What is High Availability? Definition, Architecture, Best Practices
Thriving in the present cut-throat era demands the backing of IT resources/systems/devices that won’t fail. They should remain functional by all means possible.
For mission-critical operations, such IT components are key to success. Ensuring this persistent and performance system availability is concerned with high availability or HA. Let’s get our hands on this approach.


High Availability Definition
In an organization, systems of all sorts are used. Some automate core functions while few are assigned for mission-critical workflow management. For a growing organization with scaled goals, it’s important to have systems that don’t disappoint or under-perform.
HA or High Availability is the term used for such IT resources. Servers, computing devices, networks, apps, clusters, and 3rd party tools that remain functional with zero downtime fall under this category. Generally, they are utterly time-tested, optimized, and secured IT resources.
What’s worth noting here is that the availability is time-relative. Here, two-time references are taken:
#1. Service accessibility time
#2. Time taken by the respective device/system to provide a suitable response.
HA includes systems that manage to deliver quality performance relative to the above-mentioned period.
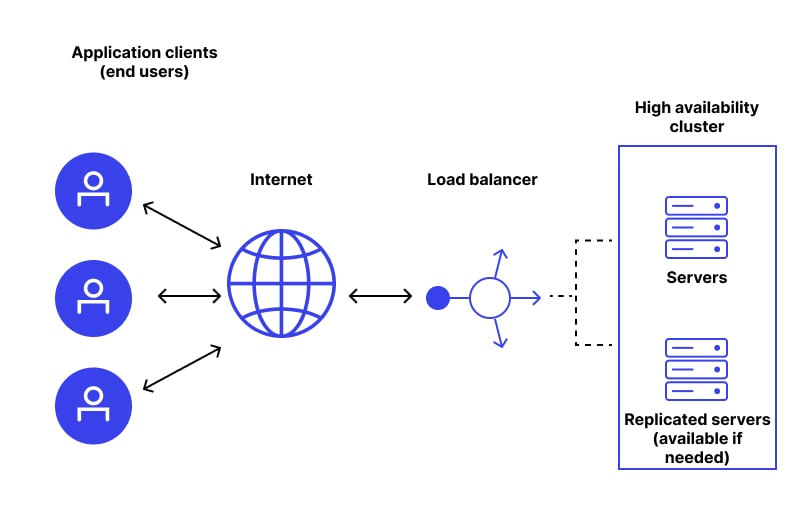
What Are High Availability Clusters?
It refers to the group of servers paired as a unified unit and operating by following a single set of instructions. As servers involved replace the failed server with a functional server without any intervention and breakdown, it’s also known as a failover cluster.
Note that every server in the HA cluster has shared storage and mission. However, these servers may work over a distinct network. Because of the same mission, servers use the same workloads to perform what needs to be done.
The key functions of a typical HA cluster includes:
- Ensuring server network availability always
- Automatically replacing the non-functional server with the next functional server
- Eliminating the point of failures
- Keeping downtime possibilities as low as possible
- Performing continued tests so that nodes are readily available
Generally, IT administrators adopt open-source programs for cluster health monitoring. The program does so by continuously forwarding the data packets to machines linked in a cluster and observing the response time.
As the system complexity increases, maintaining high-availability becomes tedious to achieve. Systems with more functional and moving components will have multiple hard-to-track failure points. Keep in mind that maintaining resource availability without being attentive toward quality has no worth.
Continually available apps with poor performance are not at good for an organization. So, HA should keep resource availability and quality performance at the pivot.
Now, let’s understand what high availability solutions are not. It’s not assuming that the IT system will never go down. Even with best practices, no HA can provide you 100% guarantee of system availability. It will try to extend the system availability but can’t make it 100%.
The Importance of High Availability (HA)
Introducing HA is hardly a bad deal for businesses. When applied strategically, it empowers the concerned organizations by all means possible. It is important for:
- Better market presence as your services/products will always remain functional
- Improved application performance as faults are detected and handled early
- Reduced data loss possibilities
- Saving huge operational overheads by avoiding failure
How Does High Availability Work?
Let’s understand its functionality in 3 steps:
- Step 1
It collects hardware and software resources more than standard requirements and uses them as backups. When certain resources fail, high availability will have a functional replacement ready. Without wasting a single second, high availability deploys the surplus resources in case of the breakdown of a certain component.
- Step 2
High availability keeps on carrying out regular system health checks. By doing so, it helps prevent any downfall or improper functionality is spotted at an early stage.
- Step 3
It constructs a highly optimized and mechanical failover strategy beforehand. When the primary system fails, this failover strategy transfers operations to the functional backup system automatically.
To perform these actions at the right time, HA demands very carefully planned testing. When HA is planned, almost every crucial aspect like network infrastructure, data, hardware, software, and so on are taken into consideration.
By taking everything on board, HA ensures that:
- There is no point of failure left that causes trouble in the future
- A dependable and fully automatic failover strategy is fabricated
- Responsive failure detection takes place
How Do You Measure High Availability?
HA implementation is not the solution to all the problems. Its upright implementation and functionality are a must. This is why organizations adopting HA are instructed to measure high availability at regular intervals.
In general, it’s measured by the activation/functional time of a system over a given period. The generic formula is:
Availability = (minutes in a month - minutes of downtime) * 100/minutes in a month
Looking for more details?
Here are a few metrics that will help you measure the efficacy of HA in real-time:
- Track MTBF or Mean Time Between Failure metrics to find out the anticipated time between two consecutive system failure incidence.
- You can track MDT or Mean Downtime as it indicates the average system non-functional time.
- RTO or Recovery Time Objective metric indicates the maximum time for which a system remains non-functional after a failure
- Lastly, we would suggest you track RPO or Recovery Point Objective metric. It represents the total data that can be compromised during a failure.
How To Achieve High Availability?
Organizations seeking maximum possible productivity must adopt HA and this is non-negotiable. While you plan to do this, here are the steps to follow.
- Step #1 - Design the strategy by giving full focus on HA
Your prime aim should be applying HA from the core. The HA system should be constructed so that the best performance conventions are achieved at the least possible cost.
- Step #2 - Have clear success metrics
Before moving any further, make sure that you’re aware of the extent to which you or your business need your systems to be available.
- Step #3 - Hardware should be well-aligned
The hardware used should be very resilient and manage to achieve quality at an optimized cost. The most preferred hardware here is hot pluggable and swappable hardware.
- Step #4 - Put the failover system under the test
After a successful HA system set-up, the designed system should undergo multiple viability tests to check its real-time operations.
- Step #5 - Do regress monitoring
With the help of the right metrics, track the performance of the HA system. Any unknown variance should be reported immediately.
- Step #6 - Assess regularly
Keep on collecting the performance data and monitor the systems’ behavior and efficiency. It heps ensure that your HA is improving as per the requirements.
High Availability vs Redundancy
Anyone involved in maintaining IT component health will encounter these two terms. While they have certain overlapping traits, they are not the same. While HA deals in ensuring around-the-clock IT system functionality, redundancy is all about increasing the system's dependency.
HA takes the help of practices like having a resource surplus, performing tests, and creating a failover strategy to achieve this goal. Redundancy, on the other hand, focuses on creating a duplicate copy of mission-critical IT components.
Redundancy refers to the duplication of critical components or functions of a system, intending to increase the reliability of the system. It is usually increased in the form of a backup or fail-safe, or to improve actual system performance.
HA can ensure system continuity alone, without redundancy. But, redundancy is hardly effective alone. It will need the support of failure detection to achieve better results.
Mostly, redundancy deals with hardware components of an IT ecosystem. HA is more about software components.
HA deals with all sorts of failures or downtime. The concerning area of redundancy always remains on the tactics to remove failure incidences.
High Availability vs Disaster Recovery
Just like HA, disaster recovery process helps make arrangements for organizations so that they can use available IT resources as much as possible. But, both adopt different approaches.
Clearly, HA is a preventive approach. It keeps things in a manner that failure doesn't happen in the first place. But, nothing is 100%.
When a downfall happens, disaster recovery shows up. It’s the practice of bringing compromised or down services on track as soon as possible.
It has a wide scope as compared to HA. The latter approach is limited to software while disaster recovery covers physical, virtual, and all sorts of damages that are happening.
Consider disaster recovery as a treatment while high availability is the prevention. HA is applied to prevent disasters while disaster recovery comes into the picture after an attack or failure takes place.
These two even have different approaches to assessing the situation. For instance, HA begins with the assumption that all is well and enough resources are there to deal with any failure. On the contrary, disaster recovery considers that everything is compromised or has been affected. Hence, everything needs a remedy.
They also have different metrics to use. Availability is more concerned with MTRS and MTBF metrics. But, disaster recovery is interested in RPO or RTO.
They have certain significant design differences. For instance, HA is designed with resource surplus to ensure that there are enough components to maintain continuity.
Disaster recovery is designed based on learning from previous failures. For instance, let’s say a server went down because of a poor firewall. Disaster recovery process will focus on building a server with no poor firewall. It learns from past mistakes and ensures that they are not repeated in new solutions.
High Availability v/s Fault Tolerance
If your goal is ensuring perfect IT system health, HA and fault tolerance implementation is imperative. We already know what high availability is. Let’s understand what fault tolerance is.
It denotes a system’s capacity to remain functional even if a system failure takes place. This also means a software capability to spot an error and find a way to recover from it.
Fault tolerance manages hardware and software components while high availability is mainly concerned with software components.
They two have different working principles. The working principle behind fault tolerance is the use of certain hardware so that hardware failures are detected early. With its help, faulty parts are replaced immediately.
HA adopts a different approach as the key principle here is to adopt various practices. Also, it has a surplus for immediate faulty software replacement.
As far as interruptions and operational costs are involved, fault tolerance features zero interruptions and high overheads. HA will have certain but bearable service interruptions but affordable overheads.
What Is A High Availability Load Balancer?
For Kubernetes High Availability or any other HA-concerning systems that have multiple simultaneous users, the load balancer is of great importance. By distributing the incoming traffic evenly, high-availability load balancers ensure that the burden is not on a single server.
It could be a hardware or a software component. In either case, it follows a certain algorithm to decide how the traffic load should be distributed. The three most preferred algorithms of load balancer are:
- Least Connection that picks the server handling minimum active action over a period.
- Round Robin is the algorithm that forwards the request to the first available server.
- The Source IP Hash algorithm considers the IP address of the incoming traffic while deciding which server should receive the request.
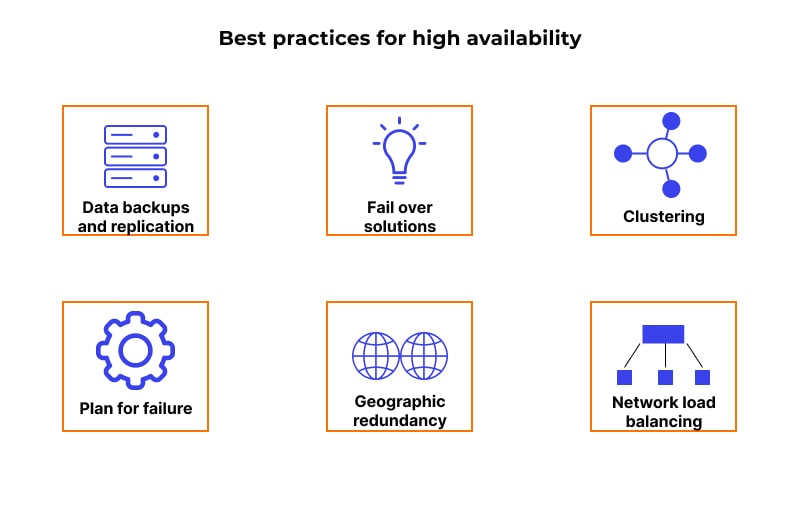
Best Practices for High availability
Achieving desired results from high availability architecture is only possible when it’s implemented in the right manner. Have a look at expert-recommended best practices for HA.
- In case of any dysfunctional point of failure/node, immediate elimination is required.
- Take regular data backups so that disaster recovery happens smoothly.
- Always use a load balancing approach as it ensures that each server is bearing an equal load. This reduces the failure possibilities.
- The Back-end databases server should be part of the HA system. Database high availability ensures data safety during a failure.
- Never keep all your resources at a specific location; distribute them across the globe, if possible.
- Have a responsive system that can detect an error at its beginning stage.
Conclusion
It’s the era where digital services and products are driving success. Thriving isn't possible with faulty, poorly performed, or always-low-performing systems. Organizations have to have the help of systems and IT infrastructure that remain functional in the maximum possible time.
We understand that 100% uptime is not possible. But, using a high availability server and upright implementation of HA ensure 99.99% uptime, which is great. Adopt this practice and improve your brand image, performance, operational expenses, and everything else.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")