What is Distributed Tracing? Full guide
Although the most modern innovations help organisations succeed through increased efficiency, there is always a cost. Even if the field of current software development is expanding quickly, such complex structures make it extremely difficult to analyse and resolve performance problems.
The costs can be high when these problems affect customer experience. So, are you wondering what the remedy is?
If you're a business leader, software leader, DevOps engineer, or CEO, understanding its roles and when you can use it will give you the desired competitive advantage.
Observability is a premium solution that offers a perceptible synopsis of the bigger picture; therefore, observability is achievable through logs, traces, and metrics with distributed tracing as the primary tool.

What is Distributed Tracing?
When troubleshooting applications built using a distributed software architecture, traditional tracing has problems.
Due to the fact that microservices can scale (grow or shrink) independently, it is common to have numerous instances of a single service running concurrently across numerous geographies, servers, and environments, creating a complex network through which a request must travel.
Simply said, such requests are impossible to track using conventional methods developed for a single service application. As a result, it helps to simplify the project and enables you to address bottlenecks and mistakes in distributed systems before they affect the customer.
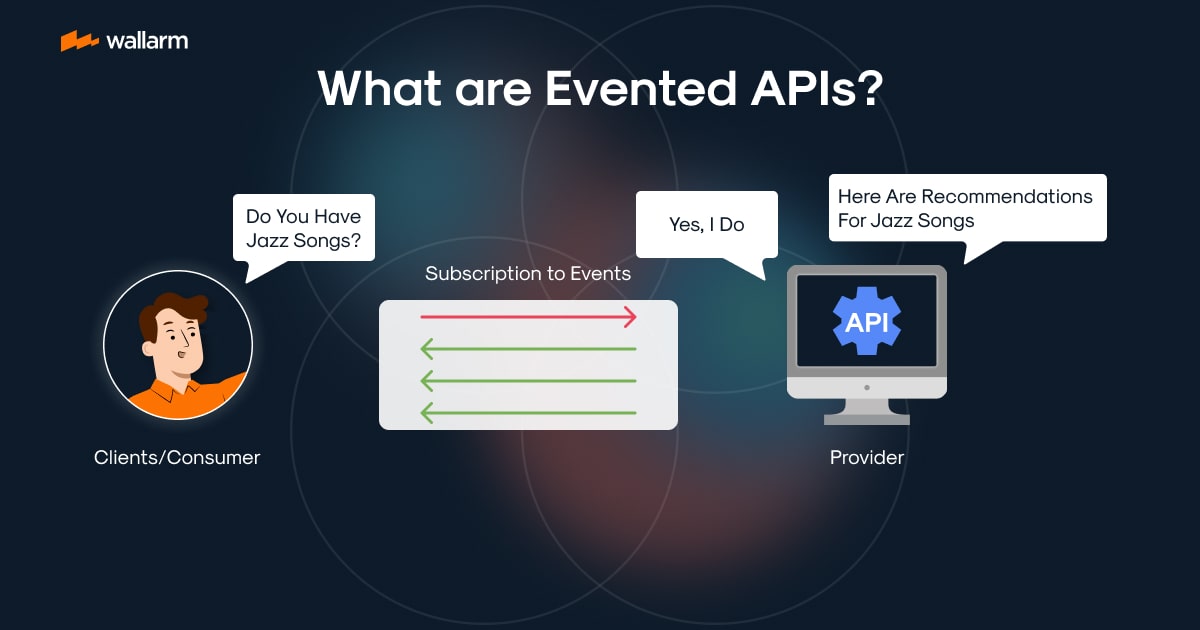
That’s where one of the greatest methods for analysing apps comes into play. It is distributed request tracing. Also called as distributed tracing in microservices, the technique is used by programmers in software engineering, together with various kinds of logging, to compile information about the activity of an app fundamentally.
In a nutshell, distributed tracing is an essential procedure for analysing and following requests as they move back and forth between distributed systems. It enables you to:
- Evaluate the general health of your system
- Gain a better understanding of a service's performance
- Quickly identify and remedy performance flaws.
- Establish priority for the areas that can be improved in real life.
Quick History
Distributed tracing became a better approach to obtain the necessary visibility into what was happening as firms realised that they needed a way while converting to distributed systems to gain visibility into individual microservices in isolation and the entire request flow.
Software development teams discovered that instrumenting systems for tracing, accumulating, and displaying the data required a lot of work and was challenging to complete. Writing the code required to make a distributed tracing function took time and resources that could have been used to create additional features. After that, two things might happen.
#1 - A top-notch solution, like new relic, will let businesses instrument apps for gathering, tracing, analysing, and visualising data with the least amount of work.
#2 - It is possible to integrate various instrumentation and observability solutions by establishing open standards for data sharing and instrumenting apps.
Important terms to Note
- A trace is a record of the performance data for requests as they pass through microservices.
- Spans describe the processes or segments that make up a trace.
- A succeeding span that can be nested is referred to as a child span.
- Requests are used by applications, microservices, and functions for communication.
- A root span is the very first span in a trace.
Importance and Usage
Some of the elements that ease the move from code to production while also adding new difficulties include DevOps containers, serverless operations, and distributed tracing. Because there are more possible sources of failure as software complexity rises, the mean time to repair for an application stack will also rise.
Simply put, when complexity rises, you will have less time for innovation since you will have to spend more time and effort analysing problems. The average amount of time it takes to resolve a problem after it has been reported is known as the MTTR.
A software team can work significantly more effectively when distributed tracing is included in their end-to-end observability plan. Hence, during the process, a team can:
- Assess the system's health more appropriately to bring positive changes to the CX.
- Issues must be better identified and fixed to enhance customer experience and commercial results.
- Innovate to beat out rivals.
However, if you're looking for more reasons for the importance of distributed tracing, here are some other reasons shown below:
- Flexible implementation
Due to their compatibility with a wide range of applications and programming languages, developers may realistically incorporate distributed tracing tools into any microservices system and access data through a single tracing application.
- Enhanced productivity
In comparison to monolithic applications, performance-monitoring functions, for example, finding and addressing faults, take longer time and cost more when performed using microservice architectures because of their fragmented structure.
Furthermore, the way failure data is delivered in microservices isn't always apparent, necessitating the need for developers to decode complex error messages and status codes in order to identify problems.
It shows a more comprehensive standpoint of distributed systems, cutting down on the time developers must devote to identifying and resolving request problems. Additionally, finding and eliminating error causes is much more effective.
- Superior cross-team collaboration
In a microservice setting, each process is created by a professional team for the technology used in that service, which makes it challenging to specify where a mistake ensued and who was in charge of fixing it.
Tracing speeds up reaction times and enhances team collaboration by assisting in eliminating these data silos, the productivity bottlenecks, and other performance hardships they induce.
How does Distributed Tracing Work?
Tracing's response to a single request must be closely examined in order to comprehend how rapidly it operates. Tracing begins in response to an application interaction. An exclusive trace ID is given to the user's initial request when a request, such as an HTTP request, is sent.
Each time an operation is performed on a request (also known as a "span" or "child span"), the trace ID of the original request, as well as its own unique ID and the ID of the operation that produced the current request, are all recorded (referred to as the "parent span").
Each span, which represents a single span in the request chain, is encrypted to protect sensitive data about the microservice process carrying out each action. They include the following:
- Tags to search and filter requests according to different identifiers, like the database host, HTTP method, and session ID.
- The procedure deals with the service or the name and address of the request.
- Logs and events that give context for the process' behaviour.
- Detailed error messages and stack traces in the event of a failure.
The first step in building distributed tracing is instrumenting your domain to enable data collection and correlation throughout the entire distributed system. Once the data has been acquired, correlated, and assessed, it can be visualised to show service dependencies, performance, and any unexpected events like failures or unusual delays.
Here’s how the process goes, overall:
Trace Context
For all of your apps and systems' various components to recognise the trace, distributed tracing needs trace context. As a request moves across an application environment, this entails giving each request its own ID, giving each step in a trace its own ID, encoding the context, and sending the encoded context from one service to the next.
The tracing tool may track and analyse performance by connecting each trace step in the correct sequence with other important data.
W3C Trace Context is transcending organisational borders and becoming the norm. Any tracers and agents that follow the standard are able to take advantage of the fact that it enables trace data to be properly propagated from the root service to the terminal one. The W3C Trace Context standard is supported by New Relic for distributed tracing.
Analysing and displaying
Collecting trace data wouldn't be useful if the software team doesn't know how to analyse and interpret the data across complicated systems. Your teams may view all of their business and telemetry data from a single location with the help of a complete observability platform. Additionally, it gives them the background information they require to analyse the data quickly, select the best course of action, and benefit your business from the knowledge.
Instrumentation
By integrating code into the services, you can review and track trace data in your microservices system. Instrumenting your applications for virtually any programming language and framework is easy thanks to services like New Relic.
You can also utilize open-source tools and open instrumentation standards to instrument your environment.
OpenTelemetry, a part of the CNCF, is quickly becoming the only accepted method for open-source instrumentation and telemetry collection. There is a thriving open-source community for initiatives like Zipkin and OpenCensus. Istio is one of the service meshes that emits trace telemetry data.
In order to promote open standards to ingest trace data from any source, regardless of the availability of free instrumentation or paid agents, New Relic is steadfastly dedicated to doing so. Additionally, Datalog offers comprehensive APM and tracing for businesses of any size. Therefore, you shouldn't bother comparing APM vs distributed tracing.
Metrics and metadata
Typically, a single trace records information about:
- Errors
- Spans (operation name, service name, duration, and other metadata).
- Critical operations inside each service's duration (such as internal method calls and functions)
- Custom characteristics

Advantages and Challenges of distributed tracing
61% of firms use microservice architecture, according to a 2020 O'Reilly poll. As that number rises, so does the need for improved observability as well as distributed tracing. Its benefits for frontend, backend, and site-reliability engineers are:
- Specific user actions are measured
This method allows for the measurement of the length of significant user actions, such as purchasing something. Traces can help identify bottlenecks and errors in the backend that are lowering the quality of the user experience.
- Maintain service level agreements (SLAs)
Most businesses have SLAs, which are agreements with clients or other internal teams to meet performance criteria. Distributed tracing solutions integrate performance data from specific services, allowing teams to quickly determine whether SLAs are being met.
- Cut back on MTTD and MTTR
The support staff can examine distributed traces to establish whether a backend problem is the cause of a slow or broken feature in an application that customers are reporting.
Engineers can then examine the traces produced by the afflicted service to identify the issue swiftly. You would be able to look into frontend performance concerns from the same platform if you used an end-to-end tool.
- Increased cooperation and output
Separate teams in microservice architectures may own the services necessary to fulfill a request. Where an error occurred and which team is in charge of correcting it are both made evident via distributed tracing.
- Recognize the linkages in services
Developers can comprehend the cause-and-effect links between services, improving their performance by studying distributed traces. For instance, looking at a span produced by a database request might show that an upstream service has latency when a new database record is added.
Besides the advantages as mentioned earlier, some challenges are shown below:
- Only backend protection
A request's first backend service is when a trace ID is produced for it unless you're using an end-to-end distributed tracing platform. On the front end, you won't be able to see the related user session. This makes it more difficult to identify the underlying reason for a bad request and decide whether the front or backend teams should fix the problem.
- Manual Instrumentation
Some solutions require manually configuration or altering of your code to begin tracing requests. However, its necessity is frequently dictated by the language or framework that need instrumentation.
The downside is - Manual process is time-consuming for engineers to perform and can result in defects in your application. Missing traces may also occur from standardizing which areas of your code to instrument.
Distributed Tracing vs. Logging
Experts can try monitoring and addressing performance issues using both methods, i.e. distributed tracing and logging. Every time-stamped log in your system summarizes a particular occurrence, and logs can come from the application, infrastructure, or network layers.
For instance, if a container runs out of memory, it might generate a log. The visibility into a request as it moves across service borders is provided by a distributed trace, which, in contrast, only happens at the application layer.
You may see the complete request flow with a trace and pinpoint the precise location of any bottlenecks or errors. Examining the request's logs may be necessary to delve even further into the root cause of the slowness or issue.
What Is Sampling?
Sampling is a factor based on the enormous amount of trace data that accumulates gradually. The difficulty and expense of storing and delivering such data rises as more microservices are deployed and the number of requests rises. Organizations can save data samples for study rather than the entire data set.
The sampling can be done in two ways:
- Head-Based
Head-based sampling is frequently used by distributed tracing solutions to handle enormous amounts of data. This involves selecting a trace at random to sample before it completes its travel. So the instant a single trace is started, sampling begins. This sample approach is advised owing to how straightforward it is because the data will either be saved or discarded.
- Tail-Based
In high-volume distributed systems, addressing every error is crucial. So, head-based sampling does fit for it (considering its shortcomings). Here, tail-based sampling makes a better choice.
In this ethod, sampling happens after each trace has completed its entire course and has undergone comprehensive evaluation. By enabling you to identify precisely where issues are present, this solves the whole "needle in a haystack" problem.
Distributed Tracing and Observability
Because of the surge in the use of microservices and cloud-based systems, observability is more important than ever. A variety of methods are used to record the system data.
This overall strategy, which depicts a succession of diverse events taking place within a distributed system, must include tracing. Traces, which are a representation of logs, make the journey and structure of a request evident.
Tracing is the process of recording an individual user's progress across an app stack, such as an elk stack, while continuously monitoring the flow of an application. Therefore, in this distributed tracing vs elk stack comparison, observability has evolved into distributed request tracing, ensuring cloud applications' health.
On the other hand, it is the practice of tracking a request by logging the information related to the microservices architecture's journey. This method offers a well-structured data tracing format used in various sectors and aids DevOps teams in swiftly comprehending the technological hiccups that affect a system infrastructure.
Types of tracing tools
Program Trace (ptrace)
A program trace is a list of the commands carried out and the data referred to while an application operates. When debugging an application, the information displayed in a program trace is used. This information includes the program's name, the language it was written in, and the executed source statement.
Code Tracing
Instead of using a debugger, which automates the procedure, to track a program's execution, a programmer would analyze the outcomes of each line of code in an application and manually record its impact.
Because the programmer need not run the full program to see the consequences of modest changes, manually tracing small chunks of code can be more effective.
Data Tracing
Critical data elements (CDEs) can be verified for accuracy and data quality using data tracing, which also helps track down and manage CDEs using statistical techniques.
Although historically, this hasn't been cost-effective in major operational processes, tracing actions back to their source and validating them with source data is usually the best way to undertake accuracy checks. Instead, CDEs can be tracked, monitored, and controlled using statistical process control (SPC).
Process that Distributed Tracing Tools follow
- Step - Data gathering
Such a powerful tool will start to gather span data for each request after your code has been instrumented.
- Step - Instrumentation
In order to track requests as they move through your stack, you must first adjust your code. Modern tracing solutions frequently offer automatic instrumentation, which eliminates the need for you to manually modify your code and supports instrumentation in a variety of languages and frameworks.
- Step - Analyzing and displaying
The spans are combined into a single distributed trace and tagged with analytically useful terms for the business. Traces may be represented visually as flame graphs or other forms of diagrams, depending on the distributed tracing tool you're using.
Conclusion
Distributed tracing narrates the events that took place in your systems, assisting you in responding rapidly to unforeseen issues. Hence, the use of this formula, as well as strategies like monitoring metrics and logging, will become more crucial as technology and software become more complicated in the future.
As you’re wondering about the impact of tracing via the distributed system, you will be amazed to know that it can help find out unpredictable behavior, making it hassle-free to impede and retrieve from failures.
If you're interested in finding out more about getting started and you are aware of how useful distributed tracing can be in assisting you in locating problems in intricate systems, now is the right time to take action.
FAQ
References
Subscribe for the latest news