Race Condition
Every software, system, or electronic device is based on a certain program, sequence, and algorithm. Anything that falls outside the periphery of this sequence or algorithm will cause an error or improper functioning. If you use multi-threaded applications, then race conditions could give you a serious headache. Learn more about this situation as the post proceeds.


An overview of Race Condition
A most common operational issue with multi-threaded applications, a racing attack is an unwanted situation referring to the incidences when a multithread tool tries to accomplish more than one task at a time. But, the predefined sequencing of that specific program/device will not let it happen as the device/software must follow the default sequence.
The ideal occurrence scenario for a race-condition attack is when two or more programs/software/threads try to access a specific asset/resource simultaneously.
The Examples
If you’re using a multi-threaded app, you must have dealt with the racing loophole a couple of times. It’s so common that it exists outside the software or technology domain. However, not everyone manages to detect its presence.
Thinking of what could be an example of race condition? See 2 of them below:
- A Daily-Life Example
Have you seen multiple light switches connected with one main light? It’s a very common situation. However, these multiple-connection circuits are not concerned with the switch position. When the light is on, one can easily turn the light off using any switch.
Now, consider a scenario when two people are trying to turn on the light simultaneously. They will use different switches. When this happens, it’s obvious that the action of one switch will cancel out the action of the other switch. This will make the light connection fail. This is a racing situation.
- A Digital World Example
If a programmer is trying to command the device to read & write a big data set and any other machine tries to re-write or overwrite the whole or a part of the database, a race-condition is likely to occur.
This condition is likely to give birth to the below-mentioned situations.
- The device will crash
- Erroneous data dreading
- Faulty data writing
- An illegal program operation is identified
One ideal scenario for the rare condition is instructions processing in a faulty order.
4 Types of Race-Condition
A deeper understanding of race condition definition reveals that there are multiple race condition types. The key ones are explained here:
- Critical ones will influence the terminating stage of a program or device and force it to modify.
- Non-critical ones haVe no direct impact on the end stage or action of the concerning devices/resources.
Both the above racing varieties extend beyond programming and electronics. The programming domain experiences two other kinds of race conditions that are related to code. These two types are as mentioned below.
- Read-modify-write with code examples
Think of 2 separate tasks that intake the same value and return a new outcome. This type of variety is responsible for software bugs and causes hindrances in operations.
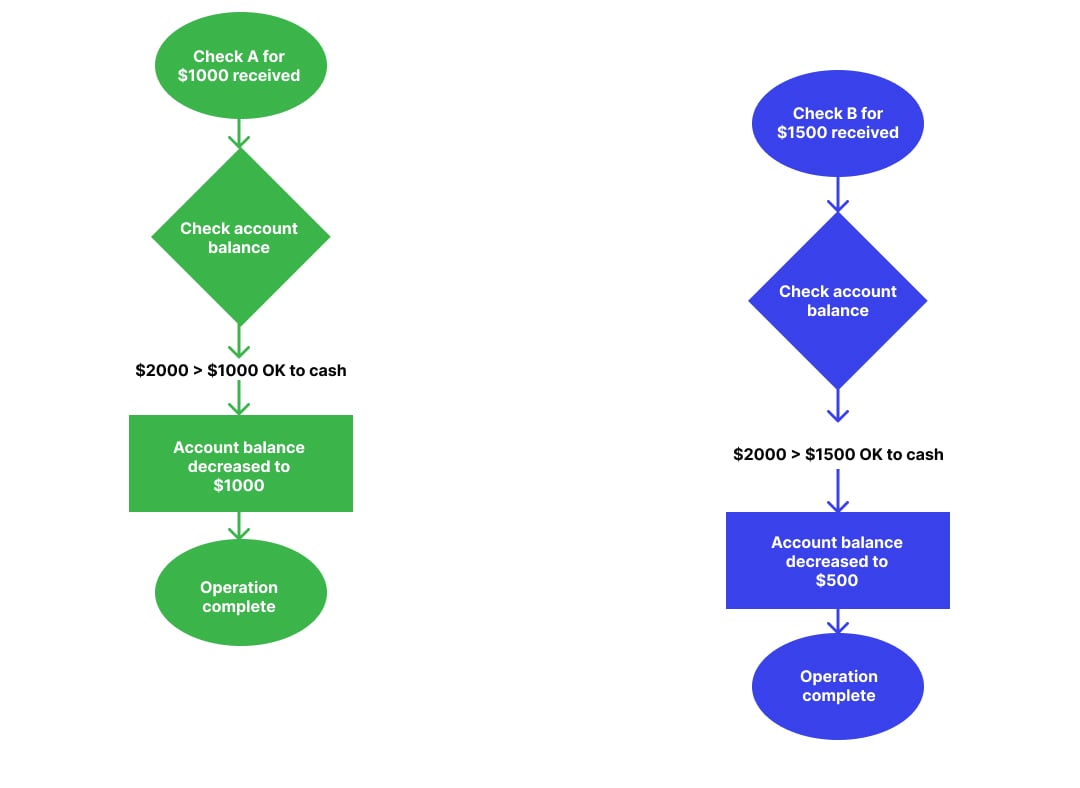
Example – Consider a scenario where a checking account is processing multiple checks in a set sequence. The bank’s check processing system will process checks only when enough funds are there. First, check A will be processed, and then funds are checked again before proceeding with check B.
But, when two checks proceed at a time, instead of processing checks one after another, a read-modify-write race condition will take place and force the system to read the same check amount value for both checks and show an incorrect account balance value.
- Check-then-act with code examples
This situation takes place when two workflows assess a value and will take distinct actions. Both processes will check the value, but only one will proceed with it. The process that will take afterward will accept the value as null, which will lead to an outdated outcome that the program will use to proceed further.
Example
Suppose a map application proceeds two processes at a time. Each process demands the same location data. When this type of racing exists, one of these two processes will capture the value early so that the other process can’t access it. As no value will be available to use for the second process, it will receive null data.
The Race-Condition Vulnerability
Racing vulnerability or cyber threat is often called Time-of-Check to Time-of-Use (TOCTTOU) too. It exploits the obvious requirement of the computing device to adhere to a sequence while processing actions. There is a certain gap between two sequences as computing systems carry out one task only when the previous one is successful. If that gap exceeds a lot, then hackers can use this gap to introduce any malicious content.
Typically, a race condition vulnerability takes place when a bad actor manipulates the system in a manner that it starts performing unacceptable actions under the hood of normal actions.
The two methods that lead to the execution of these actions are mentioned below.
- Causing interference with the help of an unverified Procedure – In this method, the threat actor injects malicious code into any of the secured processes. His purpose is to break this security and succeed at his intention.
- Causing interferences with the help of a trusted Procedure – This method involves misusing 2 procedures that share similarities.
Impact of a Race Condition Attack
The direct impact of racing vulnerability is on system/device performance. However, it has a high impact on the device’s security. Every software is designed to follow a certain process order. If that order isn’t followed, certain operational deformities are certainly to take place.
A skilled threat actor can use this deformity to exploit the device by taking advantage of the delays occurring due to racing. It will give birth to thread lock or deadlock conditions. Deadlock vulnerability creates the base for DoS attacks, while threat blocking hampers the performance of the targeted device.
Race Condition And Deadlock
Both share some similarities, such as they both occur in multi-thread solutions and hamper device performance. However, both are not the same.
A race condition occurs when two threads use the same variable at a given time. Deadlock exists when two threads seek one lock simultaneously.
This situation will stop both threads from processing or executing the functions. In racing, two tasks compete with each other and try to complete a task before each other.
In a deadlock, two processes are waiting and expecting the complementary process to complete the task.
How to Determine Race Conditions
Even though determining race-condition vulnerabilities is difficult, it’s not impossible. You can spot the odds of its situation’s occurrence with the help of static & dynamic tools. Static testing software will automatically scan a program even if the program is not in use. However, one might experience false positives with this method.
Hence, it’s better to take the help of dynamic testing tools. But, they are also not flawless. It’s nearly impossible for dynamic tools to learn about the racing incidents occurring indirectly.
As racing is often an output of data races, one can take the help of data race detectors to figure out about the data races and racing eventually.
How to Prevent Racing?
If you want your digital resource to operate flawlessly, you must curb the race-condition vulnerability and find some viable preventive techniques. Here are some of its most preferred prevention techniques.
- Keep shared states as less as possible
The more resources applications/devices will share, the higher will be the possibilities for a race-condition. Hence, the easiest way to deal with racing is to reduce sharing. Even if you’re sharing resources like codes, be extra conscious. Always review codes to make sure that if they are shared, the impact on atomic operations should not be negative. This will allow shared codes to run independently.
One more adoptable practice to avoid sharing under control is to use immutable objects. Such objects can’t be changed after being created once.
- Take the help of thread synchronization
Threat synchronization is a viable way to deal with race conditions; it involves the execution of threats at a time by a specific program.
- Serialization of memory/storage
Try serialization of storage or memory. This refers to the execution of the read command earlier if both reach & write commands are received at the same time.
- Priority scheme for networking
The race condition is a very common issue with the network. It occurs when two or more users are trying to access one network channel simultaneously, but the computer has no idea of this situation. Mostly, networks having high lag time are affected by this race-condition.
To deal with it, one is advised to use a priority scheme. Under this scheme, a specific user is granted exclusive access. This way, there is no way that two users are trying to access one network at the same time.
Conclusion
Race condition programming is a matter of concern as it impacts the system's performance. Organizations seeking seamless networks, devices, and multi-threaded applications must be aware of its common occurrence scenarios and apply early prevention techniques. This way, you can reduce the incidences of race-condition vulnerabilities.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")