions play an indispensable part, serving as key integrators between various software applications and ensuring seamless data transmission. These silent stalwarts are responsible for accurate and timely data dispatch, constituting vital components for powerful, expandable, and efficient systems.

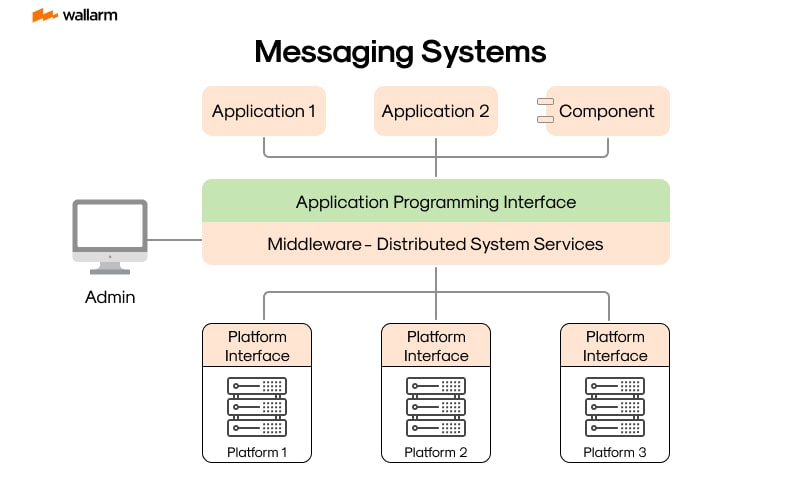
At their core, messaging solutions leverage the concept of disjunction. They methodically separate the information sending party (originator) and the information receiving party (recipient), thus permitting each to work independently. This strategy sets the stage for improved expansibility, advanced error recovery, and simplified system functioning.
Typically, in a messaging setup, an originator routes a data packet to a handler, who then makes sure that the assigned recipient gets it. The role of the handler is pivotal, they ensure the data packet reaches its destination, even if there could be times when the originator or recipient might be inactive.
Categorizing Messaging Solutions
Messaging systems basically exist in two forms, point-to-point and those based on the principle of publish-subscribe.
- Point-to-Point: This model stands out due to its characteristic one-on-one data packet delivery system where each packet, sent by the originator, is received by only one recipient. The data packet is stored in a line, accessible by multiple recipients, although only one recipient can handle each packet.
- Publish-Subscribe: Unlike the point-to-point model, this model lets data packets make their way to areas of interest, not lines. Multiple recipients can subscribe to a particular area of interest, thus receiving all packets sent to that area. This setup is typically used when the requirement is to broadcast a message to several recipients at the same time.
Importance of Protocols
To assure reliable and efficient communication, messaging solutions use a variety of protocols. Some of the most commonly adopted ones include AMQP (Advanced Message Queuing Protocol), MQTT (Message Queuing Telemetry Transport), and STOMP (Simple Text Orientated Messaging Protocol). The choice of a protocol largely depends upon the specific use case as each of them has their own merits and demerits.
The Rise of Data Streaming
With the advent of big data, the scope of messaging solutions has expanded to include data streaming. This technique encourages real-time data processing, unlike the traditional batch-processing. Applications that need instant analytics, such as detecting fraudulent activity or monitoring systems, gain substantially from this methodology.
NATS and Kafka: The New Entrants
The messaging framework recently saw the introduction of NATS and Kafka - innovative solutions that have quickly gained acceptance due to their high performance, scalability, and user-friendly nature. These solutions are adept at dealing with large amounts of data and provide features such as message durability, duplication, and error recovery. Despite having different structures and implementations, in-depth discussions will provide more insights on the specifics of NATS and Kafka.
In conclusion, messaging solutions serve as a mighty component of the contemporary software architecture model. They cement the need for a strong, scalable, and effectual communication network among software applications. As we continue exploring NATS and Kafka, we will uncover how they showcase the philosophies behind messaging solutions and present inventive solutions to current data hurdles.
Dawn of Data Streaming: Rise of NATS and Kafka
The Pivot to Instantaneous Data Handling
Corporations grapple with gargantuan data volumes, requiring immediate analysis for swift business choices. In past years, these entities would gather data over durations, process it cumulatively, and then decode the results. Unfortunately, this approach fell short of offering instantaneous decision-making capabilities.
Data streaming technology, also known as real-time data supervision, provided a solution. It offered uninterrupted, instantaneous handling, and analysis of data influx. The outcome: businesses could strategize promptly, markedly boosting their operations.
The Emergence of NATS and Kafka
Recently, NATS and Kafka ascended as preeminent platforms in the data streaming sphere, celebrated for their unparalleled features.
Derek Collison birthed NATS, standing for Neural Autonomic Transport System, in 2010. It quickly gained momentum as a clear-cut, high-efficiency message transport mechanism. The platform's pared-down design and smooth implementation explain its popularity among corporations.
LinkedIn introduced Kafka in 2011 as an exclusive platform for managing instantaneous data streams. The platform earned acclaim for its hardiness and scalability, making it a top choice for managing considerable data tasks.
Pitting NATS Against Kafka
Even though both NATS and Kafka participate in data streaming, their properties and abilities place them in different ranks. Here's an evaluation:
NATS & Kafka: Explore Their Growing Influence
The rising need for instantaneous data handling has boosted the popularity of both NATS and Kafka.
Equipped with simplicity and high-level performance, NATS is a preferred choice in the Internet of Things (IoT) and microservices domains. Its modest style enables effortless implementation and regulation, making it a perfect fit for companies with limited resources.
On the other hand, Kafka's robustness and scalability make it the top choice for log structuring and handling instantaneous data streams. Its ability to manage a large quantity of data with minimal lag designates it as a valuable tool for corporations reliant on real-time data decoding.
To conclude, the stronghold of data streaming has prompted the rise of numerous instantaneous data platforms. NATS and Kafka have emerged as favorites due to their distinct features and capabilities. Unless there are dramatic changes in upcoming demands, these platforms' standing will likely rise in tandem with the increasing need for instantaneous data decoding.
Kafka Uncovered: A Close Look at its Architecture
Unlike conventional digital broadcast systems, Kafka originated at LinkedIn, the colossal tech corporation, before finding a nest in the Apache Software Foundation. Its claim to fame lies in its prowess to channel streaming information live, merging different aspects of allied, storage, and messaging systems.

Expounding on Kafka's Fundamental Components
Kafka conceals several key elements beneath its facade, each contributing a unique dimension to its overall performance.
- Data Initiators: They are seen as the launchpad where Kafka's data is generated. Data Initiators send out bunches of data, each tagged with a unique identifier, a value, and a timestamp into the data processors, referred to as brokers.
- Data Negotiators: As the driving force of Kafka, Data Negotiators interact with data records, receiving them from Data Initiators and altering them for later use.
- Data Collectors: Donning the hats of recipients in Kafka, Data Collectors extract data from Data Negotiators, connecting to single or multiple identified classifications to solicit data records.
- Identified Classifications: Playing the role of organizers, Identified classifications streamline transmission of records. Each record in a Kafka cluster corresponds with a particular identified classification.
- Data Subsets: To attain scalability, each identified classification inside Kafka breaks down into smaller parts, dubbed as Data Subsets. These parts are distributed equitably across various Data Negotiators.
Kafka's Mastery in a Structure of Server Systems
Kafka excels in managing operations distributed over a structure of server systems, pictured as specific nodes within the Kafka ecosystem. This distribution ability lets Kafka handle bulk data and rapid data exchange seamlessly. Kafka's framework is designed to ensure data availability across multiple servers, despite any individual server breakdown - showcasing its robust replicated segmenting system.
Kafka's Strategy in Disk Space Allocation
An interesting highlight is Kafka's method of data storage. Kafka employs a reliable log-ahead storage protocol, whereby every piece of data is promptly provided a place in the storage disk, poised for the Data Collectors, guaranteeing steadfast performance and instant data retrieval.
Kafka's Protocol for Data Transfer
Designed for optimum speed and minimum lag, Kafka's interface safeguards smooth data transportation. Data Initiators transmit records to Data Negotiators which remain in storage until Data Collectors access them. Their usage pattern is keenly monitored using the offset - the precise position of the record within its Data Subset.
Data Record Management in Kafka
Kafka's extensive functionalities also encompass real-time editing of streaming records, realized through its Streams API. This feature allows prompt modification of data record streams.
In conclusion, Kafka epitomizes a hybrid mix of allied, storage, and messaging systems, designed for impeccable handling of live streaming data. Its core elements - Data Initiators, Data Negotiators, Data Collectors, Identified classifications, and Data Subsets all synergize for top performance. Its distribution capability, combined with a solid disk storage system and efficient data transfer protocol, enables managing heavy data load and quick data transmission. Additionally, the stream processing feature allows for immediate data transformations, truly portraying Kafka's expertise.
A Deep Dive into NATS: Annotated Architecture
Neural Autonomic Transport System (NATS) stands as a robust message processing solution, distinguished by its simplicity, security, and expandability attributes. Delivering a light footprint and easy deployment, it ideally aligns with deployments such as cloud-based applications, Internet of Things (IoT) devices, and microservices configurations. This segment unravels the intricacies of NATS structure, offering an insightful review of its integral parts and their interplay.

Breakdown of NATS Principal Elements
The central structure of NATS is primarily comprised of three vital elements: the server, the client, and the communication component. We'll dive into the specifics of these components below:
- Server: Acting as the pivotal component, the NATS server regulates client connections, routes exchanges between components, and supervises the overall status of the platform. It can operate independently for simple functionalities or within a networked mode for maximum availability and resilience.
- Client: Operating as the communication component, the client transmits and acquires messages. Client elements engage with the server through a TCP link and use the NATS communication protocol. The client software package delivers APIs for information dissemination, subject subscription, and incoming message processing.
- Communication Component: This forms the transported data exchanged between clients. Each piece of data comprises a subject, representing the message's central theme, and a payload, containing the transmitted details.
Communication Pattern in NATS
NATS employs a pub-sub(integration pattern mode of communication. Here, clients transmit data to specific subjects, and other clients register for these subjects to acquire the data. This configuration fosters an environment that separates producers from consumers, thereby allowing for a scalable and adaptable system blueprint.
- Dissemination: When a client disseminates information, it dictates the subject and payload details. The server then directs the message to all subscribed users of a particular subject.
- Registration: A client signifies interest in a subject by transmitting a request to the server. The server maintains a record of all subscriptions, ensuring each data set reaches the correct client base.
- Routing: A topic-based routing method is applied in NATS. The hierarchical subjects, separated by periods, allow for a detailed and adaptable routing system.
NATS Communication Protocol
NATS uses a straight forward, text-based protocol easily implementable and comprehensible. Defined command sets like CONNECT, PUB, SUB, and MSG are utilized by clients for interactions with the server. It also features additional support like encrypted TLS/SSL communication links, authentication, and authorization.
Performance Indicators in NATS
NATS architecture facilitates high-speed processing and minimal latency. A singular, non-blocking design operates based on event-driven architecture, ensuring efficient throughput and low latency times. Thus, it can manage millions of messages within seconds, with a sub-millisecond latency that meets real-time application needs.
Secure Measures in NATS
NATS is equipped with robust security parameters to safeguard your platform. These encompass TLS/SSL encryption for secure connectivity, authentication via username/password or tokens, and access control using Access Control Lists (ACLs).
In summary, NATS exemplifies an impressive messaging platform, lauded for its simplicity, efficacy, and elasticity in architecture. Its lean design and robust performance make it apt for contemporary, distributed systems. In our subsequent segment, we'll delineate the strengths and benefits of Kafka, a competing messaging platform.
Scoring With Kafka: Advantages and Strengths
Undeniably, in the domain of information technology, Apache Kafka has impressed with its fresh and advanced methodology, expedited manipulation of continuous data. This article provides a detailed analysis of the singular characteristics of Apache Kafka that have instigated its extensive adoption by worldwide companies.
Superlative Data Transportation Velocity and Tailored Augmentation
At the core of Kafka's benefits is its unparalleled ability to administer vast data reserves with immense swiftness. Given its competence to tackle an inundation of messages at immense pace, Kafka is highly sought after by institutions grappling with high-speed, real-time data computation tasks.
Kafka's scalability is exceptionally flexible and allows for effortless augmentation. Additional nodes can be smoothly linked to its cluster to amplify its competence – an ideal remedy for companies contending with inconsistent data traffic and in search of a pliable solution.
Peerless Robustness and Trustworthy Data Durability
Kafka's split design enhances its robustness. Crafted ingeniously to operate seamlessly despite a malfunctioning unit in its cluster, Kafka guarantees zero data loss. Kafka's unique replication facility copies each message to several units, ensuring constant data availability.
By leveraging disk storage, Kafka preserves data permanently. This inherent protective functionality keeps data undamaged and accessible, even post-system recovery, thereby guaranteeing operational continuity.
Real-Time Data Handling
A standout feature among Kafka’s contemporaries is its expertise in instantaneous data manipulation. This skill leads to sped-up data scrutiny and rapid decision-making based on the most recent data streams—a boon for applications that necessitate real-time utilisation of newly collated, relevant data.
Harmonious Integration
The interoperability of Apache Kafka spans numerous platforms and applications. Its abundant API offerings and versatile client libraries pave the way for seamless amalgamation with diverse databases, avant-garde microservices, or intricate data processing frameworks like Hadoop and Spark.
Data Flow Optimization
Kafka's skill set extends beyond mere message transmission acceleration; it also enhances data flows. Utilising Kafka Streams, companies can carry out complicated alterations on their in-flight data, such as reformatting, screening, and consolidating, almost immediately.
Staunch Data Security Measures
Apache Kafka enforces stringent data security protocols, encompassing authentication, authorization, and encryption. These safeguards fend off unauthorised data infiltration and assure safe data relay across networks.
In conclusion, Apache Kafka's defining attributes such as exceptional speed, tailored enlargement, unmatched robustness, real-time data interaction, integration proficiency, stream enhancement, and firm data administration principles form its underpinning, positioning it as a solid ally for corporations looking to optimise their handling of continuous data.
Winning Points of NATS: Benefits Under the Microscope
The tech sphere is increasingly paying attention to NATS, a no-cost communication system that stands out with its distinguishing characteristics and perks. This discourse highlights the ‘why’ of NATS, dissecting its boons meticulously.
Unfussy Operation & User-Friendliness
Foremost among NATS' merits is its uncluttered operation. Its design is unsophisticated with a user-friendly API, making it a breeze to fathom and employ. Unlike its counterparts, which necessitate perplexing setup and customisation, NATS can be operational promptly. Client libraries available in languages such as Go, Java, and Python add to this hassle-free usage.
Stellar Efficiency & Expandability
Designed to excel in efficiency and expandability, NATS has the capacity to process a multitude of messages each second, rendering it fit for systems with high data traffic. Its publish-subscribe framework allows it to extend effortlessly as more publishers or subscribers arrive. Thus, for expansive systems that hinge on scalability, NATS is an optimal selection.
Сompact yet Resourceful
Despite being a compact communication system, NATS consumes fewer resources, becoming a boon in environments where resources are restricted, such as IoT systems. However, it doesn't skimp on performance, thanks to its effective protocol that curbs network bandwidth usage.
Robustness & Demonstrated Fault Resistance
Designed with robustness and distributed architecture, NATS wards off the risk of a single point of failure. In a server failure scenario, clients can seamlessly reconnect to an alternate server, thus ensuring uninterrupted operation. NATS's clustering support further bolsters its fault-resistance.
Secure Operation
NATS safeguards the communication via its robust security features including TLS for encryption and ACLs for fine-grained access limitations. Furthermore, it offers token-based identification, adding another layer to its security.
Dynamic Community & Expanding Ecosystem
NATS is backed by its dynamic community and an expanding ecosystem of resources. There's an array of client libraries, utilities and integration options to merge NATS into your technological suite. The lively NATS community, known for its responsiveness, offers valuable support and directions to users.
In a nutshell, NATS offers an irresistible mix of clear-cut operation, peerless performance, and robustness, appealing to a spectrum of applications. Be it the creation of an expansive system, an IoT application or a real-time data analysis platform, NATS reliably delivers.
Kafka vs NATS: Crucial Performance Comparison
When evaluating communication systems, performance plays an integral role in swaying the decision towards one platform or the other. In this text, we juxtapose Kafka and NATS, two prominent industry stalwarts in the message system arena, in terms of performance.
Evaluating the Performance
One cannot assess the performance of a system without indicators. Here, we have:
- Throughput: Referring to the rate at which the system processes messages within a specified timeframe. Higher the throughput, the superior is the performance.
- Latency: Denoting the duration needed for moving a piece of information from its origin to the destination. A rapid transmission manifests as lower latency.
- Scalability: Connoting the system's capacity to manage escalating loads by dedicating additional resources. An effectively scalable system ensures a smooth transmission of a copious volume of messages, maintaining steady performance.
- Durability: Depicting the system's competence in affirming that a dispatched message doesn't disappear, and will ultimately reach the recipient.
Kafka: A High Performer
Kafka, with its reputation for outstanding throughput and reduced latency, is a widely favored option for immediate data handling. It has a segmented arrangement wherein the data gets spread over multiple nodes, facilitating parallel processing of substantial data quantities.
Kafka scores high on durability too. With its feature of a commit log setup, every message is saved onto a disk and duplicated over numerous nodes for fault tolerance, securing the data against node failure.
However, multiple factors, such as the variance in the number of topics and partitions, discrepancies in message size, and the arrangement variations of the brokers and consumers, could affect Kafka's performance. Therefore, precisely tailoring Kafka for maximum performance often turns out to be an intricate process.
NATS: Simple Yet Efficient
NATS shines in its downright simplicity, being lightweight and bestowed with a razor-sharp focus on delivering high speed with lesser complexities. By harnessing an in-memory architecture, wherein the messages are not stored on a disk, it scores high on throughput and latency.
While NATS can efficiently manage millions of messages each second, it falters a bit on durability when pitted against Kafka. If the system encounters a crash, and a message is left undelivered, it gets lost since NATS lacks on-disk message preservation.
Kafka or NATS: The Verdict
The duel between Kafka and NATS reveals that both are talented contenders with their share of virtues and shortcomings. Kafka steals the spotlight when it comes to durability and managing high throughput but may present complexities in configuration and optimization. In contrast, NATS prides itself on its simplicity, stellar performance, and scalability, but falls short in providing a durability assurance comparable to Kafka.
To sum it up, the eventual pick between Kafka and NATS is largely influenced by the intended use. Supposing the top priority is sturdiness and faults-resilience, Kafka fits the bill perfectly. However, if the requirement is for a facile, high-velocity messaging platform with a capacity to absorb some message loss, there isn't a better pick than NATS.
Kafka in Application: Real World Use Cases
In the sphere of data transmission and messaging systems, Kafka has distinguished itself with its sturdy infrastructure, compatibility with large-scale operations, and resilience to failures. Numerous entities in different sectors have incorporated it into their operations because it caters to a broad spectrum of requirements. Below, we explore some of Kafka's applications in real-world scenarios.
Immediate Data Handling
Numerous businesses, including LinkedIn, Uber, and Netflix, harness Kafka's capabilities for swift data handling in real-time. For instance, LinkedIn employs Kafka for real-time tracking of operational metrics and activity data. Uber utilizes it to compile trip information and adjust surge pricing promptly. Netflix leans on Kafka to scrutinize its services and dispatch alerts when irregularities occur.
Log Consolidation
Kafka's application in consolidating logs is widespread. It facilitates businesses in gathering log information from various systems and services at a unified point. This data then serves purposes such as real-time monitoring, analysis, and problem-solving. An example is Twitter, which relies on Kafka for log consolidation, thus enabling real-time supervision of its services and infrastructure.
Data Stream Handling
The domain of data stream handling is another where Kafka excels. Thanks to its capacity to manage immense amounts of real-time data, it's solid choice for this purpose. Pinterest employs Kafka to drive its real-time analytic platform, while The New York Times uses it to store and distribute its enormous article archive for real-time stream handling.
Event Logging
Event logging involves recording state alterations as a series of events, a design pattern that Kafka's log-based structure is naturally suited for. Zalando, for example, uses Kafka to keep an up-to-date inventory of its products. ING, on the other hand, uses Kafka to document every alteration to its customer data for auditing.
Messaging Handler
Kafka can also function as a messaging handler, managing massive quantities of messages and guaranteeing they're processed in order of reception. It powers Airbnb's chat platform, while Spotify uses it to manage real-time data and events.
The table below summarizes Kafka's use cases:
To sum up, the broad array of applications, from immediate data handling to event logging, log consolidation, data stream handling, and message queuing, coupled with Kafka's robustness and adaptability makes it a preferred choice across different industries.
NATS in Action: Influential Use Cases
NATS, an undisputed leader in the messaging system community, has exhibited its prowess in multiple industry sectors and technology environments. Its threefold advantages, namely user-friendliness, outstanding performance and adaptability, position it as an unparalleled choice for a plethora of businesses. Let’s explore the transformative implications of NATS in diverse settings.
NATS: A Prime Choice in the Microservices Ecosystem
Delve into the microservices architectural ethos where the entire setup is divided into distinct services, yet coherently interlaced. NATS doesn't merely fit well here; it's the 'paramount' selection, owing to its condensed structure and rapid information delivery prowess.
An instance of NATS’s remarkable application can be seen in Baidu, the internet titan from China. Baidu leverages NATS as a vital communication junction for over a hundred microservices. This translates to billions of messages zipping through the NATS network every second, thus boosting the operational efficacy of Baidu's vast services.
NATS Facilitating IoT Connectivity
Taking into account the IoT realm, which comprises countless networked devices sharing and obtaining data, NATS excels with its condensed form and immense message handling potential.
For example, consider Ayla Networks, a reputed player in the IoT sector. Ayla strategically utilizes NATS for device connectivity and data distribution. This approach has enabled Ayla to escalate its connectivity to millions of devices, resulting in billions of daily message exchanges. NATS’s impressive throughput and low latency ensure robust and long-lasting IoT communication.
NATS: The Heart of Cloud-based Applications
Applications built to harness the offerings of cloud computing models find an ally in NATS, due to its cloud-compatible features like scalability and robust architecture.
Cloudfoundry, the open-source maestro of cloud application platforms, turns to NATS as its main messaging platform. This setting relies on NATS for fluid communication between various parts, ensuring consistent operations and unparalleled availability.
NATS Shines in Distributed System Domains
In distributed computing, countless computers coordinate their actions through message sharing. Here too, NATS, with its reliable pub-sub model and rapid messaging, emerges as the top choice.
Loggly, a cloud-based log management service trailblazer, is an illustrative example. It employs NATS for log data ingestion, thereby successfully handling enormous amounts of log data in real-time. The exceptional performance and resilience of NATS have significantly elevated Loggly's data-processing capabilities.
In conclusion, NATS’s blend of simplicity, performance and scalability make it a pioneer not just in arenas like microservices and IoT, but also cloud-based applications and distributed systems. Its stellar performances in these fields are a testament to its versatility and ruggedness.
Setting Up Kafka: A Comprehensive DIY Guide
Setting up Apache Kafka can seem like a daunting task, but with the right guidance, it can be a straightforward process. This comprehensive guide will walk you through the steps of setting up Kafka on your local machine, from downloading and installing the software to configuring and running your first Kafka server.
Step 1: Prerequisites
Before you begin, ensure that you have the following prerequisites installed on your machine:
- Java Development Kit (JDK) - Kafka is written in Java and Scala, so you need to have JDK installed on your machine. You can download it from the official Oracle website.
- Zookeeper - Kafka uses Zookeeper to manage and coordinate the Kafka brokers. You can download it from the official Apache website.
Step 2: Download and Install Kafka
Once you have the prerequisites installed, you can proceed to download Kafka. Visit the official Apache Kafka website and download the latest stable release. After downloading, extract the tar file to your preferred location.
Step 3: Start the Zookeeper Server
Before starting the Kafka server, you need to start the Zookeeper server. Navigate to the directory where you extracted Kafka and run the following command:
Step 4: Start the Kafka Server
After starting the Zookeeper server, you can now start the Kafka server. Run the following command:
Step 5: Create a Kafka Topic
Now that the Kafka server is running, you can create a Kafka topic. Run the following command:
Step 6: Test the Setup
To test the setup, you can produce and consume a message using the Kafka console producer and consumer. Run the following command to produce a message:
Then, run the following command to consume the message:
If everything is set up correctly, you should see the message "Hello, Kafka" in the console.
Step 7: Configuring Kafka for Multiple Brokers
While a single Kafka broker can handle a high volume of reads and writes, a Kafka cluster with multiple brokers provides additional benefits such as load balancing and fault tolerance. To configure Kafka for multiple brokers, you need to create additional configuration files for each broker and modify certain properties.
Step 8: Stopping Kafka and Zookeeper
When you're done using Kafka, you can stop the Kafka and Zookeeper servers by running the following commands:
This guide provides a basic setup of Kafka for development purposes. For a production environment, additional configurations such as enabling security features, tuning performance, and setting up monitoring would be necessary.
How to Deploy NATS: A Step-By-Step Manual
Deploying NATS, the robust communication system, can be straightforward when you follow specific steps correctly. This guide is designed to provide a clear pathway for NATS operation without any setbacks.

Step 1: Procuring the Latest NATS Server Version
Your initial move towards operationalizing NATS includes obtaining the most recent NATS server module. NATS' GitHub supply is your ideal destination for this procurement. After the acquisition process, decompress the acquired package and ensure the resulting binary file is shifted to a suitable spot within your system's PATH.
Step 2: Customizing NATS Server Specifications
Determining NATS server settings is your next significant role. A configuration document comes in handy when tailoring server specifications like its port identifier, maximum data body, and an array of record-keeping options.
Below is an example of a basic NATS server configuration document:
This configuration document is created using your preferred text editor and stored at a reachable path.
Step 3: Activating The NATS Server
With the NATS server suitably tuned, it's time to activate the server using the command below:
This command instructs the NATS server to commence its functions, influenced by the preset configuration document.
Step 4: Evaluating The NATS Server Capability
After the NATS server is operational, assessing its capability is necessary. Leverage a NATS client to connect to the server and conduct a test intercommunication. Effectively sending and receiving messages denote the server is in good working condition.
Step 5: Operationalizing NATS Clients
Concluding your NATS operation entails the initiation of NATS clients. NATS clients serve as a bridge between your software and the NATS server, enabling message transactions. These clients can be hatched in a multitude of coding languages such as Go, Java, and Python.
The code snippet below demonstrates the creation of a NATS client using Go:
By following these steps, you'll achieve a seamless NATS operation. Don't forget to continuously verify your NATS server and clients' capabilities to maintain optimum performance.
Fine-Tuning Kafka for Optimal Performance
Maximizing Kafka's efficiency stems from meticulous calibration of its operational parameters and grasping how each element influences overall system efficiency. The subsequent content illustrates the intricacies of enhancing Kafka's output, shedding light on crucial parameters, and illustrating best approaches to their implementation.
Streamlining Kafka Broker
Central to Kafka's operation, the configuration of the Kafka broker largely impacts the system's functionality. Consideration should be given to the following aspects:
- num.network.threads: The number of network processing dedicated threads the broker employs depends on this figure. A commendable initial approximation is setting it equal to the total cores at disposal.
- num.io.threads: The count of threads the broker assigns for I/O tasks. Ideally, this should surpass the available core count slightly.
- socket.send.buffer.bytes and socket.receive.buffer.bytes: These values regulate the dimensions of TCP send/receive buffers. Buffer size escalation can provide superior network functionality, albeit at the expense of broker memory usage.
- log.flush.interval.messages and log.flush.interval.ms: The regularity of log flushes is dictated by these values, with an increase in the values usually boosting output but simultaneously heightening the potential for data loss should broker failure occur.
Enhancing Producer Efficiency
Kafka producers' efficiency is heavily influenced by their settings. The undermentioned parameters warrant attention:
- batch.size: This number delineates how many messages the producer groups together for batch dispatch to the broker. A larger value typically enhances throughput, however, it can negatively impact latency.
- linger.ms: This value specifies the ultimate duration producers can delay for additional messages prior to dispatching a batch. An increase can augment throughput whilst potentially escalating latency.
- buffer.memory: This value designates the producers’ total permissible buffering memory. An increase usually boosts performance but it equally enhances producer memory utilisation.
- compression.type: This parameter establishes the compression type for the producer. Compression reduces necessary network data transfer, therefore boosting throughput but has an impact on CPU usage.
Optimising Consumer Performance
Kafka consumers can also significantly benefit from operational tweaks. Consider the following parameters:
- fetch.min.bytes: This parameter sets the least amount of data a consumer will request in a single query. Greater values generally improve throughput but could potentially weigh down latency.
- fetch.max.wait.ms: This value defines the utmost duration a consumer will defer for data availability preceding a fetch request. Higher values usual enhance throughput at a potential latency cost.
- max.partition.fetch.bytes: This parameter determines the most data a consumer will request within one partition in a single query. Increasing this value could yield a better throughput whilst potentially taxing memory usage.
Amplifying Kafka's efficiency does require an in-depth comprehension of the complex inner workings. Nevertheless, fine adjustments of these pivotal configuration parameters could lead to significant acceleration in Kafka functionality.
Getting the Best Out of NATS: Tips and Tricks
NATS, an open-source messaging system known for its simplicity and impressive performance, has gained traction owing to its minimalistic design and user-friendly interface. Nevertheless, to fully leverage its capabilities and fine-tune its performance, one can apply a set of techniques and methods. This piece will explore these methods, offering you an exhaustive guide to maximize the functionality of NATS.
Comprehending the Fundamental Concepts of NATS
Prior to examining these techniques, it's vital to capture the basic ideologies of NATS. At its core, NATS employs a model of publish-subscribe. Here, 'subjects' entail the messages the system publishes, while 'subscribers' signify those with interest in receiving these messages. This design facilitates swift and direct communication between disparate systems.
Best Practices for NATS Subjects and Subscriptions
NATS prompts 'subjects' as a mode of sorting messages, while subscribers enlist their interest in these subjects to collect applicable messages. To enhance the effectiveness of NATS, strategic application of subjects is vital.
- Organization of Subjects: NATS incorporates a hierarchical subject format. Capitalize on this feature by arranging your subjects in a manner that mirrors the correlation between various sections of your system.
- Compounding Subscriptions: NATS embraces wildcard subscriptions which permits subscription to several subjects simultaneously. This approach can significantly slash the number of subscriptions your application needs to oversee.
- Persistent Subscriptions: For applications necessitating state retention across restarts, NATS accommodates persistent subscriptions. These subscriptions outlive client disconnections, certifying that no messages are gone astray.
Efficient Connection Supervision
Efficient supervision of connections is another crucial tactic towards enhancing NATS' functionality. Here are some guidelines:
- Shared Connections: In preference to fabricating a new connection for each message, employ a shared pool of connections. This strategy can greatly cutback the overhead linked with setting up connections.
- Regulated Connection Closure: NATS facilitates regulated connection closure, which permits a well-ordered shutdown. This confirms that all messages in transit are managed before a connection termination.
Performance Optimization
Though designed for high performance, NATS offers scope for fine-tuning in accordance to specific requirements.
- Grouping: Rather than dispatching messages individually, consider collective dispatch. This can diminish network overhead and augment throughput.
- Payload Scale: The scale of your messages can majorly influence performance. Messages of lesser size are generally quicker, however, for large data volumes, it may be required to amplify the maximum payload scale.
- Parameter Calibration: NATS houses multiple parameters available for performance adjustment, such as the flush interval and the upper limit of pending messages. Experiment with these to locate the most suitable settings for your use case.
Security Measures
NATS embeds TLS for secure communication. It is advisable to utilize TLS in production setups to safeguard your data. Moreover, NATS affords authorization through user credentials or tokens, supplying an added layer of security.
To conclude, while NATS serves as a robust and effective messaging system as is, understanding and implementing these techniques can amplify its performance and utility. Whether it's utilizing subjects and subscriptions, managing connections adeptly, optimizing performance, or considering security aspects, each of these factors is integral in fully capitalizing on the potential of NATS in your application.
Advanced Kafka Concepts: Decoding Consumer Groups, Topics & Partitions
Apache Kafka exemplifies its superiority in distributed computing with its remarkable attributes and unique design that hinges on three fundamental elements: Consumer Aggregations, Data Avenues, and Segmentation. Learning and utilizing these key facets are paramount to exploit Kafka's rich offerings.
Consumer Aggregations: Energizing Concurrent Operations
Within Kafka’s framework, an exclusive feature that stands out is the presence of Consumer Aggregations. These serve as a catalyst for condensing computational tasks. When configuring Kafka, consumer groups are labeled under a specific marker, paving the way for Kafka’s logic to administer a balanced assignment of processing chores across all consumer entities.
Contrasting traditional information distribution modes, Kafka disseminates data not to each separate consumer but rather assigns it to a sole consumer within each aggregation. For example, given a hundred data sequences necessitating attention from an aggregation of ten consumers, each consumer is only responsible for one-tenth of the total data chunk. This smart allotment tactic is Kafka’s strategy to reinforce concurrent operations, hence amplifying the system's overall productivity.
Data Avenues: Constructing Kafka's Interactive Scaffoldings
Data transfer in Kafka is intrinsically centered on Avenues, which provides the organizational footprint. Avenues work as distinct passages for data movement and permits data suppliers to inject their data into these pipelines, which are later accessed by consumers. This design facilitates an unbounded volume of subscriptions to an Avenue, allowing extensive users to tap into the information.
A special characteristic exclusive to Kafka is the retaining of a detailed log of all departing data associated with an Avenue over a specific duration. This attribute lends consumers the luxury of concurrent data access or alterations to their data extraction strategy if called for.
Segmentation: Underlying Kafka's Resilient Expansion
Kafka’s Data Avenues are further divided into one or more Segments, which assist in managing and dispersing massive data loads across various nodes. This in turn bolsters resilience and endows a strong tolerance against failures. To expedite parallel data extraction, each segment can be hosted on a distinct server.
Whenever data is supplied by a producer into a Kafka avenue, it gets associated with a chosen Avenue's Segment. The selection of the segment can be either determined by the producer or reliant on Kafka’s rotation-based algorithm.
Segments play a critical role in Kafka's data protection conventions through duplication. Each segment is extended across several nodes, creating a safety net for data if a node abruptly malfunctions. For each segment, a responsible lead node supervises all data read and write procedures, while the remaining nodes clone data from the head.
Knowledge and utilization of Consumer Aggregations, Data Avenues, and Segments are essential to fully tap into Kafka's vast potential. This understanding lays a robust platform for achieving top-tier data processing speed, extraordinary scalability, and supreme fault resilience.
NATS Advanced Features: Unraveling Subjects, Subscriptions & Queues
NATS stands out in the realm of open-source messaging systems due to its streamlined nature, high-performance metrics, and ability to scale. Its design is lean and implementation-friendly, earning it a preferred status amongst the creators of distributed systems today. We will structure this discourse around the inherent details of NATS, with a focus on the concepts of subjects, subscriptions, and queues.
Subjects and Their Role in NATS
NATS makes use of subjects to classify the informational content it communicates. They practically serve as the "themes" which govern the publication and subscription of messages. The beauty of subjects in NATS lies in its adaptability, you can create them as per the requirements of your software. For example, if one were to develop an app that handles weather forecasting, subjects like "weather.updates" or "weather.alerts" may come about.
Another engaging feature of NATS subjects is the incorporation of wildcard characters. NATS allows for two types of wildcards: the asterisk symbol () and the greater than symbol (>). While the asterisk is fitting for designating a single level in the hierarchy, the greater-than sign can signal numerous. For instance, "weather." would correspond to "weather.updates" and "weather.alerts" yet not "weather.alerts.severe". Conversely, "weather.>" would correspond to all three.
Digitizing Interest with Subscriptions in NATS
Subscriptions in NATS embody the expression of interest in specific subjects or a gamut of subjects by clients. When a client subscribe to a subject, it informs the NATS server of its interest in receiving messages published on that subject.
Subscriptions in NATS, however, aren't durable in their default state. If a client disconnects, the subscriptions dissolve. But fear not, durable subscriptions do exist in NATS. In the case of temporary disconnects, durable subscriptions secure that no messages go missing.
Queue Management in NATS
Another compelling feature of NATS is the support for queue groups, which effectively manage the balancing of messages across various subscribers. When there are multiple subscribers to a subject in a queue group, NATS ensures the message reaches only one subscriber.
Queue groups are instrumental in amping up the scalability of your applications. By adding numerous subscribers to a queue group, the load distribution is equalized and high quantity of messages can be tackled easily.
An illustrative Python code snippet for reference:
In the example above, a client subscribes to 'foo' as a subject and lays out a message handler function to take care of incoming messages. The client bides some time for messages to arrive prior to unsubscribing and draining the connection.
To encapsulate, NATS wields a host of refined features that amp up its robustness as a messaging system. The provision for subjects, subscriptions, and queues paves way for nuanced control over message routing and delivery, making it an ideal candidate for building distributed systems.
Security Features: Kafka vs NATS Face-off
Delving into the field of messaging platforms, it's become evident that safety measures are of the utmost importance. This examination focuses on the safety functions integrated into both NATS and Kafka, aiming to contrast their varying capabilities and constraints.
Kafka's Protective Elements
Apache Kafka employs a series of proactively designed security measures to safeguard the data, whether it is stationary or moving. The integrated features include:
- User Verification: Kafka can confirm the clients' identity using either the Transfer Security Layer (TLS) or Simple Authentication Security Layer (SASL). SASL can be additionally tailored to use procedures such as GSSAPI (Kerberos), SCRAM, or PLAIN.
- Access Controls: Post user verification, Kafka grants finely tuned Access Control Lists (ACLs) to approve client activities. ACLs can be applied to topics, consumer groups, or individuals.
- Data Encapsulation: Kafka employs TLS to cipher data in motion, ensuring unauthorized intruders cannot read this data.
- Usage Limitations: Administrators can give the advantage of usage limits on a per-client foundation to prevent single-handed broker resource control.
Here is a Java sample illustrating how to apply SASL/SCRAM user verification in Kafka:
NATS Safety Functions
Contrarily, NATS extends a more streamlined, but still potent, cluster of security features:
- User Verification: NATS enables token-based and username/password verification. It also extends TLS client certification validation.
- Access Controls: NATS allows permission configurations on a per-user basis, governing which subjects a user can publish or subscribe from.
- Data Encapsulation: Just like Kafka, NATS uses TLS encryption for safeguarding data in motion.
- Nkeys: For improved user verification and management, NATS utilizes a decentralized public key infrastructure with Nkeys, which are unique identifiers.
Below is a basic Go code block on how to apply token-based verification when using NATS:
Security Analysis: Kafka vs NATS
Contrasting the security elements of both Kafka and NATS uncovers that while both are solid, they have different approaches. Kafka's robust and finely-tuned security makes it a good match for large-scale, commercial-grade applications. NATS, with its streamlined procedures and the integration of Nkeys, is an ideal match for lightweight applications where ease of use and management are vital.
In summary, the selection between Kafka and NATS will significantly rely on unique usage requirements and the necessary safety measures. Even though both platforms provide a strong basis for safe messaging, the variations in their complexity and fine granulations can influence the preference towards one or the other.
Community Support and Documentation: Kafka versus NATS
Exploring and comparing the community engagement and resource provisions for both Kafka and NATS technology:
A Look at Kafka's Community Interaction and Resource Provisions
Kafka, a project initiated under the umbrella of the Apache Software Foundation, is open-source in nature and benefits from a bustling global community. This includes active users, contributors, and developers who actively partake in further improving Kafka.
The community centred around Kafka is ever-present on various platforms such as mailing lists, StackOverflow, and GitHub, to name a few. The mailing list plays a pivotal role in facilitating comprehensive discussions, enabling viable proposals, and addressing Kafka-related challenges. StackOverflow becomes a valuable aid to Kafka users as it provides solutions to ambiguous user problems. Lastly, GitHub serves as the ideal place for those who want to stay updated with the latest Kafka code, contribute themselves, or bring any discrepancies to light.
When it comes to resources, Kafka possesses extensive and methodically organized documentation. Ranging from basic user guidance to advanced user information, it fits the needs of novices to seasoned Kafka users alike. Moreover, this documentation is updated in tandem with evolving Kafka enhancements.
NATS’s Community Interaction and Resource Provisions in Analysis
Bearing similarities with Kafka, NATS is also an open-source initiative and features a steadily expanding user and contributor base. This community is constantly engaged on GitHub, contributing to the project, pointing out inconsistencies, and making suggestions to better the operation.
In addition to GitHub, the NATS community has an actively participating Google Group for discussing various subjects and a Slack channel that fosters immediate and direct communication. These platforms offer users opportunities to interact, exchange ideas, and provide mutual assistance.
NATS' resource provisions take the form of well-drafted, user-friendly documentation. This ranges from basic tutorials for new users to intricate guides for sophisticated features. Like Kafka, this documentation also maintains regular updates, enabling users access to the most current and precise information.
Kafka and NATS: A Comparative Study
In analyzing and comparing the community involvement and resource offerings of Kafka and NATS, both seem to show hustling communities and well-rounded resources. However, there is a slight skew towards Kafka, which may be attributed to its longstanding establishment and broader use.
In resource evaluation, both Kafka and NATS possess detailed and updated knowledge repositories. However, some users might consider Kafka's resources more challenging to grasp owing to the intricate nature of its functionality.
In essence, both Kafka and NATS boast a robust community and well-maintained resources. Choosing between the two will depend on the specific requirements and inclinations of the user.
Tooling and Ecosystem: Evaluation and Comparison
When it comes to choosing a messaging system, the tooling and ecosystem surrounding the technology can significantly impact its usability and effectiveness. In this chapter, we will delve into the tooling and ecosystem of both NATS and Kafka, evaluating and comparing their features to provide a comprehensive understanding of their capabilities.
Kafka Tooling and Ecosystem
Apache Kafka boasts a rich ecosystem that includes a variety of tools and integrations, making it a versatile choice for many organizations.
- Kafka Connect: This is a tool for streaming data between Apache Kafka and other data systems in a scalable and reliable manner. It makes it easy to import data from external systems into Kafka topics and export Kafka topic data to external systems.
- Kafka Streams: This is a client library for building applications and microservices, where the input and output data are stored in Kafka clusters. It combines the simplicity of writing and deploying standard Java and Scala applications on the client side with the benefits of Kafka's server-side cluster technology.
- KSQL: This is a SQL interface for processing data in Kafka. It provides an easy-to-use, yet powerful interactive SQL interface for stream processing on Kafka, without the need to write code in a programming language such as Java or Python.
- Confluent Schema Registry: This tool provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving Avro schemas. It stores a versioned history of all schemas, provides multiple compatibility settings and allows evolution of schemas according to the configured compatibility setting and expanded Avro support.
NATS Tooling and Ecosystem
NATS, on the other hand, is a simpler technology with a leaner ecosystem. However, it still offers a set of tools that can be highly effective for certain use cases.
- NATS Streaming: This is a data streaming system powered by NATS, and it embeds, extends, and interoperates seamlessly with the core NATS platform. It features at-least-once message delivery, message replay by timestamp or sequence, durable subscriptions, and fault tolerance.
- NATS Connector Framework: This framework allows you to bridge NATS with other technologies. It provides a simple way to create connectors that transfer data between NATS and other technologies such as databases, message queues, and APIs.
- NATS Operator: This is a Kubernetes operator for NATS, which automates the deployment and management of NATS clusters on Kubernetes.
In conclusion, while Kafka offers a more extensive tooling and ecosystem, NATS provides a simpler and leaner set of tools that can be highly effective for certain use cases. The choice between the two will depend on the specific requirements of your project.
Future Trends: NATS and Kafka Posed for Future Streaming
The Revolution in Data Stewardship: Spotlight on NATS and Kafka
The progression of data governance distinctly unfolds under the impact of NATS and Kafka. The burgeoning fascination with immediate data analysis within several industry clusters - such as financial services, health provision, online trading, and the expansive territory of IoT, has reinforced the pivotal roles of these two platforms.
NATS: Reinventing Effectiveness with High-Speed Performance
NATS, renowned for its sleek and dynamic layout, is custom-built to satisfy the evolving requirements of IoT devices and microservices orchestration. Its straightforward operation appeals to developers seeking an intuitive, manageable communication solution.
Boosting IoT Interaction with NATS
The escalating IoT devices population prompts the necessity for rapid communication. NATS addresses this need impeccably, accentuating its skill with a productive PubSub tactic resulting in diminished latency. It is feasible to anticipate extensive utilization of NATS within IoT service provision, concentrating on device interaction and fast-paced data interpretation.
NATS: A Competitive Edge for Microservices
Within a microservice architecture, the seamless and accelerated communication offered by NATS is unmatched. As corporations increasingly adopt this architectural style, the use of NATS is expected to surge.
Kafka: The Data Management and Real-time Analysis Champion
On the other hand, Kafka is wired to robustly handle exhaustive data management and stream assessment. Its competence in processing enormous data sets immediately positions it as a top choice for applications grappling with substantial data burdens.
Broadening Data Stewardship Scope with Kafka
Given the increasing complexity and speed of data, Kafka's ability to swiftly process data becomes invaluable. Kafka's robust framework, endorsing distributed processing and assuring fault immunity, is well-equipped to master big data's obstacles.
Empowering Real-time Analysis with Kafka
Kafka stands out in the field of stream processing. With its aptness in managing sudden surges of data, Kafka emerges as a potent instrument for immediate analysis in situations such as fraud moderation and prompt recommendations.
NATS vs Kafka: Anticipated Proclivities
In conclusion, both NATS and Kafka possess exciting growth prospects concerning data stewardship. The choice between them essentially depends on the particular applications and prerequisites. For streamlined applications like IoT and microservices, NATS excels with its ease of use and quickness. Conversely, Kafka's robust make and high data managing capacity makes it the default selection for extensive data management and real-time analysis tasks.
Final Verdict: Why You Should Choose NATS or Kafka?
In the domain of data flow and communication systems, the decision to utilize NATS or Kafka might be complex. Their individual merits and demerits could influence your decision based on your specific project nature, accessible resources, and techno-functional needs.
NATS: Emphasizing Essentiality and Efficiency
One could appreciate the elegance and efficiency of NATS. A lightweight tool, it's a breeze to implement and demands minimalistic setup steps. Hence, it fits like a glove for relatively smaller or medium-scale projects where the extensive architecture of a system like Kafka is unnecessary.
In sheer efficiency, NATS outshines its competitors. Crafted to manage a large number of messages in fractions of a second, it's a perfect fit for apps requiring real-time data. Additionally, with its dual support for broadcast-subscribe and inquiry-response communication models, NATS grants you versatility in application design.
Nevertheless, NATS isn't flawless. It falls short in offering several sophisticated attributes like Kafka such as log concentration or message reiteration. Moreover, NATS doesn't come built-in with data tenacity support, a crucial component for some projects.
Kafka: Powering Up with Scalability and Robustness
Kafka is undeniably a dominant force when it boils down to scalability and toughness. Constructed to manage copious amounts of data, it integrates native support for data copies and defect resistance, marking it an optimal choice for grand, critical assignments.
Furthermore, Kafka is a treasure trove of rich attributes like log compression, message repetition and customer pools. These utilities can be crucial for intricate projects necessitating fine-tuned control over message delivery and handling.
Although, superb features of Kafka aren't free from shortcomings. Kafka's deployment and management could seem more complicated compared to NATS, stretching the required resources. While Kafka can manage a ton of data, it might not deliver the quick response expected with NATS during lighter workloads.
Comparative Distinctions
In retrospect, your choice of NATS or Kafka will hinge on your exclusive necessities. For projects valuing uncomplicated design and swift performance, lacking advanced options and data preservation, NATS can be your ally. However, if massive data management and complex features along with robustness are your priority, Kafka is worth considering. It's always beneficial to conduct a comprehensive evaluation of both systems within your specific user scenario to arrive at an informed decision.
FAQ
Subscribe for the latest news

































.jpeg)


