Cloud Events vs Apache Kafka Event Driven Architectures

Introduction to Event-Driven Architectures
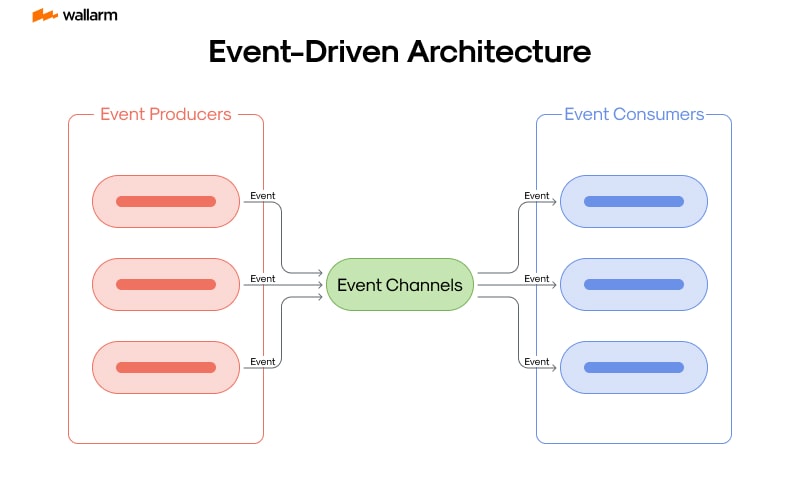
Within the expansive universe of coding and software creation, the weight and sway of the Event-Driven Architectures (EDA) model are undeniable. An EDA blueprint is tailored to activate swift business reactions, hence morphing the digital tableau into a dynamic and forward-thinking platform. The central ethos of EDA amalgamates around four major pillars: the genesis of events, their identification, governance, and response.
Deciphering the Importance of Events
Dialogues touching on EDA often allude to 'events,' which signify a critical shift in existing conditions. Visualize a client obtaining an item from an online commerce site. This run-of-the-mill act of purchase ignites a series of automated sequences, involving inventory updates, customer acknowledgement, and the initiation of the delivery flow.
Deep-diving into events, they can be perceived as fixed data particles that unveil the necessary shifts in the prevalent state of affairs. Such events can originate from user engagement, an alert from a device sensor, or software operation mechanisms. Consequently, these events are detected by the event controllers, which could be a proactive application or service responding to the event change.
Key Theories Bolstering Event-Driven Architectures
EDA predominantly rests on two pivotal tenets:
- Event Producers and Controllers: The abstract skeleton of EDA supports role bifurcation. Central elements choreographed for event generation operate autonomously from those who manage these events. This arrangement facilitates both factions to execute their duties without trespassing each other’s functions.
- Event Trajectories: Each event embarks on a distinctive journey, ranging from its origin to the destined receiver. This voyage might be dictated by specific dispatch rules such as one-time dispatch, guaranteed delivery, or exact-once shipment.
- Event Outcomes: The trajectory that an event follows upon reception can lead to several endpoints. Starting from instant handling to complex sequencing (where the event waits for the completion of related events) or event chain steersmanship (where a series of events are supervised), the prospective outcomes are varied.
Advantages Unleashed by Event-Driven Architectures
Adopting EDA unchains numerous perks:
- Scalability: By endorsing the individual operations of event pioneers and managers, EDA cultivates scalable expansion.
- Stability: Considering that one manager's failure doesn’t impact event originators or other managers, EDA amplifies systems' resilience.
- Swift Adaptations: By applying real-time event oversight, EDA empowers organizations to swiftly conform and advance.
- Flexibility: With a plethora of event administration methods, EDA ensures versatility, servicing a wide array of functional needs.
Illuminating Event-Driven Architectures
Impressions of EDA applications are scattered across many industries. Take the IoT sphere, where gadgets produce events that are dealt with simultaneously. In the microservices realm, different services communicate via events, whereas in stream handling, a ceaseless cascade of events is guided.
As we proceed, our attention will steer towards Apache Kafka and Cloud Events - two formidable technologies that fortify EDA. We'll delve into their operational tactics, uniqueness, contrast, and comprehend their contribution to structuring robust event-based frameworks.
Understanding Apache Kafka and its relevance
Revealing the Shift in Event-Driven Frameworks: Apache Kafka's Influence
Event-focused platforms have undergone a drastic evolution with the arrival of Apache Kafka. Initially created by LinkedIn, this potent software was later inducted into the Apache Software Foundation to redefine itself as a multifunctional, openly available solution. Kafka's standout feature is its resilient and efficient handling of immediate data interactions. It distinguishes itself through its capacity to navigate and securely ensnare substantial cascades of data, placing it as a fundamental aspect of processes that involve on-the-spot data analysis, log accumulation, and event activation.
Decoding Apache Kafka: The Essential Pieces
Certain components characterise Apache Kafka, enhancing its efficacy and boosting its process performance:
- Data Suppliers: Often termed 'producers', these elements can be individuals or systems providing key-value pair data to Kafka.
- Message Conducts: Known as 'topics' in Kafka's terminology, these serve as conduits for data transmissions. Allocating distinct topics to specific servers escalates horizontal scalability.
- Data Processors: These modules are responsible for retrieving the data from the conduits through segmented sections.
- Transit Stations: The architectural layout of Kafka incorporates numerous servers, dubbed as 'brokers', competent in suppoting a voluminous influx of messages without performance degradation.
- System Guardian: Aptly named 'ZooKeeper', this service ensures constant supervision of Kafka's brokers, oversees network conditions, and maintains a reservoir of messages for quick recovery processes.
Valuable Contributions of Apache Kafka
In an ecosystem significantly driven by data-centric methodologies, one cannot disregard the significance of Apache Kafka. Structures harnessing spontaneous data streams substantially utilize Kafka for speedy computational data analysis, highlighting its pivotal role. Several aspects culminate in Kafka's escalating prominence:
- Speed: Kafka's capacity to tackle a myriad of immediate messages every second makes it a competent instrument for detailed event appraisal.
- Reliability: The sturdy composition of Kafka, encompassing data replication across multiple nodes, guarantees intact data preservation.
- Longevity: Kafka employs an aggregate commitment log to swiftly store data on disk and provide inter-cluster replication, considerably augmenting its long-term resilience.
- Scalability: Kafka's structural arrangement encourages horizontal scalability, proving its ability to manage escalating data volume.
- Immediacy in Operations: Kafka's architectural scheme enables swift data management and nearly real-time message dispatch.
- Flexible Integration: Kafka seamlessly amalgamates with numerous streaming applications, such as Spark, Hadoop, and Storm, enabling swift manipulation and control of instant data.
In essence, Apache Kafka excels in processing vast volumes of immediate data in a distributed and trustworthy fashion. Its capability to process data in virtually real-time, coupled with inherent longevity and scalability, makes it an apt solution for entities grappling with hefty data processing needs.
Deep Dive into Cloud Events: An Overview
CloudEvents, the brainchild of the esteemed Cloud Native Computing Foundation (CNCF), have revitalized the arrangement and handling of cloud phenomena by offering a streamlined model for cataloging event-driven data. This innovation is a milestone, serving as a conduit for seamless coordination among intricate systems and instruments, thereby providing software developers with a savvy mechanism for the adept management and protection of cloud-native programs.
Dissecting the Essence of CloudEvents
Enriched by its base elements, CloudEvents excels in settings driven by events, as follows:
- Event: The term is synonymous with noteworthy alterations in the system that can establish a dialogue among programs. CloudEvents recognizes these happenings via the integration of new key-value involvements.
- Producer: This is the architect that crafts and triggers the event. In essence, it's the inception point of the event formulation process.
- Consumer: This element processes the event's purpose and orchestrates associated actions guided by the internal characteristics of the event. All events invariably conclude their journey here.
- Event Data: This delineates the integral features and particulars associated with changes in the primary system.
- Event Attributes: Additionally, supplementary details about the event like source, classification, and timestamp are encapsulated under this term.
Decrypting the Framework of a CloudEvent
At its core, a CloudEvent is crafted using unique key-value mappings where each key operates as a fingerprint, labeling an attribute's moniker. The corresponding value synchronizes with the requisite JSON data. Examine the structure of this CloudEvent instance
Attributes such as specversion, type, source, subject, id, and time are indispensable. The attribute data conceals the heart of the event, while datacontenttype classifies the integrated data.
Traversing CloudEvents Transport Bindings
Several protocols co-operate with CloudEvents, including the likes of HTTP, AMQP, MQTT, NATS, and Kafka for spreading events. Transport bindings sketch out the process of transmogrifying the event attributes and associated information into independent components of corresponding protocols.
In a narrative involving HTTP transport binding, event attributes are metamorphosed into HTTP header values, on the other hand, event data shapes the HTTP body. Here's an example of an HTTP-governed CloudEvent:
Why CloudEvents Matter?
CloudEvents offer a number of benefits: with its innovative perspective for event delineation, it makes synchronization among diverse systems seemingly effortless. Its wide-ranging protocol flexibility confirms its readiness to adapt to any transport approach functioning with key-value symbiosis. The flexibility and standardization offered by CloudEvents for detecting and dispatching events among copious tools make the task of establishing event-triggered structures straightforward.
Apache Kafka vs Cloud Events: What sets them apart
Fine-Tuning Data Flux: Deciphering Apache Kafka's Trajectory
Emerging from the intense demand to manage massive real-time data flux, Apache Kafka redefines the boundaries of data processing. It's not just about controlling the data, it's about doing so with a lightning-fast approach. It prides itself on spectacular throughput and ultra-minimal delay, earning it accolades for managing large-scale, instantaneous data.
Its potency stems from a firm framework often referred to as 'publish-subscribe'. Here, originators broadcast events to niches, and subsequently, these niches metamorphose into a treasure trove of occurrences for users. This interaction ensures autonomy for data pathways and highlights Kafka's suitability for complex, interlinked networks.
Interestingly, Kafka isn't just a courier transporting events from originators to users. It also assumes the role of a chronometer, recalling events for a set duration - an integral feature for data analytics and system problem fixing.
Trailblazing Standardization: The Influence of Cloud Events
Regardless of examining it from a distance or scrutinizing it closely, Cloud Events deviate from the traditional data flux paradigm. The brainchild of the Cloud Native Computing Foundation (CNCF), Cloud Events focuses on devising an indigenous dialect for event data. However, there's more to it. It also facilitates fluent dialogues between diverse services, implementations, and infrastructures.
At the heart of Cloud Events lies a repository of metadata that elaborately narrates the biography of an occurrence. It envelops everything from inception point and category to identification and raw data, thereby simplifying event administration.
Nonetheless, don't anticipate discovering streaming features within Cloud Events' toolkit. It doesn't incorporate them. Instead, it enables its execution with any event-responsive platform while instituting a standard event prototype.
An In-Depth Examination: Attributes Decomposition
Apache Kafka and Cloud Events, both crucial gears of event-driven programming, contrast considerably in their aim and features. Kafka, wielding its superior throughput, negligible delay, and event recollection prowess, conquers the event streaming world. Conversely, Cloud Events contrives a standardized dialect for illustrating event data while ensuring adaptability across diverse networks.
As we move forward, we'll explore deeper into the Kafka infrastructure, Cloud Events' standardization outline, and comprehend their mechanics. Additionally, we'll explain their strategies for event management, their ties with event-driven programming, and input towards data processing.
The Architectural Components of Apache Kafka

Apache Kafka, a potent and open-source tool, tends to be overlooked despite its proficiency in managing big data loads designed for real-time applications. Let’s probe into its critical elements:
Server Director: Kafka’s Control Nexus
Envision Kafka's Control Nexus operating as the command center, astutely synchronizing a plethora of servers, fondly called 'Kafka delegates'. These delegates, functioning as a solid framework, supervise countless messages every second, assuring seamless data transition instantly.
Data Tagging: Kafka Narratives
The resilience of Kafka is amplified through 'narratives' associated with each data input. The revolutionary capacity of the Kafka subscription model enables multiple users simultaneous access to the same narrative. To streamline data movement, these narratives are partitioned into smaller segments, referred to as 'divisions'.
Data Senders: Kafka Creators
Playing a significant role, Kafka Creators channel data toward specific Kafka narratives. The Creators recognize the correct division for individual data points, guided by strategic distribution methods or a semantic division protocol for targeted attribution.
Data Handlers: Kafka Consumers
Kafka Consumers extract data from selected Kafka narratives. They engage with various narratives and pull entries from respective delegates. Each Consumer is part of a Consumer group, ensuring unique data distribution to each member within that group.
Load Stabilizers: Kafka Delegates
Within the Kafka Control Nexus, sundry delegates hold an immense role in load balancing. Leveraging their stateless characteristics, they are heavily dependent on The Supervisor—an advanced delegate manager. A single Kafka delegate can support extensive read/write requests every second, housing large message volumes without affecting performance.
Traffic Supervisor: The Supervisor
The Supervisor, a network master, directs interactions between Kafka delegates and Consumers. It efficiently monitors the delegate assembly, chooses sector chiefs, maintains records of narratives and divisions.
System Bridge: Kafka Connector
This exclusive Apache feature, acting as a conduit, links Kafka with varied systems, including databases or file systems. The Kafka Connector facilitates an easy connector setup process, encouraging the effortless transition of substantial data volumes between Kafka and alternative platforms.
Data Investigator: Kafka Tributaries
This comprehensive client library is fashioned for data manipulation and analysis of data within Kafka. By leveraging inherent Kafka creator and Consumer APIs, it provides a robust stream processing language for operations such as data transformations, data aggregations, and live data merging.
In a nutshell, Kafka's integrated ecosystem offers strong, dependable, and proficient data processing prowess. The harmonized cooperation of these elements establishes a fortified, secure platform for managing and sharing real-time data. Hence, a thorough understanding of these components can substantially improve Kafka's functionality and execution within event-responsive systems.
Thorough exploration of Cloud Events Design
CloudEvents constitutes a blueprint for representing event data uniformly, designed to facilitate the exchange of information across diverse services and platforms. It has been developed around the fundamentals of event-driven structures, where program flow hinges on occurrences like user activities, sensor feedback, or software communications.
Crucial Elements of CloudEvents
CloudEvent's blueprint outlines a collection of attributes that persist across all events, irrespective of their origin or destination points. These encompass:
- Event ID: This is the unique event code.
- Source: The circumstances surrounding the event manifestation.
- Specversion: The specific CloudEvents blueprint version the event identifies with.
- Type: Classification of the event (Example: "com.example.someevent").
- Datacontenttype: Classification of the event's data.
- Dataschema: The blueprint for the event data.
- Subject: The specific subject within the context of the event source.
- Time: The specific timestamp of the event's occurrence.
These attributes offer a uniform method to characterize an event and its encompassing data, thereby fostering synergies across multiple services, platforms, and systems.
Diverse Event Formats and Protocols
CloudEvents accommodates various event formats such as JSON and Avro, along with a spectrum of transport protocols like HTTP, MQTT, and AMQP. This versatility enables the utilization of CloudEvents in a myriad of contexts, extending from straightforward webhooks to intricate event-driven structures.
Consider an event, encapsulated as a JSON object, being transmitted via HTTP:
Harmonization Potential and Expandability
A vital objective of CloudEvents is to facilitate harmony across diverse services, systems, and platforms. By supplying a uniform event description method, it enables varying systems to understand and manage events, even if they were not initially developed to interact.
Beyond the core attributes, CloudEvents also provides for extensions, permitting the introduction of extra metadata beyond the scope of the core attributes. This expandability extends CloudEvent's applicability to a broad spectrum of circumstances.
CloudEvents' Contribution to Event-Driven Structures
Within event-driven structures, occurrences serve as the primary communication medium. CloudEvents offers a standardized event description method, promoting efficient communication irrespective of component-specific implementation conditions or operating platforms.
Employing CloudEvents, developers can shift their focus on their applications' logic as opposed to intricate details of event encapsulation and transport. This approach creates the potential for the development of resilient, expandable, and easy to maintain systems.
In conclusion, CloudEvents hinges on the requirements specific to event-driven structures. Its key attributes offer a uniform method to characterize events, flexibility owing to its support for diverse formats and protocols, and a focus on harmonization and expandability accommodating a wide variety of scenarios.
In-depth Analysis: Event Processing in Kafka
Apache Kafka's prowess in handling large scale data is powered by its unique system of managing events. This structure acts as the lifeblood of Kafka's framework, offering seamless data operations while serving up real-time data insights. Let's dig into the functioning of event organization within Kafka.
Event Control in Apache Kafka
At its core, Kafka utilizes the tenants of the PUBSUB (Publish-Subscribe) model. In this setup, "producers" in Kafka create events that are stored in designated Kafka topics. Now, these "consumers" tap into these topics to access these events. The storage at work is a distributed log service that's divided among multiple hardware or virtual nodes, providing unparalleled data rate and redundancy.
In the case of Kafka, managing events hinges on stream processing. Kafka observes a steady influx of records as a systematic, recurring, and stable data stream. This interpretation allows Kafka to manage active data streams with an almost instantaneous response time.
Event Management Cycle in Kafka
The classical event management cycle in Kafka can be split into four sequential stages:
- Source Event Creation: In the first step, an event source generates and transmits an event to a Kafka broker. The event encapsulates a key, value, and timestamp.
- Storing the Event: Here, the broker stores the event in a topic partition where it's added to the partition's end.
- Consuming the Event: This is where the consumer accesses the event from the partition to process it. Doing so keeps the unique position of the event within the partition.
- Acknowledging the Event: Post-processing, the consumer documents its offset – a critical aspect towards building a fault-tolerant system. In the event of a consumer breakdown, this documented offset acts as the recovery point.
Event Management with Kafka Streams
Kafka Streams is a custom library built to aid in building apps and microservices that modify data stored in Kafka. It offers a top-of-class stream processing DSL (domain-specific language). This lets developers manifest complex computations as a series of data stream alterations.
The operations supported by Kafka Streams include:
- Filtering and Mapping: Transforming or selecting specific records.
- Grouping: Merging various records into a single one.
- Joining: Fusing two streams into a single entity.
- Windowing: Segregating records based on determined time windows.
Kafka Event Management: A Practical Scenario
Let's take a theoretical situation to elucidate Kafka's event control mechanism. Imagine having a flow of sales events, and the goal is to calculate live cumulative sales by product category.
In this example, a StreamsBuilder object is created— a mandatory first step for any Kafka Streams application. Next, the "transactions" topic feeds the 'KStream'. Here, we group together sales events by product type and accumulate the sales totals. This presents a KTable that illustrates total sales for each category. Ultimately, the KTable is morphed back into a KStream and committed to the "sales-per-category" topic.
Key Points of Apache Kafka’s Event Management
Kafka's event command style presents a robust solution for modifying and analyzing real-time data. Kafka's structure is rooted in stream-based processing and can run operations from basic filtering and mapping to advanced strategies like grouping and joining. Kafka Streams, enhanced by its DSL, makes crafting sophisticated stream processing applications virtually seamless. No matter how specialized your requirements are, Kafka’s diverse toolset and its inviting capability can be employed to manage event control efficaciously.
Cloud Events' Significance in Event-Driven Architectures
Event-based design patterns serve as the cornerstone of modern software development, allowing systems to react swiftly to alterations in their surroundings. In such scenarios, CloudEvents has progressed to a crucial stage, providing a unified and inter-operable means to delineate event details uniformly.
The Necessity for Norms
The most notable significance of CloudEvents in event-based design patterns lies in its normalization of event data. Prior to the inception of CloudEvents, programmers contended with a plethora of event formats, each possessing a distinctive blueprint and semantics. This absence of norm caused obstructions in system integration, as every system boasted its distinctive mode of event delineation.
CloudEvents rectifies this problem, proposing a unified event pattern applicable across varying systems. This established norm simplifies system integration as all systems resonate the same 'syntax' in terms of events.
Imagine a situation where a system must analyse events from numerous provenances, like a database, message queue, or web platform. In the absence of an established event pattern, the system would need to comprehend the distinctive event patterns of each resource. However, CloudEvents ensures a uniform representation of all events, streamlining the event processing from divergent sources.
Compatibility and Transferability
CloudEvents contributes considerably to event-based design patterns through its endorsement of compatibility and transferability. Proposing a unified event pattern, CloudEvents ensures events can be seamlessly transferred amongst different systems and tech platforms.
Such compatibility holds profound importance in the current scenario, dominated by cloud-native applications composed of multiple micro services across varied platforms. Utilising CloudEvents, an event formulated by a micro service on a single platform can be smoothly processed by another micro service on a different platform.
Additionally, the support rendered by CloudEvents to multiple transport protocols like HTTP, AMQP, and MQTT, confirms that events can be conveyed across diverse networks, progressing their transferability.
Strengthening Event-based Design Patterns
CloudEvents gears the momentum in event-based design patterns through event data standardization, and encouraging compatibility and transferability. Using CloudEvents, programmers can concentrate on the application mechanics, discarding worries regarding event patterns and transport protocols.
Furthermore, the support CloudEvents provides for context specifics offering event metadata, allows programmers to construct detailed event-based applications. For instance, a context specific could specify the event origin, enabling an application to process events from diverse provenances in separate manners.
To sum it up, the normalization of event data, fostering compatibility and transferability, and support for context specifics by CloudEvents, bolsters its important role in event-based design patterns. Regardless of whether an uncomplicated application or a complex, cloud-native system is being developed, CloudEvents paves the way for effectively utilizing events to construct agile, real-time applications.
Understanding the Role of Producers and Consumers in Apache Kafka
Apache Kafka: Embracing Message Producers and Processor Units
Dwelling within the intricate network of Apache Kafka breathes two indispensable entities coined as ‘message procurers’ and ‘processor units.' More commonly, these are labelled as 'producers’ that conceive and deposit messages, and 'consumers' assigned with the task of deciphering and assimilating these messages. These key addresses chart the rapid-fire data landscape of Kafka.
Delineating the Function of Message Producers
Message producers are fundamental nodes inside the Kafka's sphere as they generate, or indeed 'produce,' data. These conduits can vary from programs monitoring user behaviour to advanced IoT mechanisms that provide sensor readings.
Dubbed 'producers', these data flow regulators supply Apache Kafka's architecture with a steady data current. Producers direct their data payloads into Kafka brokers, who act as custodians, shunting the data down the line for succeeding interpretation and processing.
Additionally, producers pocket the luxury of nominating their message-receptacle topics. Possessing the elasticity to regulate message recognition, they can choose to delay for broker receipt acknowledgement or act swiftly, discharging data without anticipating validation.
Interpreting the Function of Processor Units
Comparatively, we have 'consumers’, famously addressed as processor units. They unravel the intricate dialect depicted by the producers. Consumers sync to single or multiple Kafka topics and untwist, or ‘consume’ the data by fetching it from the brokers.
Processor units infuse rejuvenation into Kafka’s infrastructure by interacting with and propagating the data delivered by producers. They excavate the knowledge buried within Kafka brokers, decoding its mysteries and then deliberate whether to propel it downstream for deep processing or conserve it for ensuing utility.
Moreover, processor units coalesce to assemble processing brigades, thus magnifying data consumption speed. Kafka ascertains that each message gets delivered to a minimum of a single unit within a dedicated processing brigade.
The Synergetic Alliance of Producers and Processor Units
In the framework of Apache Kafka, message producers and processor units cultivate a stable, reciprocally productive relationship. The producers shape and deposit data into Kafka's domains, while the handlers decode and fine-tune it. This unceasing merry-go-round of data inception and consumption powers Kafka's dynamo.
Therefore, message producers and processor units are pivotal cogs that collaboratively direct Kafka's operational locomotive. They thrust Kafka's endless data stream, and thus grasping their pivotal roles and interrelation is a must when immersing oneself into the world of Apache Kafka.
CloudEvents Specification: Powerful Event Defining in Cloud Native Systems
CloudEvents epitomizes a common platform for showcasing instances or actions that happen within a system. It is the cornerstone of uninterrupted operations across event-focused architectures, especially in settings that embrace cloud-based solutions.
Unpacking the CloudEvents Protocol
Being a noteworthy project under the Cloud Native Computing Foundation umbrella, CloudEvents aim to establish a structured format to relay the particulars of an event. This format allows for the uniform transmission of event data, enabling all types of software, services, or systems to interpret and react to the conveyed data seamlessly, no matter the underlying technology or platform.
CloudEvents support a wide variety of event types. These might include activities from Internet of Things (IoT) devices, cloud set-ups, or even custom-defined software. The standard format established by CloudEvents enables these diverse actions to be discussed across various systems with ease.
Core Elements of the CloudEvents Protocol
CloudEvents pinpoint several primary attributes that are broadly incorporated within the event data. These data points could include staging details, event type, and its precise occurrence time. Below are the primary functionalities that the CloudEvents format encapsulates:
- Event Identification: Each event is given a distinctive label.
- Origination: Indicates where the event took place.
- Refver: The specific version of the CloudEvents protocol used for the event.
- Class: Specifies the group the event falls under.
- Data Type: The kind of data that the event contains.
- Data Layout: Shows the standard that the data follows.
- Focus: Additional details about the event in relation to the source.
- Instant: The specific period the event occurred.
CloudEvents in Action: Organizing Events in Fully Cloud-Based Set-Ups
In a complete cloud environment, events act as vehicles for system interaction. CloudEvents offer a templated technique for sorting these events, ensuring they are universally understood and coordinated.
For instance, assume a completely cloud-based system comprising services such as user registration, order handling, and inventory tracking. Despite using different technologies and platforms, these services communicate through events.
CloudEvents offer a consolidated communication medium guiding their interactions. Simultaneously, when a user signs up, the registration services can create an event labeled "signup.newuser". This event can be decoded by the order handling module to start the order process, and the inventory system can update its logs as well.
The Unseen Strength: CloudEvents
The sheer power of CloudEvents lies in its capability to impose uniform understanding of event specifics. As a result, all aspects of a system, regardless of their underlying tech or platform, can identify and handle events.
This not only intensifies the cross-functionality between different services but also simplifies including new service providers within the system by assuring quick recognition and processing of events.
Moreover, CloudEvents support extensions, allowing for additional info to be added into the event data without breaking the standard pattern.
In sum, this measurement model designed by CloudEvents is crucial in organizing events in completely cloud-based systems. It makes the presentation of event data consistent, hence enhancing interaction between services. Consequently, it becomes an integral part of the event-focused architecture, promoting the smooth transfer of events throughout various components.
Techniques for Data Management: Kafka vs Cloud Events

Shielding data is a vital role in any framework that is dependent on events. A comprehensive administration of data, encompassing its accumulation, retention, access, and optimal use while guaranteeing its resilience and veracity, accounts for a significant aspect of these frameworks. Two big-league entities, Apache Kafka, and Cloud Events, offer stout abilities concerning data adjudication but vary in their executions. This article will accentuate the discrete techniques employed by both, illuminating their positives and negatives.
Techniques Employed by Apache Kafka in Data Administration
Apache Kafka is esteemed for its capacity in handling copious amounts of data in a flash. Kafka utilizes a chronicle-based data structure where data is retained in a serialized, unremitting chronicle. This chronicle-oriented model excels in handling swift data on account of its rapid data amalgamation and access proficiencies.
In Kafka, the data governance is further distinguished by its deployment of topics and divisions. Topics serve as classifications of data, while partitions act as sections within a selected topic. The parallel processing proficiency of Kafka is amplified with this model, facilitating concurrent work on various partitions.
Lastly, Kafka deals with data persistence through its replication system. Each piece of information is redundantly duplicated across multiple brokers, which decreases the probability of data disappearance in case of system failures.
Techniques Employed by Cloud Events in Data Administration
Contrarily, Cloud Events advocates a universal model for encapsulating event data uniformly, devoid of any stringent data adjudication procedure. It successfully sets a criterion for event data depiction, engendering compatibility with numerous systems and technologies.
Cloud Events applies an elementary yet valuable data structure where an event is portrayed as key-value pairs, with 'id', 'source', and 'type' as typical key attributes. This framework is adaptable, permitting alterations and additions whenever necessary, even including custom characteristics if needed.
Data Administration in Kafka Vs. Cloud Events
Apache Kafka offers a structured and scrupulous method of data administration, whereas Cloud Events takes the stage with its flexibility. The chronicle-based framework of Kafka partnered with the incorporation of topics and divisions supplies effective administration of swift data. On the flip side, the expansibility of the Cloud Events data model provides high degrees of adaptability and customization.
To wrap up, the selection between Apache Kafka and Cloud Events ought to hinge solely on the specific requirements of your software. If swift data processing and dealing with a high volume of data are of utmost importance, then Kafka is your solution. Alternatively, for a flexible approach with high interoperability, Cloud Events is definitely a formidable option worth contemplating.
Scalability and Performance: Kafka vs Cloud Events
Determining the right real-time event-processing platform demands a careful analysis of the factors affecting expandability and performance. In this context, Apache Kafka and Cloud Events emerge as primary contenders, each offering unique propositions.
Apache Kafka: Scalability Colossus
The real-time handling of extensive data streams is where Apache Kafka truly shines, thanks to its specifically created architecture to manage scale. The Kafka platform is built upon a distributed cluster-based setup, facilitating seamless distribution over multiple servers and ensuring the consistent performance while dealing with colossal datasets.
The partitioning technique used in Apache Kafka allows each topic to be split into various segments that are handled by individual servers. This approach promotes efficient workload dispersion throughout the cluster, ensuring seamless data traffic and reduced latency.
Here’s a bitesize overview of Apache Kafka’s key scalability features:
Cloud Events: Performance Aficionado
Cloud Events takes a divergent approach, emphasizing largely on performance boosting and effortless integration. It brings to the table a uniform approach to representing event data, an essential feature that simplifies event identification and navigation across different platforms and services.
For Cloud Events, scalability isn't the primary goal as with Kafka. Rather, it focuses on presenting a uniform model for event definition and management, where any potential scalability is realized in conjunction with other auxiliary services.
Cloud Events' performance is inherently tied to the infrastructure it's deployed upon. For instance, utilizing Cloud Events within a serverless environment would mean the infrastructure provided by the serverless provider dictates performance.
Let’s look at Cloud Events’ performance-specific features:
A Comparison: Kafka versus Cloud Events
When examining Kafka and Cloud Events on the benchmarks of expandability and performance, the use-case situation becomes a critical determining factor. Apache Kafka thrives when an application mandates managing large real-time data flows. Its distributed design philosophy and excellent division technique result in high data flow rate and reduced latency.
On the other hand, Cloud Events is the go-to choice for applications needing a uniform method for event definition along with adaptable compatibility. While it proposes a consistent technique for defining and managing events across several services and platforms, the scalability and execution speed are significantly dependent on the base infrastructure.
In summary, the emphasis on scalability and performance differs considerably between Kafka and Cloud Events. Therefore, choosing between these two systems should be driven by your application's specific requirements.
The Paradigm of Fault Tolerance in Kafka and Cloud Events
Handling unexpected system issues is paramount in any decentralized system, notably in event-driven structures. Technically, this refers to the unfaltering performance of the system, even when faced with localized system glitches. We're going to explore how two systems, Apache Kafka and Cloud Events, manage these disruptions, highlighting the variabilities in their approaches and their interesting traits.
How Kafka Handles Disruptions
Replication forms the backbone of Apache Kafka's resilience against system glitches. Here, any data in Kafka is stored within topics, partitioned off into manageable segments which can be replicated over numerous nodes. This replication assures that even when a node malfunctions, the data remains accessible.
In this specific Kafka producer configuration, see how the 'acks' property is set to 'all.' It means that only when the data has been received by all replicas will the producer get an acknowledgment - a crucial aspect to ensure data's permanence and uninterrupted service.
Furthermore, Kafka also incorporates a feature named 'in-sync replicas' (ISR), a cluster of replica nodes fully in sync with the main one. So, if a node malfunctions, Kafka takes a new leader from the ISR list to avert any data loss.
How Cloud Events Withstands System Glitches
As a framework, Cloud Events does not have built-in resilience capabilities. However, it can work in tandem with other cloud-native technologies providing disruption handling mechanisms. For instance, Kubernetes, a renowned container orchestration tool, can manage and scale Cloud Events-oriented applications, thus providing uninterrupted service.
See how this YAML configuration presents a Knative Trigger, employed to subscribe to events within a Cloud Events-driven system. Now, if the 'hello-display' service ceases, Kubernetes has the capability to auto-regenerate it, safeguarding the system's ongoing operations.
Little Comparison: Kafka vs Cloud Events Handling Disruptions
The table demonstrates that while Kafka provides inherent disruption handling traits, Cloud Events depends on the base infrastructure in this aspect. As a result, although Cloud Events displays flexibility, any disruption prevention measures need careful deliberation during the design and execution of a Cloud Events-driven system.
In summary, both Apache Kafka and Cloud Events possess the capacity to handle system disruptions, albeit through varied methods. Kafka's embedded mechanisms make it an ideal choice for systems that prioritize data permanence. On the other hand, the versatility of Cloud Events allows it to adapt to varied contexts, provided that the base infrastructure's planned for disruption handling is thorough.
Event-Driven Architecture: Case Study with Apache Kafka
Event-centric system design, known as Event-Driven Architecture (EDA), empowers businesses with agility. It facilitates real-time responses to actions, changes or incidents. It's a robust instrument yielding system designs that are nimble, scalable and robust to failures. Discussing its qualities shall stall adventurers no longer, as we embark on a voyage with Apache Kafka in an e-commerce setting.
Our main character: An international online marketplace administering millions of monetary trades each day. The task list is long, housing operations such as customer's account setup, making purchases, stock maintenance, money transfer and package tracking. An event is the outcome of these operations, which our protagonist has to tackle instantly for an unbroken customer interaction.
The primary obstacle in our protagonist's journey is the administration and tackling of the gargantuan amount of events born out of these operations. Conventional stimulus-response models fall short of this enormity and scope. This online marketplace requires a reactive contrivance that processes events instantly, manages data at massive scales, and ensures data uniformity across various components.
The victorious hero to this challenge: Apache Kafka - the distributed event streaming stage. Kafka's capacity to manage instantaneous data stream earns it the heart of an EDA implementation.
Discussing our protagonist: Apache Kafka powers the online marketplace's event-centric architecture as its central part. Capturing the events birthed by various modules (producers), securely storing them, and averting failures, thereby, allowing different modules (consumers) instantaneous processing of these actions at their own speed.
A quick breakdown of Apache Kafka's role in the e-commerce set-up:
- During the creation of a fresh user account, the operation gets documented and sent to a Kafka stream.
- User's order placement forms a Kafka event which in turn is capable of sparking off other events - reduction of the stock or initiation of money transfer.
- The role of the Stock Maintenance system is to stay alert to the order events and update stock level instantly.
- Money Transfer Service's role is also to stay braced for order events to instigate the money transfer process.
- The Delivery services become alert once the payment event takes place to prompt delivery.
Post-implementing EDA with Apache Kafka, the marketplace experienced improvements:
- Capacity to increase: Kafka's distributed design allows it to deal with a massive number of events, making it adaptable.
- Instant circulated information: Kafka facilitates immediate distribution of actions, ensuring a continuous customer experience.
- Stamina: Kafka's inbuilt safety measure to avoid failure warrants that no function is dropped, enhancing the marketplace's robustness.
- Independence: Kafka's role as a mediator allows components to function autonomously reducing system's complexity.
This tale underlines the potency of event-focused architectures and Apache Kafka's part in realizing them. While the example used a global online marketplace, the theories remain relevant regardless of the field. Instant operations, scalability, resilience, and component independence are critical gains of EDA implementations with Kafka.
Cloud Events in Action: A Real-World Use Case
In the rapidly evolving realm of event-centric frameworks, the standard-agnostic data outline put forward by CloudEvents is making notable strides. This useful model has a straightforward, practical usage in various scenarios, sometimes clearly visible in business frameworks based on event-centric systems.
Case Study: E-commerce Platform
Consider a bustling e-commerce site conducting innumerable fiscal exchanges every day. The machinery of this platform is segmented into numerous microservices, each taking charge of a specific function like customer handling, inventory maintenance, transaction handling, and financial regulation. These microservices engage in constant chatter to ensure fluid operation of the system.
An event-centric framework brings a wealth of advantages in such a scenario, allowing microservices to swiftly adapt to changes which in turn boosts the system's dynamism and efficiency. However, event management could become convoluted owing to diverse event styles and protocols employed by varying microservices.
This is where the worth of CloudEvents is evident. By integrating CloudEvents in the operations, the e-commerce platform can homogenize the characteristics of event data, easing its administration and processing.
Application of CloudEvents
The initial phase in embracing CloudEvents involves documenting the event data. CloudEvents extends a prototype for this purpose, including elements such as id, source, specversion, type, and data. The following serves as an example of how event data could be depicted in JSON format:
In this example, specversion indicates the CloudEvents schema version in use. Type describes the sort of event, source identifies the event's origin context, and id is an exclusive identifier for the event. The data field contains the actual event data.
Post the event data description, it can be transmitted to an event broker. This intermediary is entrusted with disseminating the event details to the relevant microservices. For instance, in our e-commerce case study, an event would be transmitted when a new order is placed. The transaction handling microservice would then capture the event and complete the transaction.
Benefits of Incorporating CloudEvents
The adoption of CloudEvents in this instance brings manifold benefits. Firstly, it uniformizes event administration. Since all events conform to a uniform structure, they become simpler to administer and process, enhancing efficiency and reducing potential mishaps.
Additionally, CloudEvents enhances interoperability. As a standard-agnostic solution, it can dovetail with any coding language or platform that support HTTP or JSON, guaranteeing seamless integration with existing systems and technologies.
Lastly, CloudEvents augments the system's flexibility. By partitioning the microservices and enabling communication through events, the system remains poised to handle an upsurge in workload.
In conclusion, CloudEvents provides an effective solution for handling event-driven architectures. Its standard blueprint streamlines event management, promotes interoperability, and heightens flexibility, making it a top-notch choice for contemporary applications driven by microservices.
Integrations and Extensions: Kafka and Cloud Events Complementing Other Technologies
The Symbiosis and Progression of Apache Kafka
Apache Kafka, a potent and fully accessible platform, supplies an affluent setting for cooperative interaction and expansive compatibility. Kafka's innate flexibility enables it to interface with a multitude of systems and technical landscapes, thus extending its operational reach.
Unleashing Kafka Connect's Potential
Kafka Connect, endowed with a host of functionalities, is devised to excel in the seamless transportation of data between Apache Kafka and diverse data ecosystems, all while preserving scalability and reliability. Kafka Connect simplifies the creation of connectors tasked with shifting large data volumes effectively through Kafka. This multifaceted instrument can assimilate myriad databases or gather metrics from all your application servers into Kafka topics, ensuring immediate data availability for stream modulation.
Leveraging Kafka Streams
Kafka Streams, a beneficial end-user library, is engineered for executing applications and microservice development. Within this framework, Kafka clusters accommodate both inbound and outbound data. Kafka Streams harmonizes the simplicity of crafting and launching Java and Scala applications on the client-side with the advantages offered by Kafka's server-side cluster tech.
Cohesion Between Kafka and Big Data Tools
Apache Kafka successfully meshes with big data tools such as Hadoop, Spark, and Storm, facilitating immediate data scrutiny and processing. This enables corporate entities to formulate swift, data-responsive decisions.
The Confluence and Development of Cloud Events
Recognized as a yardstick for defining event data, Cloud Events afford numerous alliances and growth opportunities. These collaborations empower Cloud Events to function seamlessly with a wide array of cloud services and platforms.
Harnessing CloudEvents SDKs
CloudEvents proffer a multitude of Software Development Kits (SDKs) for several coding languages like Go, JavaScript, Java, and Python. These toolsets enable developers to smoothly generate and interact with CloudEvents defined in their chosen programming language.
Synchronization with Serverless Platforms
CloudEvents can easily integrate with serverless platforms such as AWS Lambda, Google Cloud Functions, and Azure Functions. This compatibility allows developers to design event-driven applications that can adapt dynamically to inbound events.
Interaction with Event Sources
CloudEvents can intertwine with a host of event sources like databases, message queues, and IoT devices. This convenience allows the creation of a cohesive event-guided structure equipped to manage events emanating from diverse origins.
In summary, the symbiosis and growth of Apache Kafka and Cloud Events significantly affect alignment with diverse technologies. They not only amplify the efficiency of Kafka and Cloud Events but also foster their interconnections with a broad array of systems and technologies. This synergistic association is vital in constructing resilient, scalable, and proficient event-driven infrastructures.
Security Measures in Kafka and Cloud Events
In the sphere of event-triggered framework models, the criticality of security cannot be overstressed. A comparative analysis of the safety protocols utilized in Apache Kafka and Cloud Events underlines this emphasis. Notably, both platforms take privacy and data safety seriously, albeit in distinct ways, supplemented by their unique set of features and rules.
Protective Steps in Apache Kafka
In its bid to safeguard data, Apache Kafka employs a multi-tiered structure of security measures. These are:
- Transport Layer Protection (TLS): Kafka harnesses the capabilities of TLS for securing both client-server and broker exchanges. The protocol is geared towards ensuring that data transferred over a network is not unlawfully accessed or modified.
- SASL Verification: A crucial part of Kafka's security jigsaw is the Simple Authentication and Security Layer (SASL), utilized for verifying the client-broker relationship. SASL is adaptable, working seamlessly with a slew of mechanisms such as PLAIN, SCRAM, etc.
- Access Right Management (ACLs): With the help of Access Control Lists (ACLs), Kafka effectively governs the access to data. ACLs rules can be set for varied levels - topic, consumer group, or the entire cluster.
- Data Encoding: To further bolster its defenses, Kafka allows for data encryption when stored or during transmission. This means that intercepted data cannot be read without the right decryption keys.
The following small Java code piece demonstrates how SASL/SCRAM verification can be configured in Kafka:
Security Implementations in Cloud Events
In stark contrast, Cloud Events does not inherently possess security frameworks. It leans heavily on the security systems provided by the base transport protocols (HTTP, MQTT, AMQP, and so forth) and the hosting cloud platform.
However, Cloud Events does outline certain attributes for event data, which can be handy in implementing safeguard measures. These include:
- Datacontenttype: This attribute spells out the media type of event data, enabling the processing of only certain data types.
- DataSchema: This attribute references the schema the event data abides by. This can be utilized for data validation, both its structure and content.
- Subject: This attribute lays out the event's subject relating to the event generator, enabling filtering of events based on their subject matter.
Here's an instance of a Cloud Event with these attributes:
Security Features - A Comparative Look
To sum up, while Apache Kafka touts robust, in-built security architecture, Cloud Events is reliant on the defenses afforded by the base transport protocol and cloud platform. Nevertheless, the event attributes outlined by Cloud Events do open up an avenue to roll out more security measures.
Best Practices for Implementing Kafka and Cloud Events
Utilizing purposefully engineered Event-Based Framework (EBF), supported by instruments like Kafka Tools and Stream Cloud, offers powerful paybacks for enterprises handling complex data streams. Here are specific strategies to ensure seamless orchestration of your EBF model.
Detailed Inspection of System Necessities
An in-depth audit of your system's needs is vital before installing Kafka Tools or Stream Cloud. It entails characterizing the components, data volume, and pace of data management needed for your platform. Such a scrutinizing procedure is quintessential in selecting the tech tool that aligns with your needs.
For instance, Kafka Tools might be more fitting for scenarios demanding quick manipulation of colossal data volumes. On the other hand, for cloud-oriented applications necessitating a uniform technique to portray data activities, Stream Cloud could be the more considered option.
Developing Your Event-Based Structure
Equipped with a lucid comprehension of your needs, start working on your EBF blueprint. This stage involves recognizing your system's components and describing their roles and mutual connections.
When working with Kafka Tools, consider your data disseminators (originators), data receivers (end-users), and primary servers managing your data (liaisons).
For Stream Cloud assignments, detect event triggers (activity initiators), operatives responsible for event processing (activity recipients), and connectors facilitating the link between initiators and recipients (activity routers).
Implementing Kafka Tools
While applying Kafka Tools, consider these robust methods:
- Partitioning: Use partitioning to disperse data among several liaisons, enhancing system capacity and performance.
- Duplication: Utilize duplication tactics to shield data and strengthen system robustness - crucial during potential server glitches.
- Consumer Group: Opt for consumer groups to allow several end-users to process data simultaneously, augmenting throughput and effectiveness.
- Protection Techniques: Implement key protective methods like SSL/TLS code-scrambling, SASL authentification, and ACL-specified access control to bolster your data.
Implementing Stream Cloud
When activating Stream Cloud, employ these persuasive strategies:
- Homogeneity: Adhere to the StreamCloud protocol to assure standard portrayal of activity data, fostering compatibility across varying systems and platforms.
- Contextual Data: Pair contextual data with your activities, granting recipients insight regarding the event origin and expected responses.
- Event Manager: Deploy an event manager for effortless passage of activities from initiators to recipients, increasing system functionality and bandwidth.
- Protection Tactics: Implement defensive techniques like HTTPS code-scrambling and OAuth2 authentication processes for data protection.
Appraisal and Supervision
Upon concluding the Kafka Tools or Stream Cloud setup, maintain regular checks and inspection of your infrastructure. Conduct capacity tests to evaluate operational capacity during high data traffic periods. Apply real-time surveillance instruments to monitor systemic performance constantly.
Following these customized game plans ensures a coordinated setup of Kafka Tools or Stream Cloud within your EBF.
Forecasting the Future: The Evolution of Event-Driven Architectures
As we progressively move towards the age of inventive system configurations, comprehending the current tendencies and their implications on future dynamic network patterns is of utmost importance. Different facets like the surging scope of colossal datasets, the proliferation of interconnected digital devices (IoT) and the requisition for instantaneous data processing have accelerated the significance of dynamic designs in system architecture.
Magnitude of Extensive Datasets
The term ‘extensive datasets’ signifies the enormous quantum of data being created every moment, accruing from divergent sources like social platforms, interconnected digital devices (IoT) and commercial transactions. Traditional processing techniques falter in the face of this data, due to its sheer magnitude, breakneck speed of generation and the extensive range of variability.
Dynamic designs in architecture, with their inherent characteristic of processing voluminous data instantaneously, are the ideal systems for controlling such extensive data. This endows enterprises with the ability to extrapolate insights and make informed decisions based on real-time data, thus securing them an edge over their competitors.
Significance of IoT
The proliferation of interconnected gadgets, popularly known as Internet of Things (IoT), is another key factor dictating the future course of dynamic system architectures. These devices continuously generate data that requires real-time analysis and processing.
This is where dynamic system configuration emerges as the ideal system controller, capable of managing the rapid and voluminous data generation from IoT devices. This allows enterprises to immediately respond to ever-changing events, which is an absolute necessity in applications like predictive maintenance, where timely interventions can circumvent expensive machinery breakdowns.
Instantaneous Data Processing – The Need of the Hour
The contemporary world is characterized by swift changes, necessitating businesses to respond to events the moment they occur. This demand for real-time data processing is molding the future of dynamic system designs.
These system architectures empower enterprises to process and respond to incoming events in lightning-fast speed. This capability is vital for various applications, from spotting irregularities in fiscal dealings to immediate recommendations in digital commerce.
Pioneers of Future System Designs: Apache Kafka and Cloud Events
Both Apache Kafka and Cloud Events are being acknowledged as pioneers in the future of dynamic system configurations. Each offers robust features for managing voluminous data swiftly.
Apache Kafka, designed to control high-velocity and high-volume data flows, is a decentralized stream processing framework which allows real-time publication and subscription to data streams. It is an ideal choice for handling extensive datasets and IoT applications.
On the other side, Cloud Events is a description paradigm for characterizing event-data uniformly, aimed at facilitating event declaration and delivery through different platforms, services and beyond.
As we move forward, one can expect to see a more integrated collaboration between different technologies within dynamic system designs. For instance, one potential scenario could be a more cohesive integration between Apache Kafka and Cloud Events, enabling businesses to tap into the strengths of both platforms.
Furthermore, more automation within the dynamic system designs can be expected, courtesy of the advancements in Artificial Intelligence and Machine Learning. These technologies can be utilized to automate processing and analysis of event-based data.
In a nutshell, one can safely predict a promising future for dynamic system architectures. With extensive datasets, IoT and instantaneous data processing being the norm, these systems are bound to gain more prominence in the coming times. Power players such as Apache Kafka and Cloud Events, with their robust features and constant evolution, are set to play a pivotal role in shaping this future.
Conclusion: Making the Right Choice - Apache Kafka or Cloud Events
In the field of systems powered by events, a couple of solutions have made significant impressions - the renowned Apache Kafka and the adaptable Cloud Events. Which to choose should depend on what your project specifically requires.
Apache Kafka: Pioneering Massive Data Streams Handling
Apache Kafka has earned itself a reputation as a platform that excels in managing large volumes of 'live' data streams. Where Kafka truly excels is with its inherent function of replayability and superior data processing abilities, making it the primary choice when immediate, data-dense insights are necessary for rapid strategic choices.
In Kafka's system, the interaction between data manufacturers and consumers is essential. Data originators build streams, known as topics, and data consumers subscribe to these topical streams, simultaneously absorbing data. This interactive model is highly scalable and supports parallel processing, making Kafka an excellent choice for applications with substantial data processing needs.
However, its underlying complexity makes Kafka less ideal for simpler projects or teams with limited resources. Implementing Kafka means committing a considerable resource of time and skill for initial setup, as well as regular management. Further, its API might be intricate and difficult to grasp.
Cloud Events: Flexible and Nimble Solution
Contrasting with Kafka, Cloud Events is a universal standard for uniformly packing event data. Aimed at facilitating event-based development across varying cloud environments, Cloud Events delivers a flexible and nimble alternative to Kafka.
What sets Cloud Events apart is its simplified, customizable methodology. By offering global event patterns compatible with a multitude of platforms and services, it consolidates the initiation and management of event responsive applications. Its design encourages simple implementation and is less draining on resources, thus making it a more suitable option for smaller teams or less complicated projects.
However, Cloud Events doesn't measure up to Kafka in terms of robustness or a broad range of features. It is devoid of comprehensive capabilities for error recovery and handling large sets of data. It is not built to control extensive data streams.
The Deciding Factors
Your project's specific demands will dictate the comparison between Apache Kafka and Cloud Events. If your project calls for the instantaneous handling of massive data flows, Kafka is the ideal solution. Its sturdy structure and commendable data processing prowess cater perfectly to such challenging tasks.
Conversely, if the scale of your project is relatively modest or you require a malleable, swift solution, Cloud Events should be your consideration. Its clean design and easy implementation make it a favored choice among smaller teams or projects with fewer resources.
Eventually, both Apache Kafka and Cloud Events offer solid foundations to structure your event-responsive systems. The choice between them should align your project's specific requirements and resources. By considering both the strengths and weaknesses of each technology, you can make an informed decision that aligns seamlessly with your project’s aims.
FAQ
Subscribe for the latest news

































.jpeg)


