What is Serverless Computing?
Developing digital solutions is a tough task, but making them live them is not easy either. Server maintenance is not a simple operation either. Serverless computing, a recent discovery, has now made the development process smoother, as professionals are allowed to procure need-based servers while not being worried about their enablement, maintenance, and troubleshooting.
This cloud computing based approach for IT operations execution has already made its way to 40% of the total existing organizations.
What is it and why is it trending?
Let us tell you everything about it through this article.

Understanding Serverless Computing Thoroughly
Before we delve any deeper, first understand what cannot be considered uner this category. It doesn’t mean developing applications without physical servers. It means not getting involved in tasks like server implementation and other aspects while utilizing them in full swing. Physical servers are used as they should be but developers don’t have to be concerned about any of this.
In this model, developers/organizations take the help of third-party service givers that offer need-based servers on a subscription basis.
This third-party, in this scenario, is responsible for server installation, update, hardware/software maintenance, and other related tasks. There is one notable difference between common subscription types vs serverless computing subscription. It is that there is no fixed cost to pay with the latter one.
The costing is auto-scaling and is calculated as per the consumption.
Developers/organizations are more focused on code development that leads to better-performing applications. In the process, you must know the followings:
- The meaning of serverless framework
It refers to a cost-free and Node.js, based web framework for developing applications. AWS Lambda was the first-ever framework developed in this category.
- The meaning of serverless stacks
Stack is a software component, featuring programming language to use for code development, what one needs for app-building. A serverless stack of SST makes app creation easy.
- The meaning of serverless database
A database is a place where information that developed code needs to access/utilize is stored. Also, the database stores the stack triggers to execute those codes. Serverless databases are similar to traditional databases in behavior except the indefinite data storage. DynamoDB, Cloud Firestore, and Azure Cloud DB are best examples.
Advantages and disadvantages
Serverless computing is a mixed bag. There are multiple pros and a few drawbacks. The one who is aware of both aspects is likely to reap the maximum rewards of this technology. Here is why we present you with a crisp overview of the up and downsides of this cloud computing type.
The Positive Side
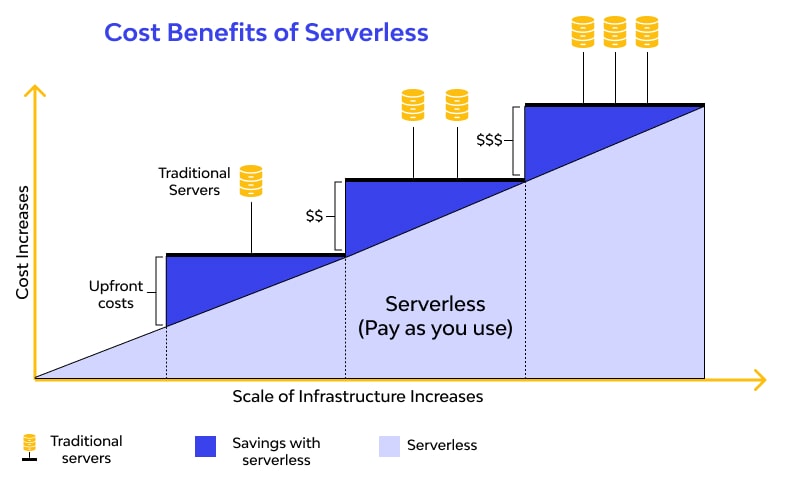
- Lesser Development Cost
Before serverless computing, organizations/developers need to invest heavily in the set-up of physical servers to complete the application development. Other than hardware, physical servers demand huge technology support as well.
The investment was not limited to set-up; it extends to continual maintenance, licensing, dependencies, support, patching, and many more things. Overall, owning physical servers used to be very pocket-pinching.
With serverless computing, nothing of this sort is going to happen. As quoted above, the service model is auto-scaled and charges the client as per the consumption. This way, you only pay for what you use. The service provider will look into the licensing, maintenance, and other direct/indirect costs.
- Maximum resource utilization
Even if one manages to invest in whatever demands setting up physical servers, it’s not possible to utilize them fully. Most of the time, there is high idle CPU time and unused resources. This is a sheer resource wastage.
Serverless computing is a great relief on this front as well. You use resources just as you required and pay accordingly.
- Improved application development
Needless to mention that physical servers are not only pocket-heavy but are also very exhaustive for developers. They have to get involved extensively in their optimization, version updates, technical glitch fixation, and many other tasks. When the time and attention of the developer are diverted, the quality is hampered for sure. This also leads to more time-to-market.
Those who are using serverless computing are likely to have quality applications as the entire attention of the developer is on code development. They have time to check for bugs, write extensive codes, and improve the security that leads to perfected applications.
Also, it reduces the time-to-market. Generally, developers adopting serverless computing will be able to develop applications a bit fast.
- Great comfort
Kindly note that serverless computing endows developers with a polyglot ecosystem wherein they are permitted to use whichever language/development framework they want. They are comfortable with Python, they can go ahead. If they are well-versed in Java then also end-to-end development is possible.
The comfort increases a bit more with an easy DevOps cycle. There is no need to get involved in infrastructural integration, testing, and code deployment.
- Scaling on demand
Serverless computing makes policy scaling easier than ever. They don’t have to worry about whether or not their codes are complying with the policy. The service provider will look into the matter.
The Drawbacks
- Limited authority
As physical servers are the property of the service providers, clients/developers don’t have any authority on the resources used or deployed. This could be an issue when one is migrating.
- Reduced use cases
Even with multiple use-cases, it’s not a go-to approach for all workloads. You can’t use it when you need high-performance systems to continue with your app’s extensive application development.
- Latency
The codes in serverless computing are often infrequently used. Such codes have higher chances of latency as the service provider will spin down not in-use codes. Using such codes will lead to higher latency when used in a high runtime ecosystem.
- Troubled debugging
Regardless of the quality, certain performance issues are likely to happen for sure. Their identification and remedial, in serverless scenario, is difficult as functions are timed and developers have no freedom to use trouble-fixing tools like APM, and debuggers to fix the issues. This also has a negative impact on API security.
- No 100% privacy
Understand that resources are offered in a third-party-owned public space in the serverless case. With shared resources, privacy is compromised. However, there is a way out of this problem. Serverless also works on private cloud and on-site resources at a higher cost.
Serverless & FaaS - Are they The Same Thing or Different?
The terms Functions As A Service and serverless replace each other many times. Though they share great similarities, they are not exactly the same thing.
We already discussed what this computing type is. Now, let’s understand FaaS. It’s an upcoming service model wherein developers can smoothly develop functions while utilizing the cloud ecosystem.
Going serverless is super-beneficial in working with the infrastructure components without being worried about scalability. While it can work greatly with various incidents like API, data processing, and microservices, FaaS is mostly good for micro services. Using FaaS, permits developers to continue with development without being dependent on any specific framework.
Serverless Computing and Kubernetes
Kubernetes is another famous pick for app deployment among developers. It is designed and deployed to make the serverless experience a bit better than before. It’s a globally known container orchestration platform offered free of cost. It’s responsible for automatic container management, deployment, and scaling so that container-based applications become an easy task.
When we talk about serverless computing, it’s crucial to understand that some of the applications, developed using the model, are container-based. Such apps can’t be managed or executed solely with Kubernetes. It needs specialized software that can bring Kubernetes and serverless platforms together.
In-directly, containers support serverless computing but with certain complexities. Many vendors, who use serverless computing, also utilize the containers for microservices so that containers and serverless technology can co-exist.
The concept of serverless containers is taking shape. For instance, we have AWS Fargate claiming to offer this facility. AWS Fargateprovides services like registry support and load balancing on the per-second billing model. With this resource, there is no need to get extensively involved in scaling or configurations of VMs to using containers.
They both support auto scaling and work towards the same goal. Hence, making a choice between these two doesn’t make any sense. Instead, co-existence possibilities should be figured out.
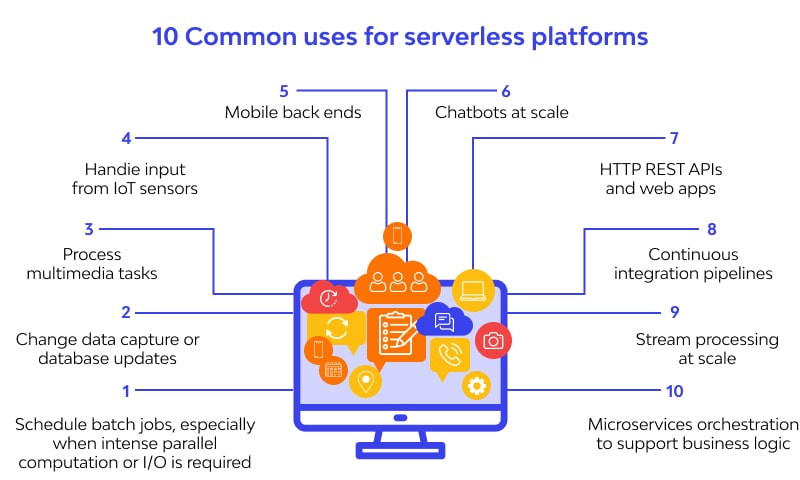
Serverless Computing Use Cases
Thanks to its end-less benefits this model has become the spine for mobile back-end streaming, microservices-based solutions, and app operation processing.
The pay-as-you-go model of serverless computing has made it the first choice for microservice development as it supports auto-scaling and quick provision.
As we already know that serverless functions feature easy-to-consume HTTP end-points for web clients. These functions can later turn into full-fledged APIs supporting rate-limiting, OAuth, and improved encryption. This is very useful for a strong mobile back-end.
Anyone working closely with tasks demanding extensive and assorted data processing in the form of video, text data, audio files, and image, must consider using serverless computing as it’s quicker than ever this way. Serverless offline with AWS SAM is a great option it lets one to run codes offline.
With serverless application framework also, you’ve serverless offline plugin to make things possible and seamless.
The Future of Serverless
As per recent market research, serverless computing should become a technology worth USD 7712.7 million by 2026. The figure indicates a better future for this trend. The trend is likely to evolve for good as service providers are working on the drawbacks.
For instance, CloudFlare is working extensively to reduce the cold start or latency experienced with the service. The service provider made this happen by utilizing the TLS handshake timespan to spin functions.
The model is likely to have increased demand in the telecommunication and digital media domain as it increases service delivery, as it utilizes cloud computing efficiently.
Serverless Computing Providers
- AWS Lambda
A brainchild of Amazon, AWS Lambda is a globally available serverless computing service provider. Honestly speaking, it was the first service provider ever. It came into being in 2014 and continued to be the market leader with exceptional services and features like custom runtime, reduced latency, access to persistence, and many more.
- Azure Functions
Launched in 2016, Azure Functions is Microsoft’s brainchild, build with a focus on customary serverless computing. Another purpose of its creation was to provide a reliable way to support Azure integrations. Well-integrated HTTP endpoints, multiple deployment, and extensible bindings are some of the key features of this service provider. Languages like Python, Java, TypeScript, F#, and many more are supported by it.
- Google Cloud Functions
Even though AWS Lambda was very useful, it created a gap as only Amazon users were allowed to use it and it’s very complex. Google jumped in to fill the gap through Cloud Functions, which is a general serverless computing service. It’s relatively easy to use and is compatible with solutions developed in programming languages like Node.js, Java, Ruby, and .Net Core.
A means to save a huge deal of time, effort, and pricing, serverless computing is making high waves in the developer community. Hope this article helped you understand everything about the subject clearly.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")