What is Fault Tolerance? 3 Techniques & Definition
We now live in a computerized space and ideas like adaptation to fault tolerance have begun to turn out to be progressively famous because of their significance. Adaptation to fault tolerance is an idea that ought to be consolidated into various frameworks to guarantee that they can work with no hitches. Adaptation to non-critical failure alludes to an interaction that has effectively been set up to react when there is a disappointment in the product or equipment of the framework.


What is Fault Tolerance?
Fault Tolerance or Adaptation to non-critical failure is a term that is utilized to allude to the in-fabricated capacity of an organization to keep working regardless of the disappointment or crash of one of its segments. The thinking behind making an issue open-minded framework is to forestall breakdowns that are brought about by a specific explanation, ensuring that the framework is consistently accessible and the business can keep on working with the most fundamental applications still inactivity.
Issue open-minded frameworks are intended to embrace reinforcement segments that will fill in for the bombed gadgets, to ensure that there is no break in transmission. An illustration of these flaw lenient framework incorporates:
- Hardware Systems: These are the sorts of that are upheld up or upheld by an indistinguishable or identical framework. For example, a worker can be intended to be flaw open-minded and safe to framework crashes by introducing another worker that is running in corresponding with it. The reinforcement worker will screen and mirror the activities of the principal worker if there are any difficulties with the framework.
- Software frameworks: These are the frameworks that are supported by utilizing programming apparatuses and materials. For instance, a data set that is loaded up with client data can be effectively repeated on another machine and refreshed routinely. On the off chance that the essential data set of data is bad a falls flat, activities would naturally be moved to the reinforcement programming information base.
- Power Sources: This hardware is intended to be issue-safe by embracing elective sources to control your framework. This implies that when there is an interference with a specific light source, you can change to another. For example, various associations own force-producing sets that they can turn on when the fundamental power supply falls flat.
Parts of a Fault-Tolerant System
The primary advantage of planning a flaw lenient framework is to minimize or stay away from the danger of an all-out vacation or framework disappointment. It additionally assists with staying away from the danger of the framework being distant because of a spoilt part. Adaptation to fault tolerance is particularly significant in basic frameworks, for example, those used to get individuals' lives. Instances of these frameworks are air traffic and frameworks that handle basic information and boundaries for everyday exchange.
The center parts of a flawed open-minded framework are:
- Diversity
This includes setting up a reinforcement framework that is separated from the principle framework being referred to. On the off chance that the primary power supply of a framework is removed because of a tempest or issues at the force station. In this sort of situation, there is a requirement for an extraordinary power source. This is the place where variety comes to play, as the frameworks can be turned on with an elective force source like a reinforcement generator.
The variety in adaptation to fault tolerance could likewise imply that the reinforcement can not work on a similar limit as the essential source. Sometimes, this may expect administrators to remove a portion of the tasks of the framework till the principle power is reestablished.
- Redundancy
Deficiency lenient frameworks may some of the time use excess to wipe out a weak link. For example, consider a framework that has at least one force supply unit (PSUs) which don't all should be active for the framework to work. At the point when the essential PSU falls flat or gets defective, it very well may be supplanted with another unit, and activities will go on unfastened.
Likewise, it's feasible to execute repetition at a framework level. This would mean setting up a completely extraordinary PC framework to take over in the event of an accident.
- Replication
Replication is a more troublesome way to deal with applying when utilizing adaptation to non-critical failure. It's an approach that is worried about utilizing various variants of a solitary framework or the formation of subsystems. These frameworks are to be planned to such an extent that their capacities consistently lead to indistinguishable outcomes. If the outcomes are not indistinguishable, then, at that point a choice interaction should be utilized to recognize and select this defective framework.
Replication can be arranged at the part level where we will have various processors running all the while to accomplish a comparable outcome or at the framework level, which includes setting up different PC frameworks to work simultaneously.
How Does Fault Tolerance Work?
Adaptation to fault tolerance is an idea that can be incorporated into basically any framework with the danger of having recently a weak link. To ensure adaptation to fault tolerance, you need to plan a framework to such an extent that If one segment were to quit working, it would not prompt closure of the whole framework.
Adaptation to fault tolerance is based on the idea of burden adjusting and failover, which take out the dangers of abrupt disappointment. This action is normally introduced into the working framework which permits developers to screen the presence of an exchange.
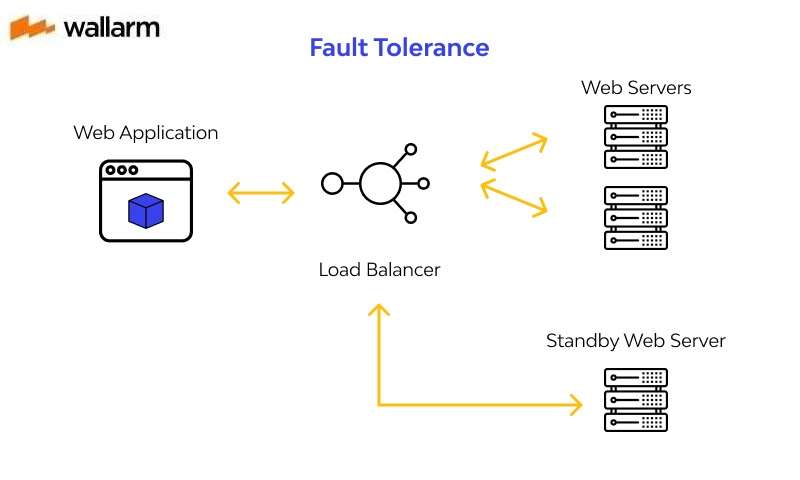
Adaptation to non-critical failure is a cycle that is based on two primary working models:
- Ordinary Functioning: This is a situation when a deficient open-minded framework fosters a shortcoming however the reinforcements kick in, and it keeps on working as regular with no hitches or glitches. This would imply that there would be no progressions in the exhibition of the framework or reaction time for significant cycles.
- Graceful Degradation: It's likewise feasible for a shortcoming lenient framework to go through smooth debasement when the framework separates. This implies that the effect of the breakdown on the framework is reliant upon the seriousness of the flaw. In basic terms, a little shortcoming would just little affect the exhibition of the framework instead of causing an accident of the whole organization or prompting genuine execution issues.
Software Fault-tolerance Techniques
These procedures make sure that software doesn’t crash just like if a fault occurs. There are multiple approaches used in this technique. Each one acts differently and comes with specific pros and cons.
- N-version programming
A very common approach that promotes fault-tolerant behavior, N-version programming involves developing multiple or say N number of software variants by ‘N’ number of developers. It’s basically creating multiple copies of software and using all of them concurrently.
By doing so, this approach aims to do fault detection at the early development stage so that things don’t become complicated later. While this approach ensures that there is always a back available always, it demands tons of effort and resources. At times, it can be too time and cost-consuming as well as it’s not easy to create multiple (‘N’) versions of software.
- Recovery Blocks
It’s very much similar to the N-programming approach as it also involves creating an N-number of the software version. But, unlike N- version programming, it doesn’t use some kind of algorithm for copies. Rather, each version is developed using a different algorithm. Also, not all the copies are used simultaneously. Instead, they are used in a sequence. This approach is useful when task deadlines matter more than anything.
- Check-pointing & Rollback Recovery
Less famous than the above 2 approaches, this strategy involves system testing for every computation. It works best in case of data corruption and processor cataclysm.
Hardware Fault-tolerance Techniques
First, understand that it’s not as complex as its counterpart. Its focus remains on ensuring upright operations of concerned hardware even if minor faults exist somewhere. The two most commonly adopted approaches for this technique entail:
- Build-in Self Test or BIST
It refers to the automated self-check at regular intervals by the hardware. Hardware is designed to do a quick check and replace the problem-causing component immediately. The time interval for this self-check can be pre-determined and can be anything. It involves human interaction at the very least level and promotes early fault detection and remedy.
- Triple Modular Redundancy
TMR involved the automated generation of 3 copies of crucial hardware as a backup. They all co-exist and remain functional at the same time so that if one copy of a component fails, the second one replaces it immediately. While this technique works, its handling is tedious for sure. It’s not easy to create and handle three concurrent copies.
Fault Tolerance vs High Availability
High availability is an idea that alludes to a framework's capacity to stay away from any deficiency of administration by stimulating vacation. This idea is communicated as far as the framework's uptime. Five nines or 99.999% is the greatest incentive for high availability.
Much of the time, businesses fuse High availability and adaptation to fault tolerance methods into their frameworks to ensure that the association can keep working even in case of minor disappointment or a little debacle. The two ideas allude to a framework's usefulness throughout a time frame yet there are key contrasts that separate the two of them and disclose their significance to the business being referred to.
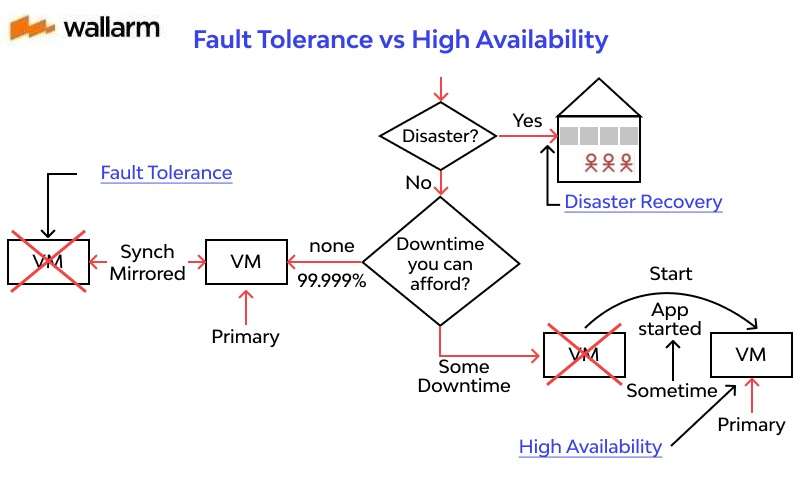
Significant contemplations to remember while making a shortcoming open-minded and high availability frameworks in an association are:
- Downtime: An exceptionally accessible framework is planned with an insignificant measure of vacation. For example, a framework that is appraised to be "five nines" accessibility will encounter vacations of around 5 minutes consistently. A flaw lenient framework should continue to work with no interference.
- Scope: High availability frameworks are based on a bunch of assets that are intended to manage disappointments and diminish the measure of vacation on the framework. Adaptation to non-critical failure is subject to control supply reinforcements including equipment and programming that can distinguish blames and change working abilities to repetitive parts of the framework.
- Cost: A deficient open-minded framework costs a great deal of cash to keep up because it requires all segments to be in ceaseless activity. Upkeep of the gadgets is done in a hurry and extra or excess parts are accessible. High availability is intended to be a piece of a general bundle offered by a specialist co-op.
Fault Tolerance and Load Balancing
When managing web applications, adaptation to fault tolerance is worried about the utilization of burden adjusting answers to guarantee nonstop activity and quick debacle recuperation. Burden adjusting and failover are basic to Fault resistance.
Burden adjusting permits help to run on numerous organizations, so you don't need to stress over the disappointment of a specific one. Most burden adjusting instruments additionally guarantee that responsibility is appropriately disseminated among the various processing assets, to guarantee that every one of them is more impervious to blame or breakdown.
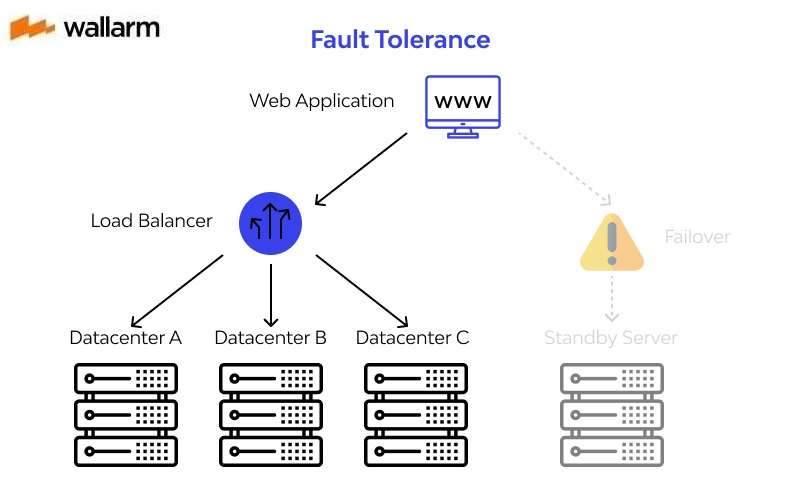
Likewise, load adjusting is a good thought to adapt to fractional organization disappointments. For example, a framework that is planned with two creation workers can receive a heap balancer to deal with the responsibility if anything happens to any of the workers.
Failover frameworks work unexpectedly. They are rather utilized during outrageous situations that have prompted a total framework disappointment. At the point when this disappointment happens, the failover framework is accused of auto-actuating another stage to keep the framework inactivity while endeavors are set up to re-establish the essential framework.
FAQ
References
Subscribe for the latest news





.jpg)