What is Kubernetes multi-cluster? Architecture & Management
If one mentions containerized applications, Kubernetes will be there. It has become the synonym for high-level performance and availability in a containerized ecosystem. What makes it preferable is its ability to run various clusters simultaneously to ensure that system/application failure isn’t going to happen.
Multi cluster Kubernetes architecture is what we meant here.
Explore more about this concept with this post. As you proceed, you will be able to learn about the Kubernetes multi-cluster, its functionality, and other related concepts.

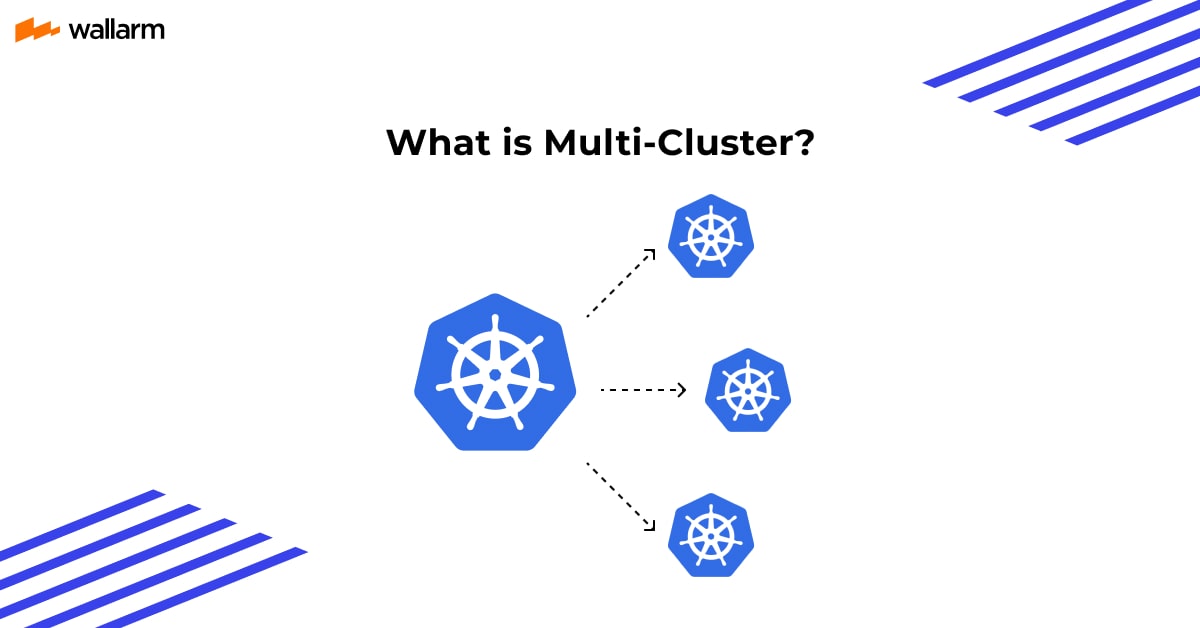
What does Multi-Cluster Mean?
Let’s talk about the main thing; multi-cluster Kubernetes. It’s a modern Kubernetes architecture that involves using more than one Kubernetes cluster at a time. All the used clusters are closely linked and are used at a time to make sure that businesses never experience a cluster failure.
For beginners, the cluster is a node collection. Now, nodes are of two kinds: worker and central controller nodes. Each exists for a different purpose. For instance, the control node is responsible for the cluster state management while worker nodes are accountable for running containers.
Together, they form a cluster, which is the core of Kubernetes. In general terms, clusters are often referred to as computers, using Kubernetes services. Now, the other way to describe multi-cluster is a collection of computers that could be physically or virtually deployed.
Just like a system, a multi-cluster will own a dedicated security management system that can be used for user authorization and access control.
There is one more fact to get familiar with. Multi-cluster doesn’t mean that more than one cloud is in practice. It means more than this. It’s also the scenario when a company uses multiple approaches and tools to make sure that multiple Kubernetes environments are in sync and easily managed.
Why Multi-Cluster?
Traditionally, one cluster is always used. What made the world ask for multi-cluster and why the developer community is supporting its usage? Well, here is why.
- It ensures maximum resource utilization
This approach promises zero resource wastage. When you have multiple clusters, it’s easy for you to distribute clusters as per the performance requirements of a data center.
Consider this: Applications demanding low latency and swift execution will be allotted to a nearby data center cluster. The code of such applications that further be deployed over better-performing machines.
If the situation is reversed meaning applications don’t require fast processing but high-end machine usage overheads should be on the lower side.
A less horsepower-consuming data center is the best bet here. This requirement-based data center and resource allocation are only possible when a multi-cluster is there.
- Easy regulatory compliance
Adherence to regulatory compliance is a must. But, when there are multiple domains to handle, it becomes too tedious. Thankfully, this is the case with the multi-cluster as it leads to bulk compliance application on multinational domains easily. Wherever distributed computing is concerned, this makes things much better.
- Effortless tenant isolation
Those who are using Kubernetes are most likely to hate it for its inability to handle multiple tenants in one go. However, using multi-tenants is non-negotiable when quick development and staging are the concern.
With a multi-cluster approach, it’s easy to handle multiple tenants as it helps in isolating the tenants, with the help of a namespace.
- Hassle-free management
One can have a centralized cluster management system and manage the logging, auditing, security, troubleshooting, and various other things of all the linked clusters in one go. It saves a huge deal of time and effort.
- Fewer failover possibilities
We have already mentioned this; having multiple clusters in a single environment ensures that the system is not going down just because of a single cluster’s issue. It’s important to maintain the performance flow.
- Seamless scalability and application bursting
You can’t scale and burst at a large scale while using a single cluster as it comes with obvious limitations. But, when multiple clusters are there, it’s easy to scale beyond the normal limits.
- Better management of geographically distributed systems
It’s not possible and suggests sticking to a single cluster approach while handling geographically diverse systems. With multi-clusters, organizations can have clusters deployed at different locations and manage the system easily.
- Improved IoT services
Anyone offering IoT services/products must consider using a multi-cluster approach as IoT performs better when the application is close to the data source. Use different clusters and deploy them near the data source. It’s the wisest move to make to improve IoT performance.
Multi-cluster Kubernetes architecture
The Kubernetes architecture is based on clusters. So, if you need to know about Kubernetes architecture, you have to understand what cluster means. There are three planes here.
The first cluster plane is the control plane which is the brain of the Kubernetes cluster. It features components like Control Manager, Scheduler, and API server.
The next plane is the data plane that acts like cluster storage in Kubernetes multi cluster Ingress and other clusters. Its implementation is possible using etcd databases.
Lastly, we have a workable plan to discuss. In Kubernetes, it refers to the plane responsible for running the concerning workloads in the cluster. As the cluster features nodes and pods, the worker plane runs these two as well.
Have a look at the below-mentioned picture to have better clarity on the architecture.

It seems very easy. But, it’s complex in reality. For instance, there is a possibility of cluster redundancy architecture that involves creating exact copies of one cluster.
Segmentation vs. Replication
Going further, the use of multi-cluster Kubernetes allows application architects to access replication and segmentation architecture. Keep note of the fact that only one will exist at a time. Now, why do these matter?
Well, segmentation architecture breaks down an application into multiple independent segments. Each segment will be considered a fully-independent Kubernetes service which is further assigned to clusters as per the requirement. In this architecture, internal communication, between the apps and across the cluster, is great.
Segmentation also results in easily lost coupling of microservices-oriented architectures that promotes independence. This way, it promotes around–the–clock accessibility and performance delivery.
Let’s discuss replication now. It means creating exact copies of a single cluster and deploying them in different data centers. By doing so, this approach promotes high performance and ensures resiliency across the clusters. As copies are hosted nearby, traffic routing is easy.
Now, let’s try to understand a few differences that they share. In replication, ML is used to find the similarities between two clusters.
In segmentation, data is manually pulled to concerning groups and understand the large data requirement.
Even though they are not the same, they both are here to empower application performance and accessibility, which is much needed presently.
Kubernetes-centric vs. Network-centric Configuration
When one deals in k8s multi-cluster, two choices are there.
The first choice is Kubernetes-centric configuration which involves deploying different applications on different clusters. But, they all will be managed from a centralized platform. This is time-consuming when deployment is considered, and easy when cluster management is concerned.
The second offered choice is the network-centric configuration that involves generating an exact copy of an application and using it in different kinds of clusters. These clusters are generally located at distinct locations. All these clusters in this method will work like independent entities. You might need a network to communicate with all of them.
Benefits and challenges of using a multi-cluster architecture
Multi-cluster architecture has gained huge popularity recently because of its lucrative benefits. If you’re not aware of those, have a look at the below-mentioned list.
This approach leads to easy cluster upgrades, management, and security fixes. There are tools that will help you apply rules and exceptions for all these workflows on all the linked clusters over a single click. There is no need to put effort into every single cluster.
- It’s an easy way to bring configuration customization into action. Different applications will require distinct configurations to meet specific requirements. For instance, a few apps will require a CNI plugin while a few will need IoT integrations. Multi-cluster helps to bring need-based customization into action. It’s possible to set isolation boundaries and control the cluster life cycle.
- If you’re an organization taking the help of multiple 3rd party vendors, multi-cluster is a great resource to adopt. It will help you do easy vendor lock-in. Even if a vendor is repeatedly changing the pricing & model, multi-cluster won’t make them hamper your workload. This setup makes your workloads cloud–agonistic. Taking your vendor offerings on the cloud makes things better as model shifting and upgrading are easier than ever for you.
- You can attain full flexibility in the development. Clusters of different capabilities can be used.
A lot has been discussed about the benefits that this approach renders. It’s time to talk about the challenges, which are many.
- The first one is the high level of complexity. Kubernetes is not an easy job to handle. And, when multiple clusters are joined together, complexity increases two-fold. You might have to deal with multiple configurations for multiple clusters. Setting-up different firewalls for different clusters is also tedious. There are multiple APIs and API servers to handle. All in all, everything becomes too much to handle.
- The second challenge that one might face while dealing with multi-cluster is ensuring sound security. Different clusters will ask for different security postures that become too complex to handle.
- One has to be extra smart while extensively involved in multi-cluster deployment. All the workflows and processes should be diligently planned and arranged. This is a huge task in itself.
- Lastly, we would like to mention the high cost involved in the process. It’s not easy to procure different clusters as there will be high overheads. You have to invest in buying, maintenance, updates, and on various other things. So, it’s certainly not a choice for everyone.
How do I connect to multiple Kubernetes clusters?
The core of Kubernetes multi-cluster management lies in the fact that all the independent clusters should look and behave like a unified entity. Just as it happens with the Kubernetes federation. This seems easy but is not flawless. For operators, it’s highly confusing and adds severe complexities.
While you want to connect to multiple Kubernetes clusters, a preferred choice is using an application-centric approach as it keeps all the concerned clusters fully independent. The cluster-related migration is often the application’s concern. However, it can also fall under the responsibility of a service mesh, if it’s used in the application.
They both are standard approaches to connecting with multiple clusters. Regardless of the approach picked, it’s important to keep the networking implications at the core.
How to work with multiple Kubernetes clusters?
To adopt multi-cluster, you must have the full understanding of the basic workflow. The very basic thought to consider here is to start understanding how one can reach/use a single cluster in k8s.
Generally, clients like kubectl are used for this job. Such a file will feature basic cluster definition.
You need to look for two clusters, demo and gettingstarted, in these files. Switch between these two clusters using contexts.
kubectl config --kubeconfig=mykubeconfigfile set-context appcontext --cluster=gettingstarted --namespace=app1 --user=nick
This command will link the new context to the KUBECONFIG.
To use this new context, try this command.
The job is done. Any executed command will run against this new context and you can work with multiple clusters. So, start leveraging the advantages of distributed systems/solutions now.
Conclusion
Kubernetes, with its single cluster functionality, is great. But, it’s not capable of handling extended functionalities that come with IoT and distributed systems. Needless to say, it disappoints big time when flexibility, resilience, and security are concerned. For such requirements, Kubernetes multi-cluster is the right option to consider.
This architecture approach won’t restrict you and provide endless opportunities to introduce customizations and scalabilities. It’s great in any sense. But, it’s also not a flawless approach. Be ready to deal with complexities and high overheads. But, it’s worth a try. The way it empowers application development is highly commendable.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")
.png "AWS with Wallarm")