What is a Load Balancer? Definition, Types, Networking
Modern-day web applications and websites are not sitting idle, even for a second. Depending upon the usage and market penetration, a web application can receive millions of requests in one second. In such a situation, it’s unwise to expect outstanding server performance all the time.
To avoid server failures or high response time, experts often recommend using a load-balancer. Responsible for equal traffic distribution, this tool is of great help for big-size business ventures and enterprises. Read this post to learn everything about it.

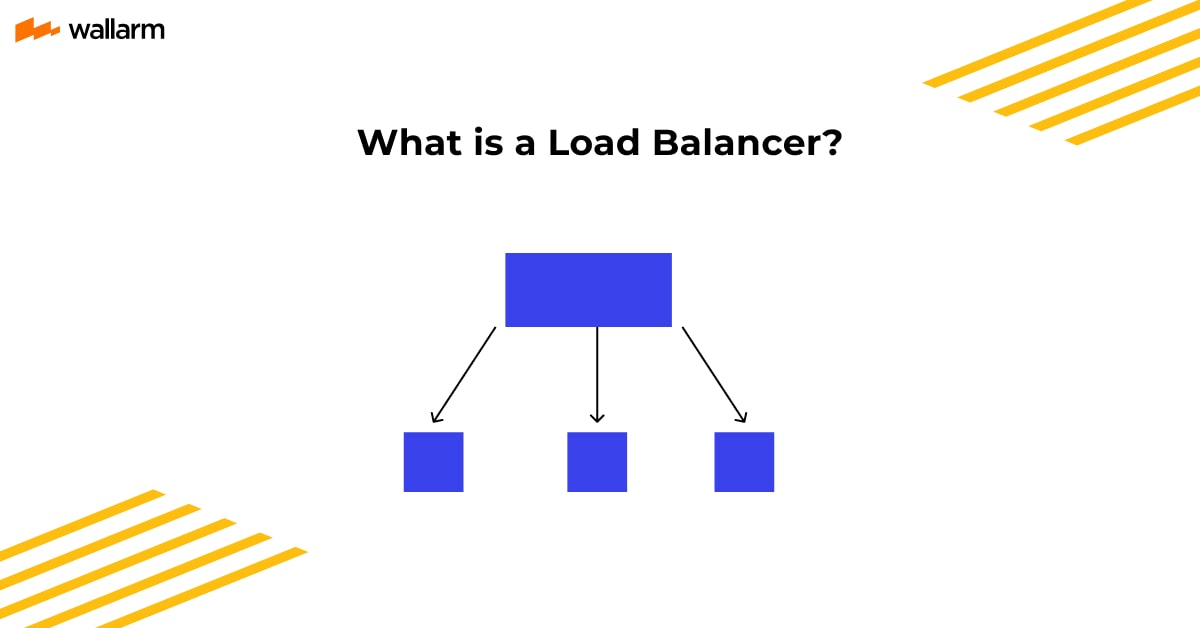
Load Balancer definition
Just as we have traffic cops to route the road traffic in real life, the digital world has load balancer server. It, when strategically deployed, helps in proper incoming traffic routing. Using the tool ensures that no one specific server is taking the traffic load while others sit idly.
It monitors the incoming traffic and diverts it to the least-occupied server. If there is no response, the next available server processes the request.
In an enterprise, many servers are often used to handle the incoming traffic. But, when traffic is not guided properly, it can go to whatever server comes first or is easily accessible. For instance, if the majority of the servers are backed by the power of a firewall, expecting one, traffic will automatically go to the firewall-free server as it’s easy to approach.
This way, one server will be taking traffic’s full load that leads to sluggish performance and late response. Introducing an application load balancer here resolves this issue.
It targets to limit the exhaustion of certain servers and boost the request-response rate. Location-wise, a load-balancer is placed at the entrance of the app’s backend servers, which means that it accepts client requests before the origin server.
It could be a software or hardware-based tool. With the first option, there are no installation and set-up hassles to tackle as software-based load-balancers are pre-configured and are accessible using a simple login process.
On the other hand, a hardware load-balancer demands dedicated set-up and installation, which isn't always preferred. Either way, the aim remains the same.
Attaining clarity on the reverse proxy vs load balancer concept is crucial. The reverse proxy also forwards the client machine’s requests towards the server, but not like an application load-balancer that passes requests to the pool of server systems.
API gateway vs load balancer also deserves your attention. API gateways are what APIs use for communicating with servers and carrying forward the response, which is not exactly the same as load-balancing.

How it Works?
It follows a simple workflow. The load-balancer uses multiple algorithms to find out if the server has availability. When a request is processed, the tool analyzes it and diverts it to the unoccupied server. The same mechanism is repeated for every incoming request.
Load Balancing Algorithms
- Static
It isn’t concerned about the server conditions and won’t consider them while routing the incoming traffic. A system following this algorithm won’t know which server is over-occupied and which one is sitting idly. Without this understanding, it often sends the traffic to wrong or misjudged traffic forwarding.
Even though its set-up is easy, its performance could be erroneous and faulty. It may even make an inactive server get requests. The 2 most-common examples are:
- RR (Round-Robin) sends out the request to a server-group in a pre-defined sequence.
- A client-side arbitrary or random load-balancer picks 2 any servers and shares the request’s details with the one that uses the least-connection algorithm.

- Dynamic
A far updated and better algorithm, it has access to server’s health-related report beforehand and uses it to make traffic routing related decisions. It will be aware of server’s health, traffic load it has currently, count of pending requests, average time taken at responding, and other critical aspects. Traffic routing happens accordingly.
The algorithm is further categorized into:
- Resource-based: It first figures out about the busyness of the server and then passes clients’ requests to it. Everytime, new requests will be sent to the least busy server.
- Geolocation-based (GSLB): It makes sure that servers in various geographies/places are receiving traffic equally. It avoids the overburdening of local servers and ensures distant or remote servers are so fully used.
Being a bit complicated algorithm, it demands great competency during configuration. However, it leads to accurate and well-optimized traffic routing.
The Scope: Where Is It Used?
Load balancing has a wide implementation scope. It’s used everywhere where effective internet traffic handling and full server utilization are required. Web applications, websites, and corporate applications are some of the most common use case scenarios of this tool.
With the help of cloud or software-based load-balancers, it’s easy to achieve equal traffic distribution.
Localized networks also use this method for seamlessly distributing the traffic. The complex infrastructure of localized networks makes request-optimization tough. But, its implementation in this scenario demands additional resources like ADC or load-balancing devices.
Hardware vs Software-based Load Balancers
There exist software & hardware-specific solutions for load-balancing. They both have distinctive modus operandi and features.
For instance, hardware load balance demands tedious set-up and configuration, while the other is a plug-and-play solution with nearly zero configurations.
Software-based load balancers are compact and support great configurations at every level. On the other hand, hardware-based ones are complex tools with endless capabilities. They can handle huge traffic at a time.
One gets to enjoy great virtualization abilities with hardware load-balancers, while the other option is useful for analogous abilities.
Admins have better control over operations and functions with hardware load balances. They can define the usage, scope of the admin’s role, and have multiple architectures. With the software version, customization is limited.
The set-up and maintenance of hardware-based options are very high. So, it’s only a viable option only for the big enterprise that can afford the high overheads.
Software load-balancers are way affordable. One is allowed to pay as per the requirements. As end-users are not involved in set-up and installation, its usage is not very pocket-heavy.
Benefits of Load Balancing
Organizations maintaining huge traffic on a daily basis must adopt this practice to ensure effective traffic routing. Starting from multiple query handling to resource optimizations, balancing brings a lot to the table. Its effective usage and implementation include a couple of notable benefits like:
- Great flexibility
Server flexibility is easy to achieve with it, as any server can be added or deleted in the existing server group. This flexibility is so effortlessly obtained as any addition or elimination will not impact any disturbance in the existing architecture. Traffic routing takes place even during the maintenance process.
- Seamless scalability
With the increase in traffic, server scalability must be achieved as it will ensure that enough servers are there to tackle boosted traffic. Load balancing makes it possible as it allows users to add any virtual/physical servers as per the need of the hour.
Any newly added server will be automatically recognized and accepted by the load-balancers. The great thing about this scalability is that it has nearly zero downtime, which is not experienced elsewhere.
- Robust redundancy
Load balancing shrinks the chances of operational failures and makes servers highly redundant. In case of any server failure, load balancers will forward the requests to the next working server so that clients don’t have to bear a high response time.
Dynamic Configuration of Server Groups
The performance upkeep of performance demands constant server switching. A few servers should be taken down while a few need to be added as per the need of the hour. AWS users experience this very frequently.
EC2, the cloud-computing tool of AWS, charges users on a consumption basis. Despite the consumption-based cost, EC2 won’t compromise on server scalability. Elastic load balancer, an AWS component, also follows this approach.
Scalabilities happen automatically as traffic shoots up. The implementation of a load balancer can make things better as it permits seamless server adding and elimination. Load balancer makes it happen dynamically, which means zero disturbances in the current activities or server performance.
Session Persistence or Sticky Sessions
While demanding a deeper understanding of load balancing, one will encounter sticky sessions or session persistence. A part of application load-balancing, it helps in attaining the server kinship.
Commonly, the user session data is stored on the browser locally until the user decides to reuse or process it further. For instance, an e-commerce platform user leaves a product in a cart and doesn’t process it further. The data remains locally saved. If there is any change in the server processing that pending request, it leads to severe failures like no transaction processes.
This situation can be easily avoided with session persistence as it ensures there is no change of the server in the middle of an ongoing session, even if the session is on hold.
Effective load-balancers can use session persistence as per the need of the hour. Other than helping an application achieve great server affinity, it also permits upstream servers to ensure great performance during cache information. It prevents upstream servers to swap servers during server fetching.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")