Auto-Scaling
A company or organization that aspires to expand rapidly should ensure that its digital properties (websites, apps, etc.) can accommodate massive spikes in user activity.
The processing power required by an application is provided by the server or servers (together known as a "server farm") on which the application is installed. However, the workload processed by a single server is finite. What happens when the power requirements of the app surpass the available resources? There comes auto-scaling to save you the time and effort of manually adjusting the size of a server or system so that it can handle both high and low server loads.

What is Auto-Scaling?
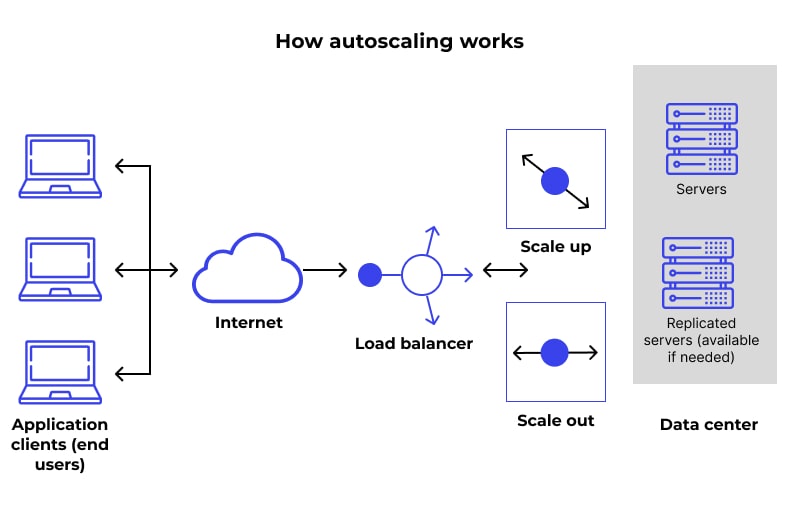
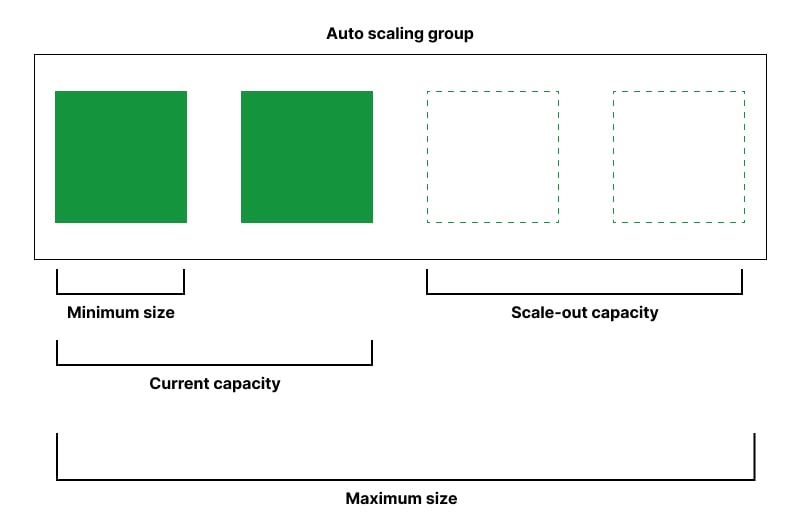
A feature of cloud platforms, auto-scaling is the ability to dynamically increase or decrease the number of deployed server instances in response to changes in the live traffic load on an application or workload.
When a traffic spike or drop is detected, the cloud can automatically adjust by adding or removing processing capacity to the instance cluster.
Therefore, the risk of existing servers collapsing under the weight of the traffic is reduced when new instances are added on the fly.
The cloud auto-scaler is programmed to release instances by shutting them down when traffic dies down and the job requires relatively fewer computer resources.
Why Is Auto-Scaling Important?
Auto-scaling's goal of lowering energy consumption makes it incredibly important. When the server load is low, it puts the servers in sleep mode to save power.
This service is especially helpful for applications with fluctuating loads, as it improves both server utilization and availability. This service can automatically pair and unpair nodes from a computational matrix to fine-tune the load, subject to the constraints specified by the system administrator.
Cost savings can be realized in the long run due to the fact that various cloud service providers have different pricing structures based on how much server time is actually consumed.
Auto-Scaling in Cloud Computing
It is a tool that allows enterprises to expand cloud services instantly on their own based on traffic. AWS, Azure, and GCP offer auto-scaling technologies.
Its features provide lower-cost, consistent performance by repeatedly adding and removing instances as demand climbs and declines. It ensures application consistency despite dynamic and unpredictable demand.
It minimizes the need to manually respond in real-time to traffic spikes by automatically adjusting the number of servers, and involves configuring, monitoring, and decommissioning each server.
It can be difficult to spot a DDoS-driven surge. Better auto-scaling metrics and controls can help a system respond rapidly. Its databases dynamically scale capacity up or down, start, or shut down based on application needs.
More about Cloud Computing
How Does Auto-Scaling Work?
Before delving into auto-scaling, it's important to note that there are two distinctive strategies:
- Horizontal Auto-Scaling
The number of nodes (or Kubernetes pods) handling a specific workload can be increased or decreased via horizontal scaling. Since no existing nodes need to be taken offline or modified, horizontal scaling is an attractive option for adding new capacity. This strategy of expanding resources is quicker than its vertical counterpart. Still, not all applications or workloads can be scaled horizontally.
- Vertical Auto-Scaling
When implemented, this type of scaling can either increase or decrease the amount of memory and/or processing power accessible to current nodes. If you have two server nodes, each with 16 GB of RAM and 4 virtual CPUs, you can increase their capacities by scaling vertically. Vertical scaling has the advantage of being the only possible approach to scale in response to increased demand in some circumstances, such as with relational databases that have been established without any workloads.
However, in contrast to horizontal expansion, vertical expansion does not lend itself as well to automation.
Types Of Auto-Scaling
There are primarily three kinds of auto-scaling, distinguished by the manner in which servers are called from the circuit.
- Predictive Auto-Scaling
Applicable in scenarios when server loads are rather constant. Additional servers are automatically activated at high-traffic times using a predictive or proactive autoscaling plan. This particular form of autoscaling makes use of artificial intelligence (AI) to "predict" when traffic will be heavy and "plan" additional server resources accordingly in advance.
- Scheduled Auto-Scaling
The sole difference between scheduled autoscaling and predictive autoscaling is that scheduled autoscaling involves scheduling more servers during times of peak demand. Scheduled auto-scaling, in contrast to autonomous predictive auto-scaling, requires greater intervention from humans in terms of planning for when servers will be needed.
- Reactive Auto-Scaling
When certain criteria are reached, as determined by the administrator, more servers are brought online automatically. This method is known as reactive autoscaling. Important metrics for a server's performance, such as its utilization rate, might have thresholds defined for them. Reactive autoscaling occurs, for instance, when supplementary servers are programmed to activate when the primary server has been operating at 80% capacity for one full minute.
To put it simply, this kind of autoscaling "responds" to the volume of traffic that is being directed into the system.
Benefits Of Auto-Scaling
When compared to deployment with a statically set instance type, which does not scale automatically, adopting an autoscaling technology or service offers many advantages. These advantages include the following:
- Less Expensive
In the absence of auto-scaling, businesses and cloud users are required to make continuous provisions for additional resources in order to be able to manage fluctuations in traffic patterns and potential spikes in traffic volume. Through the use of it, resources can be scaled up just when they are required and scaled back down when traffic levels drop. It is one manner in which companies might cut the costs associated with cloud computing.
- Automation
When additional resources are required, organizations have the option of manually adding them; however, this technique is neither scalable nor efficient. It is a strategy that is more optimal than manual scaling since it is automated and driven by policies. This is because autoscaling activates only when it is required to do so.
- Consistent quality results
Cloud administrators are able to specify desired performance levels, as well as ensure that such levels are achieved and maintained, through the use of its policies.
- Enhanced error tolerance
There are a variety of factors that might contribute to a disruption in service, including application logic issues, malfunctioning hardware, and logic flaws inside the service itself. When it is enabled, the health and performance of a workload are continuously checked so that resources can be replaced and scaled automatically according to demand.
- Accessible services
It is possible for cloud services to become inaccessible, if they are bombarded with workloads that are resource-intensive or if there is more traffic than the instances they have been designed to manage. In the event that there is a surge in customer demand, it can make sure that services are still available.
When Is Auto-Scaling Used?
The applications of auto-scaling that are most frequently encountered are illustrated by the following examples:
- E-Commerce
As a result of the fact that the vast majority of people who shop online do so during business hours, software developers are able to program frontend and ordering systems to automatically scale out during the day and scale back in during the evening. In a similar vein, its API security assists teams in getting ready for holidays and other times of the year that are typically connected with an anticipated increase in demand.
- Broadcasting
When new content is released by companies in the media industry, the level of demand can often skyrocket to levels that are much higher than the most optimistic predictions. It is helpful for this kind of content that "goes viral" since it provides vital resources and bandwidth when it's needed.
- Startups
In the past, one of the most difficult challenges for smaller businesses that aimed to draw in a big number of clients was to cut costs while also planning for rapid expansion. Kubernetes auto-scaling has contributed to the solution of this issue by enabling startups to keep their costs low while also lowering the danger that an increase in demand would cause their application servers to fail.
Auto-Scaling Vs Load Balancing
LB is tied to application auto-scaling. Both AS and LB minimize backend activities, including monitoring server health, controlling traffic demand, as well as adding or removing servers. LBs with autoscaling functionalities are widespread.
They increase application obtainability, presentation, and latency. You can set auto-scaling policies based on application requirements to scale in and scale-out instances, instructing the LB on how to distribute traffic between running examples.
An elastic load balancer verifies each representative’s health, distributes traffic, and links requests to target groups. Elastic LB stops traffic to redirect data requests. It prevents requests from flooding one instance.
Auto-scaling using elastic LB attaches a load balancer and autoscaling group to route all requests equally. This frees the user from monitoring the number of endpoints instances create—another difference between autoscaling and load balancing.
Problems Related to Auto-Scaling
Here are some auto-scaling difficulties engineers may face:
- Configuring auto-scaling can be difficult.
To auto-scale successfully, an application's frontend, backend, database layer, and infrastructure pieces like load balancers must auto-scale.
- Application must be developed for horizontal scaling.
Engineers must construct the application as microservices, not a monolith, to facilitate horizontal clambering. The app should also ensure statelessness; a user request shouldn't depend on a node "remembering" it. NoSQL and read-only databases scale horizontally better than relational databases.
- Demand peaks can overwhelm auto-scaling.
Even in the best case, nodes may take minutes to come online while users experience slowness.
- Identifying and responding to the right metrics isn't exact.
It requires engineers to find the right performance criteria. Not everyone can correctly identify these metrics. Engineers may auto-scale based on erroneous performance criteria, leading to a poor user experience.
Vendors Offering Auto-Scaling
Various cloud service providers use natively built methods or software to auto-scale servers. Let's examine some examples.
- Google Compute Engine
GCE auto-scales using Managed Instance Groups (MIGs). Users can define MIGs, group them by performance measure (such as CPU utilization), tweak them for the appropriate autoscaling cap, and enable autoscaling with a click.
Amazon Web Services (AWS) has two autoscaling services: AWS and EC2. Launch templates help Amazon EC2 launch instances (like VPC subnet). EC2 users can set instance count manually or automatically.
Microsoft Azure auto-scale automatically scales resources for Azure cloud users. Azure auto-scale supports VM, mobile, and website deployments.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")