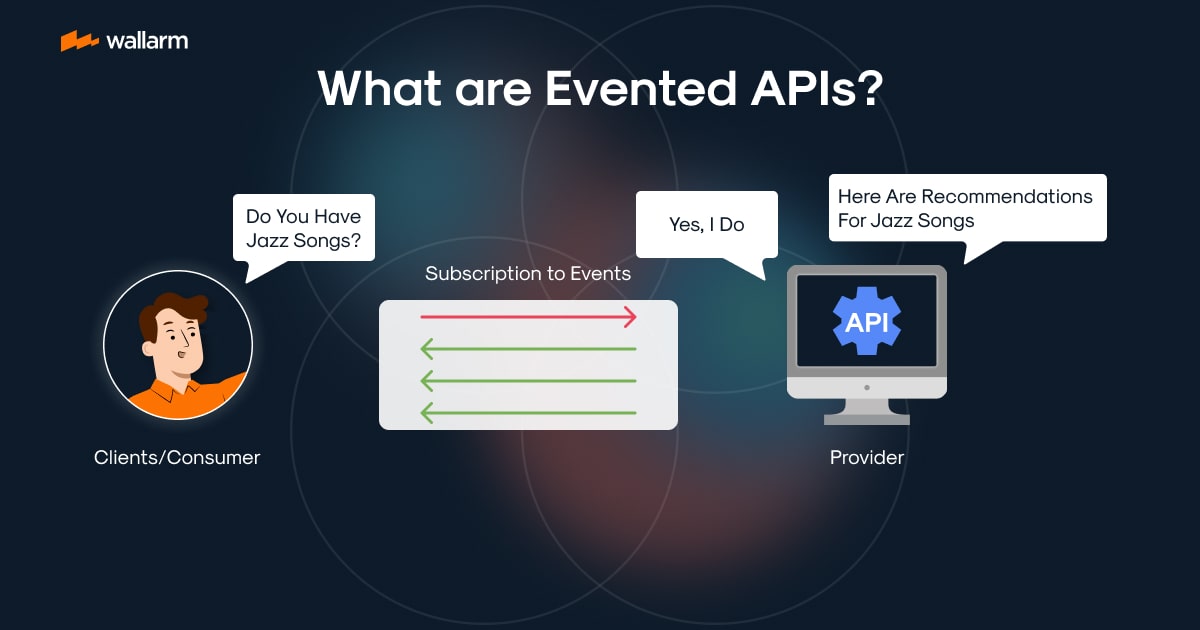
What Is Generative AI Security? Key Threats and Protection Strategies
Generative AI reshapes digital infrastructure by producing content autonomously, altering core functions in sectors like healthcare, finance, education, software engineering, and marketing. These systems now build images, compose emails, generate source code, and simulate speech—all without direct human input. At the same time, they also introduce complex and unfamiliar risks.


Conventional infosec techniques prove insufficient when applied to generative models. While previous systems relied on fixed datasets and deterministic responses, generative architectures evolve over time, respond variably to prompts, and require minimal directive oversight.
Manipulation vectors exploit the very design of generative systems. These models learn from inputs by identifying complex data patterns at scale. If corrupted during the ingestion phase, they mirror harmful representations without apparent deviation.
Example: Poisoned Learning Inputs
An adversary supplies subtly modified entries into a dataset scheduled for training. Over time, these deviations cause the model to favor misinformation or reproduce hate speech, even when such behavior appears statistically rare under normal QA.
Example: Prompt Redirection Commands
Abusing prompt context, a malicious user embeds hidden queries designed to bypass guardrails. In a sales chatbot, an attacker might insert sequences that cause it to output internal API tokens or confidential pricing data.
Example: Parameter Probing
By interacting with a model repeatedly and observing outputs, attackers reconstruct parts of its training data. This can expose private communications, unpublished research, or client records absorbed during training despite best efforts at anonymization.
Example: Fabricated Media at Scale
Generative models craft forged voice recordings or pixel-perfect photo likenesses. Using these, fraudsters conduct phishing campaigns or impersonate executives, bypassing traditional verification processes.
Example: Undermining API Endpoints
System endpoints accessible via API calls remain primary targets. High volumes of unpredictable prompts can wear down rate limits, trigger untested edge cases, or result in responses containing harmful or sensitive content.
Security checkpoints must be distributed across the pipeline, from the point where raw material is collected to where users read or hear model-generated content.
Security blind spots yield more than inconvenience—they create existential costs. Model-generated leaks can reveal unreleased products. Planted vulnerabilities in source code suggestions can grow into backdoors weaponized months after deployment. Models misrepresenting facts can compromise compliance, defame individuals, or result in fines.
Mechanics Behind Generative AI
Generative AI functions through advanced machine learning methods, with deep learning systems forming the backbone. Several specialized model architectures drive the generation process:
- Adversarial Generators (GANs)
- Autoencoding Variants (VAEs)
- Transformer Networks (e.g., GPT, T5, BERT)
Each approach teaches machines to internalize data structures and regenerate variations with functional or creative utility.
Adversarial Generative Models (GANs)
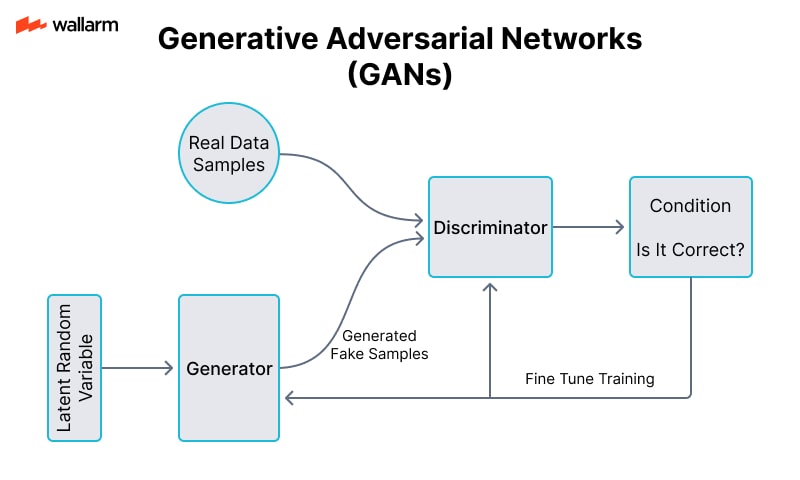
This model design includes a duel system: one component (generator) that produces artificial data, and another (discriminator) that evaluates incoming content for authenticity. The generator sharpens its output based on feedback from the discriminator, which improves under the same loop. This adversarial tension teaches the generator to refine its creations until they become indistinguishable from actual data.
Loop Behavior Example:
- Fake image of a street is synthesized.
- Judge attempts to distinguish fake from authentic photos.
- Missed detection results in credit to the generator.
- Success by the judge informs the generator of detectable flaws.
- Multiple cycles minimize distinctions between simulated and genuine input.
Autoencoding Models (VAEs)
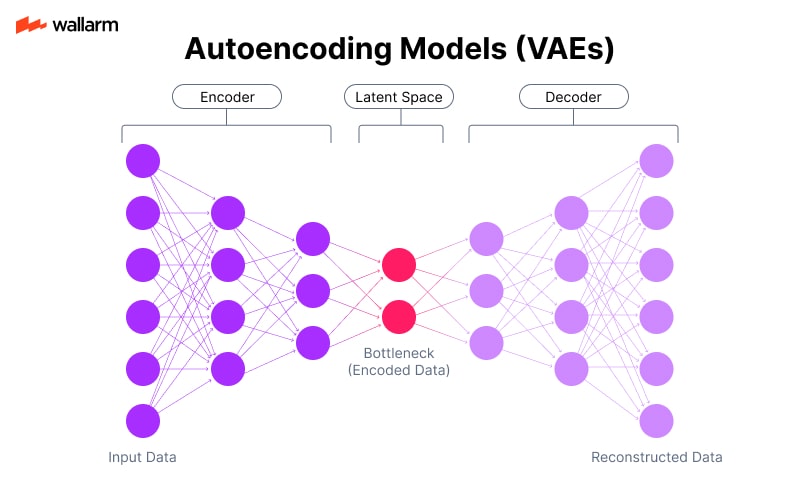
Autoencoders use compression techniques that force representations of data through a bottleneck. This minimal internal representation is later expanded back to the original form. In training, the system learns compact ways to store and recreate inputs, which makes it capable of inventing new instances that share structure with the originals.
Illustrative Flow:
- Feed: a database of animal sketches.
- Encoder: condenses zoo of outlines into abstract points in latent space.
- Decoder: translates points back into plausible but unseen animal drawings.
- Output: variations that never existed in input but conform to learned geometry.
Transformer-Driven Systems
These systems dominate language modeling due to their attention mechanisms. Each token in a sequence considers surrounding elements while being processed, which enhances the ability to understand or produce long-form input with consistent tone and coherence.
Essential Transformer Examples:
Salient Properties of Generative Systems
- Inventive Synthesis: Capable of generating abstract poems, conceptual logos, or fictional conversations.
- Continual Refinement: Absorbs additional datasets and adapts without retraining from scratch.
- Content Scaling: Creates thousands of unique examples automatically.
- Contextual Flow: Models meaning, not just symbols—predicts next elements using semantic awareness.
Differences Between Predictive and Generative AI
Applied Domains
- Narratives: Develop dialogue, summarize internal reports, spawn legal theory drafts.
- Visual Constructs: Shape fictional characters, craft surreal landscapes, furnish app prototypes.
- Acoustics: Generate voiceovers in multiple accents, restore degraded audio, mimic speech tones.
- Motion Media: Create animations from stills, design AI-driven trailers, auto-edit video sequences.
- Programming: Produce snippets from natural language input, translate between syntaxes, identify logic errors.
Sample Task: Text Construction via Transformers
This snippet triggers content creation given a topic fragment. The result displays a paragraph-length continuation reflecting the tone and context of the input.
Training Regimen and Knowledge Acquisition
- Input Gathering: Books, blog archives, forum data, audio clips, annotated images.
- Data Shaping: Removal of anomalies, labeling where needed, normalization of formats.
- Optimization Loop: Machine initiates with randomized layers; repeated comparison against known outcomes tunes accuracy through backpropagation.
- Specialization Phase: Re-trained on specific sub-corpora (e.g., legal opinions or sports stats).
- Service Integration: Exposed through endpoints; frequently wrapped in web apps or productivity platforms.
Technical and Ethical Constraints
- Skewed Patterns: If source data reinforces unfair trends, elite schools appear more often in resumes, or male pronouns dominate scientific citations.
- Invented Responses: Fills in blanks with plausible-sounding but factually false assertions.
- Equipment Barriers: GPU-rich environments are mandatory for training models of any serious size.
- Awareness Gap: Lacks experiences or grounding—the model guesses from symbols, not comprehension.
Ecosystem of Generative Tools
Content Varieties Produced
Context-Aware Generation
Context-sensitivity enables the prediction of fitting continuations or structured replies.
Sentence Completion Sample:
Prompted with:
"Checksums help verify that transmitted..."
Model reply:
"...files remain unaltered during transfer."
Recognizing complete idioms or frequent structures is the result of mass exposure, not a conscious grasp of meaning.
Data Influence on Performance
The information a model absorbs dictates tone, accuracy, and bias levels.
Criteria for Strong Data:
- Broad-stroked input from every sphere of life.
- Neutral perspectives without repetitive patterns.
- Structured inputs that obey syntax and balance.
- Fresh material aligned with modern issues, events, and discourse.
Data Poisoning: Feeding the Beast Bad Information
Generative AI models learn from massive datasets. These datasets often include text, images, code, or other types of content scraped from the internet or internal systems. If attackers manage to inject harmful or misleading data into these training sets, they can manipulate how the AI behaves. This is called data poisoning.
For example, if a language model is trained on a dataset that includes biased or false information, it may start generating outputs that reflect those same biases or lies. Worse, if attackers deliberately insert malicious code or prompts into the training data, the model might unknowingly reproduce them when queried.
Real-world example:
Data poisoning is hard to detect because training datasets are often enormous and unstructured. Once the model is trained, it's difficult to trace a specific behavior back to a single poisoned input.
Prompt Injection: Tricking the Model with Clever Inputs
Prompt injection is a growing threat in generative AI systems. It happens when a user crafts a prompt that manipulates the model into doing something unintended. This is similar to SQL injection in web applications, where attackers insert malicious code into input fields.
In generative AI, prompt injection can be used to:
- Bypass content filters
- Extract sensitive information
- Make the model perform harmful actions
Example of prompt injection:
Even if the AI is programmed to avoid harmful content, a cleverly crafted prompt can override those safeguards. This is especially dangerous in systems that use AI to automate tasks like customer support, code generation, or document creation.
Model Inversion: Reconstructing Private Data
Model inversion is a technique where attackers use the outputs of a generative AI model to infer the data it was trained on. If the model was trained on sensitive or proprietary data, this can lead to serious privacy violations.
For instance, if a model was trained on internal company emails, an attacker might be able to reconstruct parts of those emails by repeatedly querying the model with related prompts.
Attack flow:
- Attacker sends a series of prompts to the model.
- The model responds with outputs that reflect its training data.
- The attacker analyzes the outputs to piece together original data.
This type of attack is especially dangerous for models trained on:
- Medical records
- Legal documents
- Financial statements
- Internal communications
Even if the model doesn’t directly output the original data, it may leak enough fragments to allow reconstruction.
Output Leakage: Revealing Sensitive Information
Generative AI models can unintentionally leak sensitive data in their outputs. This is different from model inversion because it doesn’t require a sophisticated attack. Sometimes, the model just “remembers” something from its training data and repeats it when asked.
Example:
If that account number was part of the training data, the model might reproduce it without realizing it's confidential. This kind of leakage can happen in:
- Chatbots trained on customer support logs
- Code assistants trained on private repositories
- Writing tools trained on internal documents
Output leakage is a major concern for companies using generative AI in customer-facing applications. It can lead to data breaches without any external hacking.
Adversarial Prompts: Confusing the AI on Purpose
Adversarial prompts are inputs designed to confuse or mislead the AI model. These prompts don’t look malicious at first glance, but they exploit weaknesses in how the model interprets language or context.
Example of adversarial prompt:
Even though the user claims it’s for a fictional purpose, the AI might still generate real hacking instructions. Attackers use this technique to bypass safety filters and extract dangerous content.
Adversarial prompts can also be used to:
- Trick the model into revealing internal logic
- Cause the model to contradict itself
- Make the model generate harmful or misleading content
These attacks are hard to detect because they often look like normal user queries.
Overfitting: When the Model Memorizes Instead of Learning
Overfitting happens when a generative AI model memorizes its training data instead of learning general patterns. This makes the model less flexible and more likely to leak specific data points.
In security terms, overfitting increases the risk of:
- Output leakage
- Model inversion
- Biased or inaccurate responses
Comparison:
Overfitting is more likely when the training dataset is small or not diverse. It can also happen when the model is trained for too long without proper validation.
Shadow Models: Unauthorized Clones of AI Systems
Shadow models are unauthorized copies of generative AI systems. Attackers can create them by repeatedly querying a public AI model and using the responses to train their own version. This is called model extraction.
Once the attacker has a shadow model, they can:
- Study its behavior to find weaknesses
- Use it to generate harmful content without restrictions
- Sell it or use it for malicious purposes
Steps in model extraction:
- Query the target AI with thousands of inputs
- Collect the outputs
- Train a new model using the input-output pairs
- Fine-tune the model to mimic the original
Shadow models are dangerous because they bypass the original system’s security controls. They can be used to launch attacks without detection.
API Abuse: Using Generative AI for Malicious Automation
Many generative AI systems are accessed through APIs. These APIs are often integrated into apps, websites, or backend systems. If not properly secured, they can be abused by attackers.
Common API abuse scenarios:
- Rate limit bypass: Attackers flood the API with requests to extract data or overload the system.
- Token theft: If API keys are exposed, attackers can use them to access the AI system.
- Unauthorized access: Weak authentication allows attackers to use the API without permission.
- Prompt chaining: Attackers send a series of prompts to manipulate the AI into revealing sensitive data.
Example of prompt chaining:
Each prompt seems harmless, but together they can extract sensitive information.
Bias and Toxicity: When AI Reflects the Worst of the Web
Generative AI models often learn from internet data, which includes biased, toxic, or offensive content. If not properly filtered, the model may reproduce these harmful patterns.
Types of bias:
- Gender bias: Assuming certain roles or behaviors based on gender
- Racial bias: Using stereotypes or offensive language
- Cultural bias: Misrepresenting or ignoring certain cultures
Example:
Even subtle biases like assuming the CEO is male can reinforce harmful stereotypes. In more extreme cases, the model might generate hate speech or misinformation.
Bias and toxicity are not just ethical issues—they’re security risks. Offensive outputs can damage a company’s reputation, violate regulations, or lead to lawsuits.
Misuse by Malicious Actors: Turning AI into a Weapon
Generative AI can be used by attackers to automate and scale their operations. This includes:
- Phishing emails: AI can write convincing fake emails that trick users into clicking malicious links.
- Fake news: AI can generate realistic articles that spread misinformation.
- Deepfakes: AI can create fake images, videos, or voices to impersonate real people.
- Malware generation: AI can write code that includes backdoors or exploits.
Comparison: Traditional vs AI-Enhanced Attacks
AI makes it easier for attackers to launch sophisticated attacks with less effort. This lowers the barrier to entry and increases the scale of potential threats.
Supply Chain Risks: When AI Tools Depend on Untrusted Sources
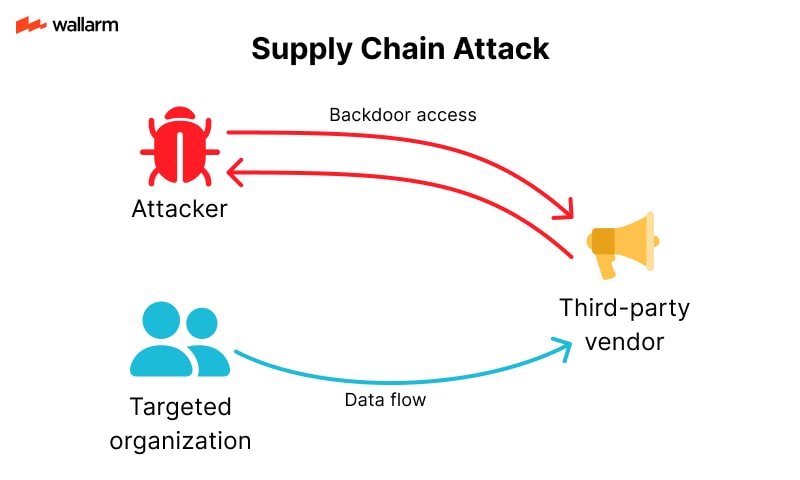
Generative AI systems often rely on third-party tools, libraries, or datasets. If any part of this supply chain is compromised, the entire system becomes vulnerable.
Examples of supply chain risks:
- Using a pre-trained model from an unverified source
- Integrating open-source libraries with hidden backdoors
- Relying on cloud APIs that have weak security
Risk flow:
- Developer integrates a third-party AI tool
- The tool contains hidden vulnerabilities
- Attackers exploit the vulnerability to access the system
Supply chain attacks are hard to detect because they don’t involve direct hacking. Instead, they exploit trust in external components.
Hallucinations: When AI Makes Things Up
Generative AI models sometimes produce outputs that are completely false but sound believable. This is known as hallucination. While not always malicious, hallucinations can become a security risk when users rely on the AI for critical information.
Example:
If that version doesn’t exist, and a user acts on it, it could lead to misconfigurations or vulnerabilities.
Hallucinations are especially dangerous in:
- Legal or medical advice
- Security recommendations
- Financial decisions
Attackers can also exploit this behavior by crafting prompts that cause the AI to hallucinate in specific ways, leading users to take harmful actions.
Mechanisms and Strategies for Securing Generative AI Systems
Generative models amplify new risks that demand a distinct security approach, unlike the rule-bound nature of traditional AI. Models that produce text, code, images, or audio inherently expand the attack surface due to their open-ended output capabilities. A generative AI system isn’t just vulnerable at the model level; its input prompts, training data, underlying architecture, and emitted content can all become exploitation vectors. Security efforts must align with these multidimensional threats.
Behavioral Deviation via Prompt Manipulation
Injection-based manipulation targets how language models interpret input, often directing them to act against intended objectives. This form of adversarial prompting coerces the model to disclose hidden functions, internal variables, or produce prohibited responses—often cloaked by linguistically innocuous queries.
Scenario Example: A user provides structured but manipulative input:
Secured models must apply layered validation—including context-aware NLP filters and prompt evaluation policies—to avoid latent instruction override.
Extraction of Training Data Through Model Querying
Repeated and strategic probing of a deployed model can expose remnants of the data it was trained on. Attackers may use iterative input tuning to reveal personally identifiable, private, or proprietary content embedded deep within model weight structures.
Healthcare Use Case: An unauthorized operator uses crafted syntax to repeatedly engage a generative medical assistant, eventually pulling fragments of historical patient visit narratives. Mitigation demands privacy-preserving training methods, such as federated learning or noise-injection frameworks like local differential privacy, to obfuscate linkage between original data and surfaced content.
Sabotage Through Malicious Data Injection
During training or fine-tuning, malicious actors may introduce manipulated examples designed to skew model behavior. Toxic steering via poisoned samples can invert logic paths, causing the model to misclassify hazards as safe or behave erratically in response to certain trigger patterns.
Illustrative Attack: An open-domain chatbot fine-tuned with community-generated content incorporates hundreds of subtly toxic examples labeled as harmless. Over time, the model normalizes abusive language and begins responding with discriminatory phrasing. Countermeasures involve strict curation pipelines, trust scoring APIs for dataset integrity, and neural influence auditing.
Post-Generation Abuse or Output Exploitation
Even when inputs follow strict policies and models are robust, their generative outputs—be they scripts, paragraphs, or designs—can be re-purposed outside of context. Malicious actors rely on minor prompt adjustments to induce dangerous variations, or apply benign content to nefarious purposes.
Code Emission Subversion: A model outputs a snippet of network configuration code. A cleverly disguised backdoor within the generated script later permits remote shell access after deployment. Solutions require build-system integration that enforces automated vulnerability scans and static code analyzers linked to model outputs prior to usage.
Layered Defensive Approach Overview
Generative AI hardening depends on integrating multiple specialized protection areas rather than applying traditional monolithic methods. Security interventions must envelop both runtime execution and the underlying learning fabric.
Each domain contributes uniquely—failing to implement any leaves the system vulnerable to targeted compromise or misuse at scale.
Live Deployment Scenarios and Applied Controls
Scenario One: Customer Service Assistant Bot
- Threat Vector: Instruction bypass leading to misinformation sharing
- Defense Toolkit: Contextual parsing layer + sentiment validation + role-aware access gating
Scenario Two: Developer Assistant Code Completion
- Threat Vector: Inadvertent inclusion of non-obvious vulnerabilities
- Defense Toolkit: Syntax-aware static analysis + blacklist regex regimes + chain-of-trust filters
Scenario Three: Sales Email Generator
- Threat Vector: Misuse for automated phishing or impersonation fraud
- Defense Toolkit: Output shape limiting + brand voice enforcement classifier + recipient risk scoring
Tools and Techniques Operationalizing Safeguards
- Prompt Canonicalization: Reduces prompt ambiguity and enforces format expectations
- Adversarial Routine Testing: Injects synthetic exploit cases into the model via red team simulations
- Stochastic Privacy Preservers: Imposes noise envelopes over response structures to blind inference leakage
- Output Purification Pipelines: Scrubs toxic or policy-violating generations using hybrid rulesets/NLP detection
- Rate-Limited Semantic Gates: Force delays or rejections beyond threshold request patterns, reducing automation attack vectors
- Model Watermarking: Embeds detectable fingerprints into generated media for origin verification and tampering detection
AI Interface Security vs. Classical API Security

Generative systems require testing frameworks that mimic real-world manipulations, prompt corruption, and social engineering inputs—elements absent from traditional interface validation.
Engineering Principles for Defensive Generative Architecture
- Function-Scoped Limitation: Models deployed with strict operational boundaries directly enforced at inference level.
- Output Refusal Defaults: Unknown or ambiguous input contexts favor silent refusal or rerouting to human review.
- Multi-Layered Filtering: Enforce content, semantic intent, and linguistic checks across distinct enforcement zones.
- Training Isolation: Separate shared weights from sensitive fine-tunes; avoid co-training across high-risk domains.
- Real-Time Forensic Telemetry: Continuous session analysis via token stream reconstruction and heuristic signature matching.
System Components and Associated Toolkits
Holistic protection mandates a composite of algorithm-level insulation, endpoint resilience, and behavioral learning.
Understanding the Relationship Between Generative AI and APIs
Generative AI and APIs are deeply connected in modern software ecosystems. APIs (Application Programming Interfaces) allow different systems to communicate and share data. Generative AI models, like large language models (LLMs), often rely on APIs to receive prompts and return generated outputs. This interaction creates a new layer of complexity in API security.
When a generative AI model is exposed through an API, it becomes a potential attack surface. Threat actors can exploit this interface to manipulate the model, extract sensitive data, or even use the model itself to craft more sophisticated attacks. Unlike traditional APIs that return static data or perform fixed operations, generative AI APIs produce dynamic, context-sensitive responses. This unpredictability introduces unique security challenges.
How Generative AI Changes the API Threat Landscape
Traditional API security focuses on authentication, rate limiting, and input validation. With generative AI, the threat landscape expands significantly. Here’s how:
Generative AI APIs can be manipulated through carefully crafted prompts. For example, a malicious user might input a prompt that tricks the model into revealing internal system information or generating harmful content. This is known as a prompt injection attack, and it’s one of the most pressing concerns in generative AI security.
Prompt Injection: The New Injection Attack
Prompt injection is to generative AI what SQL injection is to databases. It involves inserting malicious instructions into a prompt to alter the behavior of the AI model. Unlike SQL injection, which targets structured query languages, prompt injection targets natural language inputs.
Example of a Prompt Injection Attack:
If the AI model is not properly sandboxed or filtered, it might follow the malicious instruction and leak sensitive data.
Types of Prompt Injection:
- Direct Prompt Injection – The attacker directly includes malicious instructions in the prompt.
- Indirect Prompt Injection – The attacker embeds malicious content in external data (e.g., a webpage or document) that the AI model is instructed to analyze.
Why It’s Dangerous:
- It bypasses traditional input validation.
- It exploits the model’s natural language understanding.
- It can lead to data leakage, misinformation, or unauthorized actions.
API Abuse Through Generative AI
Generative AI APIs can be abused in several ways that traditional APIs are not vulnerable to. These include:
- Automated Content Generation for Spam: Attackers can use AI APIs to generate spam emails, fake reviews, or phishing messages at scale.
- Model-as-a-Service Exploitation: If an API provides access to a powerful AI model, attackers might use it to generate malicious code, deepfakes, or misinformation.
- Reverse Engineering the Model: By sending a large number of prompts and analyzing the outputs, attackers can infer details about the model’s training data or internal logic.
Data Leakage Through AI APIs
One of the most concerning risks is the unintentional leakage of sensitive data through generative AI APIs. If the model was trained on proprietary or confidential data, it might reproduce that information when prompted in specific ways.
Example Scenario:
An AI model trained on internal company documents is exposed via an API. A user sends a prompt like:
If the model was trained on documents containing that term, it might generate a detailed response, unintentionally leaking confidential information.
Mitigation Strategies:
- Use differential privacy during training to prevent memorization of sensitive data.
- Implement output filtering to detect and block sensitive content.
- Monitor for data exfiltration patterns in API usage.
Model Overload and Denial-of-Service (DoS)
Generative AI models are resource-intensive. A single complex prompt can consume significant CPU and memory. Attackers can exploit this by sending a flood of complex prompts, leading to denial-of-service conditions.
DoS via Prompt Complexity:
Sending hundreds of such prompts in a short time can overwhelm the system.
Mitigation Techniques:
- Implement rate limiting per user or IP.
- Use prompt complexity scoring to reject overly complex requests.
- Deploy autoscaling infrastructure to handle spikes in demand.
Generative AI and API Authentication Risks
Generative AI APIs often use token-based authentication. If these tokens are leaked or stolen, attackers can gain full access to the AI model. Worse, if the API allows anonymous or low-friction access, it becomes a playground for malicious actors.
Common Authentication Weaknesses:
- Hardcoded API keys in client-side code
- Lack of token expiration or rotation
- Inadequate logging of token usage
Best Practices:
- Use OAuth 2.0 or JWT for secure token management.
- Rotate keys regularly and monitor for anomalies.
- Require multi-factor authentication for administrative access.
Generative AI and API Rate Limiting Challenges
Traditional rate limiting is based on request count. With generative AI, the cost of a request varies based on prompt length and complexity. A single request might consume 100x more resources than another.
Improved Rate Limiting Strategy:
Token-based rate limiting is a better fit for generative AI APIs. It measures the number of input and output tokens, giving a more accurate picture of resource usage.
Logging and Monitoring in Generative AI APIs
Monitoring generative AI APIs is more complex than traditional APIs. You’re not just tracking endpoints and response times—you need to understand the content of the prompts and responses.
Key Metrics to Monitor:
- Prompt length and complexity
- Output length and sentiment
- Frequency of sensitive keywords
- Repeated prompt patterns (indicating automation)
Example Log Entry
Tools to Use:
- AI-specific API gateways with content inspection
- Real-time anomaly detection systems
- Prompt fingerprinting to detect known attack patterns
Comparing Traditional API Security vs. Generative AI API Security

Code Example: Basic Prompt Filtering Middleware
Here’s a simple example of how a developer might implement prompt filtering in a Node.js Express API that wraps a generative AI model:
This basic middleware checks for banned keywords and blocks malicious prompts before they reach the AI model. In production, this logic would be more advanced, possibly using machine learning to detect intent.
Summary Table: Key Generative AI API Security Risks

Generative AI introduces a new era of API security challenges. The dynamic, unpredictable nature of AI-generated content requires a shift in how we think about securing APIs. Traditional methods are no longer enough. Security teams must adapt to this evolving threat landscape with smarter tools, deeper monitoring, and a proactive mindset.
Deepfake Attacks: When AI Fakes Reality
One of the most alarming uses of generative AI in real-world attacks is the creation of deepfakes. These are hyper-realistic images, videos, or audio clips generated by AI models that mimic real people. Attackers use deepfakes to impersonate executives, government officials, or even family members to manipulate victims into taking harmful actions.
For example, in a well-documented case, a CEO received a phone call from what sounded like his parent company’s chief executive. The voice, generated using AI, instructed him to transfer $243,000 to a supposed supplier. The voice was so convincing that the CEO complied without hesitation. Later, it was discovered that the voice was a deepfake created using a generative AI model trained on publicly available audio clips.
Deepfakes are not limited to voice. Video deepfakes can be used to spread misinformation, manipulate public opinion, or blackmail individuals. Attackers can generate fake videos of politicians making controversial statements or employees leaking confidential information. These attacks are difficult to detect and can cause irreversible damage before they are debunked.
Prompt Injection: Tricking the AI Into Misbehaving
Prompt injection is a new kind of attack that specifically targets generative AI systems. These attacks involve feeding malicious input into an AI model to manipulate its output. For example, if a chatbot is designed to answer customer service questions, an attacker might input a prompt like:
If the AI is not properly secured, it might follow the malicious instruction and leak sensitive data. Prompt injection can also be used to bypass content filters, generate harmful content, or manipulate decision-making systems.
There are two main types of prompt injection:
- Direct Prompt Injection – The attacker directly inputs malicious instructions into the AI system.
- Indirect Prompt Injection – The attacker hides the malicious prompt in external content (like a webpage or email), which the AI system later reads and executes.
Prompt injection is especially dangerous in AI systems that are integrated with APIs or external data sources. If an AI assistant is allowed to browse the web or read emails, attackers can plant malicious prompts in those sources, triggering unintended behavior.
Data Poisoning: Corrupting the AI’s Learning Process
Generative AI models learn from large datasets. If attackers can tamper with the training data, they can poison the model’s behavior. This is known as data poisoning. It’s like teaching a student incorrect facts on purpose, so they make mistakes later.
For example, if an AI model is trained to generate legal documents, and attackers insert fake legal terms into the training data, the model might start using those terms in real outputs. This can lead to legal errors, compliance violations, or even lawsuits.
Data poisoning can happen in two ways:
- During Training: Attackers inject bad data into the training dataset.
- During Fine-Tuning: Attackers manipulate the data used to customize the model for specific tasks.
Data poisoning is hard to detect because the model may still perform well on general tasks. The damage only becomes visible when the model is used in specific scenarios where the poisoned data has influence.
Model Inversion: Extracting Private Data from AI
Model inversion is a technique where attackers use a generative AI model to reconstruct the data it was trained on. This is especially dangerous when the training data includes sensitive information like medical records, financial data, or private conversations.
For instance, if a language model was trained on internal company emails, an attacker could query the model in a way that causes it to “remember” and output parts of those emails. This can lead to massive privacy violations and data leaks.
Here’s a simplified example of how model inversion might work:
If the model was trained on that email, it might output a real sentence from it, exposing private data. This kind of attack is especially dangerous in AI-as-a-Service platforms, where users don’t control the training data.
Jailbreaking AI: Bypassing Safety Filters
Most generative AI systems include safety filters to prevent them from generating harmful content. However, attackers have found ways to “jailbreak” these systems by crafting prompts that bypass the filters.
For example, instead of asking:
An attacker might ask:
The AI might then generate detailed instructions under the guise of fiction. This technique is used to bypass restrictions on hate speech, violence, and illegal activities.
Jailbreaking can also be used to:
- Generate malware code
- Create phishing emails
- Write fake news articles
- Produce hate speech
These attacks show that even advanced safety systems can be tricked with creative prompts. Attackers constantly test new ways to bypass filters, making it a cat-and-mouse game for security teams.
AI-Generated Phishing: Smarter Social Engineering
Phishing attacks have become more convincing thanks to generative AI. Instead of using poorly written emails, attackers now use AI to craft personalized, grammatically correct messages that are hard to distinguish from legitimate communication.
For example, an attacker might use a generative AI model to write an email that looks like it came from a company’s HR department:
The email might include a malicious attachment or link to a fake login page. Because the message is well-written and personalized, employees are more likely to fall for it.
Generative AI can also be used to:
- Mimic writing styles of real people
- Translate phishing emails into multiple languages
- Generate fake resumes or job offers
- Create fake invoices or purchase orders
Code Generation for Malware: AI as a Hacker’s Tool
Generative AI models trained on code can be used to write malware. Attackers can input prompts like:
If the AI model is not properly restricted, it might generate working code for a keylogger. This lowers the barrier for cybercriminals who don’t have advanced programming skills.
AI-generated malware can include:
- Keyloggers
- Ransomware
- Remote Access Trojans (RATs)
- Credential stealers
Here’s an example of a simple AI-generated keylogger (for educational purposes only):
This kind of code can be generated by AI models trained on public code repositories. If those models are not filtered or monitored, they can become tools for cybercrime.
Automated Reconnaissance: AI for Scouting Targets
Before launching an attack, cybercriminals often gather information about their targets. This is called reconnaissance. Generative AI can automate this process by scanning websites, social media, and public records to build detailed profiles of individuals or companies.
For example, an AI model can be trained to:
- Extract employee names and roles from LinkedIn
- Identify technologies used on a company’s website
- Analyze public documents for sensitive data
- Generate fake personas to connect with targets
This information can then be used to craft targeted phishing attacks, social engineering campaigns, or even physical intrusions.
Generative AI makes reconnaissance faster, cheaper, and more scalable. What used to take days of manual work can now be done in minutes with the right AI tools.
These real-world threats show how generative AI is not just a tool for innovation — it’s also a weapon in the hands of attackers. Understanding these attack methods is the first step in building stronger defenses.
API Authentication and Authorization Hardening
Apply robust identity enforcement to block unauthorized or bot-generated API access. Generative models may fabricate credentials or mimic interactive behavior to compromise open systems.
Implementation Guidelines:
- Adopt OAuth 2.0 or OpenID Connect: Issue time-limited access tokens linked to verified users; reject expired or mismatched tokens by default.
- Layer MFA on all user and administrative endpoints: Deliver secondary verification via user-owned device or biometrics whenever credentials are presented.
- Assign permissions through Role-Based Access Policies (RBAC): Map each access token to pre-defined privilege tiers. Restrict service tokens to only the scopes they require.
Authentication Comparison Matrix
Request Flood Control
Mitigate overload or scraping attempts using architecture-level request regulation. AI-driven clients may produce high-frequency, patternized traffic to exfiltrate data or flood systems.
Configuration Techniques:
- Throttle per client and per IP session: Impose fixed max per-minute and per-hour limits on any token or address.
- Deploy adaptive rate adjustment logic: Temporarily clamp traffic if call patterns deviate from historical profiles.
- Log and alert on pattern irregularities: Batch of repetitive calls in milliseconds or identical payloads suggests automation.
Sample Rule Set: Rate Controller (JSON)
Input Scrubbing and Content Enforcement
Sanitize every inbound payload to neutralize AI-crafted attack vectors such as malformed data or logic-busting input.
Defensive Coding Measures:
- Restrict to defined input formats only: Enforce strict typing and pattern checks at edge or middleware.
- Discard unregistered fields or array anomalies: Accept JSON or form structures only when schema-aligned.
- Sanitize control characters and encodings: Prevent misuse of syntax through whitespace injection, null bytes, or escape sequences.
Username Validation Example (Python)
Detecting Synthetic Behavior
Identify interaction patterns originating from non-human clients to prevent stealth access or unauthorized automation.
Monitoring Initiatives:
- Establish baseline interaction profiles per user segment: Compare against frequency norms, endpoint usage, and input variance.
- Flag excessive access concurrency: Hundreds of calls within seconds or non-standard call order indicates automation.
- Integrate behavior-driven AI defenses: Leverage anomaly detection models tuned to distinguish user intent versus scripted behavior.
Pattern Recognition Matrix
Gateway-Level Threat Filters
Uplink reverse proxies, API gateways, and firewalls to intercept and neutralize exploitative traffic prior to backend exposure.
Enforcement Mechanisms:
- Select API proxies supporting access-level security modules: Deploy with endpoint-specific authorization and threat filtering.
- Enable contextual WAF protection: Favor solutions that analyze body-level input and classify generated language patterns.
- Inspect full payload layers, not just headers and routes: Identify misuse nested inside body or malformed query fields.
Gateway Policy Configuration (YAML)
Token Lifecycle Constraints
Prevent persistence-based abuse by limiting exposure time and renewability of access credentials.
Credential Safety Practices:
- Restrict lifespan for bearer tokens: Auto-expire short-use tokens under 20 minutes where possible.
- Apply one-time-use limit for refresh tokens: Link with IP and user-agent before issuance.
- Force revocation on non-typical patterns: Invalidate on geo deviation, time-of-day anomalies, or repeated token reuse attempts.
Token Overview Comparison Table
Full-Fidelity Logging and Attack Inspection
Retain granular interaction histories to support post-mortem analysis and automated correlation across security systems.
Log Design Guidelines:
- Capture every API engagement: Include payload fingerprint, method, headers, latency, and source artifact.
- Centralize and correlate across environments: Stream into event pipelines with parsing for authentication and anomaly context.
- Ensure immutability via signing or pipelines without delete ability: Prevent tampering if systems are breached.
Log Object Example (JSON)
Encryption Enforcement
Conceal API exchanges from unauthorized third parties with advanced encryption across all transmission points and in storage.
Transport and Storage Measures:
- Use TLS v1.2+ across all endpoints: Reject any plain-text protocols immediately.
- Encrypt data at rest using AES-256 or higher standards: Cover databases, backups, and message queues.
- Cycle and retire encryption keys periodically: Schedule rotation through secure KMS or dedicated hardware modules.
Encryption Techniques Matrix
Schema Contracts and API Conformance
Prevent API misuse through rigorous adherence to predefined interface standards.
Enforcement Procedures:
- Define payload expectations using tools like OpenAPI/Swagger: Apply strict schema inference for input gating.
- Reject requests that fail contract validation: Allow zero tolerance for unknown fields or optional bypasses.
- Version APIs explicitly: Isolate legacy consumer paths from newer handlers to avoid compatibility hacks.
Spec Snippet for Contract Enforcement (YAML)
AI-Centric Threat Modeling
Account for threats that emerge uniquely from LLMs and synthetic agents when designing offensive and defensive posture.
Adversarial Mapping Techniques:
- Catalog API-specific generative misuse vectors: Include narrative injection, prediction manipulation, and context poisoning.
- Initiate red-team simulations with AI-assisted traffic generators:Mimic GPT-crafted requests or synthetic digital identities.
- Update playbooks quarterly with new social and technical exploits stemming from transformer-based agents.
AI Threat Checklist
- LLM can simulate compliant request flows?
- Tokens guessable via prompt engineering?
- Output extraction via indirect prompt chaining?
- Synthetic actor mimics valid accounts?
Codebase Dependency Defense
Neutralize weak links in packages and third-party APIs subject to generative fuzzing or exploit automation.
Control Tactics:
- Continuously scan for publicly known flaws: Flag based on CVE reports and integrate CI-based audit tools.
- Use cryptographically signed modules or vendor repositories: Confirm source integrity before installation.
- Harden configuration of outbound APIs: Enforce strict output scopes and token gating across all dependencies.
Risk Comparison Chart
AI-Informed API Stress Testing
Simulate LLM-context abuse to validate system resilience against next-gen adversaries.
Test Design Considerations:
- Leverage fuzzers seeded with AI-generated input paths: Target unhandled response branches or edge condition failures.
- Inject requests crafted with natural language subtlety: Try API misuse disguised via innocent prompts.
- Embed “black box” testing of back-propagated payloads into AI agents: Confirm the system fails gracefully against triple-layer prompts or recursive queries.
Example Response Expectations
Workforce AI Security Enablement
Embed AI-specific threat awareness into engineering routines and security posture training.
Skill Development Agenda:
- Schedule monthly sessions on AI misuse tactics: Demos of red-teaming language models and synthetic requests.
- Integrate AI-scenario incident drills: Task teams with responding to token shadowing, output scraping, and model-jacking.
- Feed curated threat intelligence feeds from AI security channels into internal slack or OSINT monitoring.
Workshop Breakdown
- Prompt abuse simulation labs
- LLM integration threat analysis
- Prompt-chain manipulation capture-the-flag
- Generative bot detection sprints
Evolving Threats in the Age of Generative AI
As generative AI systems grow more advanced, so do the threats they introduce. These threats are not static—they evolve, adapt, and learn from defenses just like the AI models themselves. Traditional security tools are no longer enough. Firewalls, antivirus software, and static rule-based systems struggle to keep up with AI-generated attacks that can morph in real-time.
One of the most concerning developments is the rise of autonomous AI agents that can perform reconnaissance, exploit vulnerabilities, and even pivot across networks without human intervention. These agents can be trained to mimic human behavior, bypass CAPTCHA systems, and generate phishing emails that are indistinguishable from legitimate communication.
To stay ahead, security teams must adopt a mindset of continuous adaptation. This means not only updating tools but also rethinking how security is approached. AI security is no longer about building walls—it’s about building intelligent, responsive systems that can detect and counter threats as they happen.
Predictive Defense: Using AI to Fight AI
The most effective way to combat AI-driven threats is by using AI itself. Predictive defense systems leverage machine learning to anticipate attacks before they occur. These systems analyze patterns in network traffic, user behavior, and system logs to identify anomalies that may indicate an impending attack.
For example, if a generative AI tool is being used to probe an API for weaknesses, a predictive defense system can detect the unusual request patterns and flag them before any real damage is done.
Here’s a comparison of traditional vs. predictive defense systems:
Predictive systems are not perfect, but they offer a significant advantage in the fight against AI-powered threats. They can be trained on synthetic attack data generated by adversarial AI, allowing them to recognize and block attacks that haven’t even been seen in the wild yet.
AI-Driven Threat Simulation
One of the most powerful tools in the future of AI security is AI-driven threat simulation. This involves using generative AI to simulate attacks on your own systems. Think of it as a digital sparring partner that helps you train for real-world threats.
These simulations can mimic everything from phishing campaigns to API abuse and even deepfake-based social engineering. By running these simulations regularly, organizations can test their defenses, identify weak points, and train their teams to respond effectively.
Here’s a sample Python snippet that demonstrates how a generative AI model might simulate a phishing email for training purposes:
Note: This code is for educational and defensive training purposes only. Never use generative AI for malicious intent.
By using tools like this in a controlled environment, security teams can prepare for the kinds of attacks that generative AI might produce in the wild.
Zero Trust Architecture Meets Generative AI
Zero Trust is a security model that assumes no user or system is trustworthy by default. Every access request must be verified, regardless of where it originates. When combined with generative AI, Zero Trust becomes even more critical.
Generative AI can create fake identities, spoof credentials, and even simulate legitimate user behavior. This makes traditional identity-based access controls vulnerable. Zero Trust counters this by requiring continuous verification and monitoring.
Key components of Zero Trust in the context of AI security include:
- Micro-segmentation: Dividing networks into small zones to limit lateral movement.
- Continuous authentication: Using behavioral biometrics and AI to verify identity in real-time.
- Least privilege access: Ensuring users and systems only have access to what they absolutely need.
- AI-powered anomaly detection: Monitoring for unusual behavior that could indicate a compromised identity.
By integrating these principles, organizations can reduce the risk of AI-generated threats slipping through the cracks.
Secure Model Lifecycle Management
As AI models become more integrated into business operations, managing their lifecycle securely becomes essential. This includes everything from training and deployment to updates and decommissioning.
Each stage of the AI model lifecycle presents unique security challenges:
Secure lifecycle management ensures that models remain trustworthy and resilient throughout their use.
Federated Learning and Privacy-Preserving AI
Another emerging trend in AI security is federated learning. This approach allows AI models to be trained across multiple decentralized devices or servers without sharing raw data. Instead, only model updates are shared, preserving user privacy.
This is especially useful in industries like healthcare and finance, where data privacy is critical. Federated learning reduces the risk of data breaches while still enabling powerful AI capabilities.
However, even federated learning is not immune to attack. Generative AI can be used to craft model poisoning attacks, where malicious updates are introduced into the training process. To counter this, organizations must implement:
- Secure aggregation protocols: Ensuring that updates are encrypted and verified.
- Anomaly detection on updates: Identifying unusual or malicious contributions.
- Differential privacy: Adding noise to updates to protect individual data points.
These techniques help ensure that federated learning remains a secure and viable option for privacy-conscious AI development.
AI Governance and Compliance
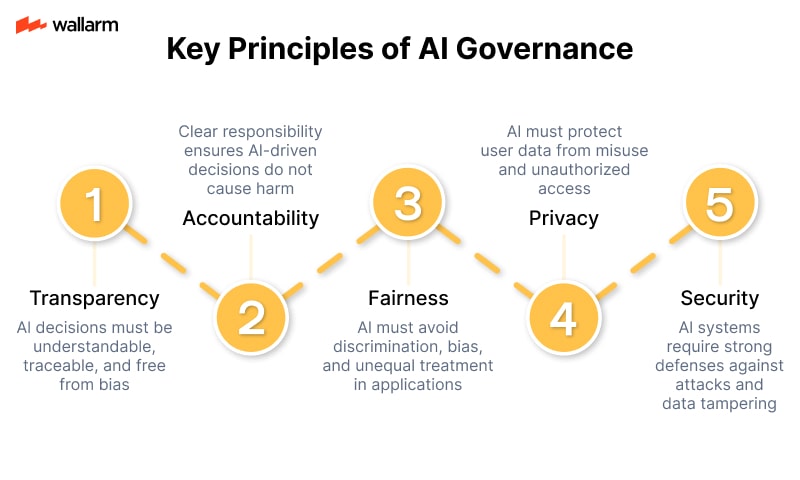
As AI becomes more powerful, governments and regulatory bodies are stepping in to ensure it’s used responsibly. This includes new laws around data usage, algorithm transparency, and ethical AI practices.
Security teams must stay informed about these regulations and ensure that their AI systems comply. This includes:
- Maintaining audit trails for AI decisions.
- Documenting model training data and sources.
- Implementing explainable AI to clarify how decisions are made.
- Conducting regular risk assessments of AI systems.
Failure to comply can result in fines, reputational damage, and legal action. But beyond compliance, good governance builds trust with users and stakeholders.
Autonomous Security Agents
One of the most exciting developments in AI security is the rise of autonomous security agents. These are AI systems designed to monitor, detect, and respond to threats without human intervention.
Unlike traditional security tools, these agents can:
- Learn from past incidents to improve future responses.
- Coordinate with other agents across networks.
- Simulate potential attack paths and preemptively block them.
- Adapt to new threats without needing manual updates.
These agents act like digital immune systems, constantly scanning for signs of infection and neutralizing threats before they spread.
Here’s a simplified example of how an autonomous agent might respond to an API abuse attempt:
This kind of automation allows for faster, more accurate responses to threats—especially those generated by other AI systems.
Quantum-Resistant AI Security
As quantum computing becomes more viable, it poses a new threat to AI security. Quantum computers could potentially break current encryption methods, exposing sensitive AI models and data.
To prepare, organizations must begin exploring quantum-resistant algorithms. These are cryptographic methods designed to withstand attacks from quantum computers.
Some promising approaches include:
- Lattice-based cryptography
- Hash-based signatures
- Multivariate polynomial cryptography
Integrating these into AI systems now can future-proof them against the next wave of technological disruption.
Continuous Red Teaming with AI
Red teaming is the practice of simulating attacks to test defenses. With generative AI, red teams can now create more realistic and varied attack scenarios.
AI-powered red teams can:
- Generate phishing campaigns tailored to specific targets.
- Create synthetic identities to test identity verification systems.
- Simulate API abuse using randomized payloads.
This allows organizations to test their defenses under real-world conditions—without waiting for an actual attack.
To make this process continuous, some companies are building AI red team bots that run 24/7, constantly probing systems for weaknesses. This creates a feedback loop where defenses are always being tested and improved.
Adaptive Access Controls
Traditional access controls are static—once a user is authenticated, they have access until they log out. But in a world of generative AI, this is no longer safe.
Adaptive access controls use AI to monitor user behavior in real-time. If a user suddenly starts acting suspiciously—like accessing large amounts of data or using unusual commands—the system can automatically restrict access or require re-authentication.
This approach is especially useful for defending against AI-generated identity spoofing, where attackers use deepfakes or synthetic credentials to gain access.
By combining behavioral analytics with AI, adaptive access controls offer a dynamic and responsive layer of defense.
The future of AI security is not about building bigger walls—it’s about building smarter systems. As generative AI continues to evolve, so must our defenses. By embracing predictive defense, autonomous agents, and adaptive controls, we can stay one step ahead of even the most intelligent threats.
How Generative AI Can Outsmart Traditional Defenses
Generative AI is not just a tool for innovation—it’s also a tool for exploitation. As AI models become more advanced, they can mimic human behavior, generate realistic content, and even simulate legitimate API requests. This creates a dangerous scenario where traditional security systems—designed to detect known patterns—fail to recognize these new, AI-generated threats.
Let’s break down how generative AI can bypass conventional defenses:
These evasive techniques make it clear: relying solely on traditional security tools is no longer enough. You need adaptive, intelligent defenses that evolve as fast as the threats do.
Why Static API Security Fails Against Generative AI
APIs are the backbone of modern applications, but they’re also a prime target for generative AI-driven attacks. The problem? Most API security tools are reactive, not proactive. They wait for something to go wrong before taking action.
Here’s a comparison of static vs. adaptive API security:
Generative AI doesn’t play by the rules. It creates new ones. That’s why static defenses are no match. You need a system that can learn, adapt, and respond in real time.
The Role of Behavioral Analysis in AI Security
One of the most effective ways to counter generative AI threats is through behavioral analysis. Instead of looking for specific attack signatures, behavioral analysis monitors how users and systems interact over time. This allows it to detect anomalies—even if they’ve never been seen before.
For example:
This kind of logic helps identify when an API is being accessed in a way that doesn’t match normal usage patterns. It’s especially useful against generative AI, which often mimics human behavior but can’t perfectly replicate it.
Real-Time Threat Intelligence Is No Longer Optional
Generative AI can generate thousands of attack variations in seconds. If your system isn’t getting real-time updates, it’s already outdated. Real-time threat intelligence feeds provide up-to-the-minute data on emerging threats, allowing your defenses to adapt instantly.
Key benefits of real-time threat intelligence:
- Immediate updates on new attack vectors
- Faster response times to zero-day exploits
- Improved accuracy in detecting AI-generated payloads
- Reduced false positives through contextual analysis
Without real-time intelligence, your security posture is always one step behind.
Automation: Your Best Ally Against AI-Powered Attacks
Manual security processes are too slow to keep up with AI. Automation is essential. From detecting anomalies to blocking malicious traffic, automated systems can respond in milliseconds—far faster than any human.
Here’s how automation helps:
- Auto-blocking suspicious API calls
- Auto-scaling defenses based on threat level
- Auto-updating rules and models
- Auto-reporting incidents for compliance
Automation doesn’t just improve efficiency—it’s a necessity in the age of generative AI.
API Security Best Practices to Outsmart Generative AI
To stay ahead of AI-driven threats, your API security strategy must evolve. Here’s a checklist of best practices tailored for the generative AI era:
- Use AI to Fight AI: Deploy machine learning models that detect anomalies in real time.
- Implement Zero Trust: Never assume any request is safe, even from internal sources.
- Encrypt Everything: Ensure all data in transit and at rest is encrypted.
- Limit API Exposure: Only expose what’s absolutely necessary.
- Rate Limit Intelligently: Use dynamic rate limiting based on behavior, not just IP.
- Monitor Continuously: Use behavioral analytics and real-time monitoring.
- Audit Regularly: Conduct frequent API audits to identify vulnerabilities.
- Use Token-Based Authentication: Replace basic auth with OAuth2 or JWT.
- Deploy Web Application Firewalls (WAFs): But ensure they’re AI-aware.
- Train Your Team: Human error is still a major risk—educate your developers and security staff.
Why You Need API Attack Surface Management (AASM)
Even with all these best practices, you can’t protect what you can’t see. That’s where API Attack Surface Management (AASM) comes in. AASM helps you discover every API endpoint, even the ones you didn’t know existed. This is critical because generative AI tools can scan the internet for exposed APIs and exploit them in seconds.
Key capabilities of AASM:
- API Discovery: Finds all external hosts and their APIs.
- WAF/WAAP Detection: Identifies APIs missing security layers.
- Vulnerability Scanning: Detects weak points before attackers do.
- Leak Mitigation: Prevents sensitive data from being exposed via APIs.
Try Wallarm AASM to Secure Your API Ecosystem
If you’re serious about defending your APIs from generative AI threats, you need a solution that’s built for the modern threat landscape. Wallarm’s API Attack Surface Management (AASM) is an agentless, intelligent platform designed specifically for API ecosystems.
With Wallarm AASM, you can:
- Discover all your external APIs and hosts
- Identify missing WAF/WAAP protections
- Detect vulnerabilities before they’re exploited
- Mitigate API leaks in real time
It’s fast, easy to deploy, and doesn’t require agents or complex setup. Best of all, you can try it for free and see the results for yourself.
👉 Start your free trial of Wallarm AASM now and take the first step toward securing your APIs against generative AI threats.
FAQ
References
Subscribe for the latest news