AI use in business operations introduces new exposure points and attack surfaces not addressed by conventional cybersecurity tools. These modern systems include learning algorithms, pipelines, and datasets that evolve and adapt to fresh data—opening pathways for unique disruptions.

Learning models can be destabilized through minor alterations in training sets or misleading input samples that lead them into unexpected behavior. These systems don’t operate on fixed rule sets—reprogramming isn’t enough; models often need retraining or replacement when their behavior is compromised.
AI directly affects operational decisions in healthcare, finance, security, and human resources. In financial systems relying on behavior prediction, such as fraud detection, adversary-crafted inputs can shift system outcomes. Undermined accuracy may clear fraudulent transactions or flag legitimate ones, impacting business trust and continuity.
Model development involves significant capital and labor. Training models from initial data gathering through iterations of refinement demands time and resources. If those models are stolen, an adversary may re-deploy them elsewhere, bypassing costly development and undercutting the original organization.
Intelligence systems often work opaquely, especially large-language or image recognition models that process millions of variables. Exploiters can introduce flaws without detection from the model’s visible output alone. A visually acceptable result might conceal underlying bias or error.
Increased scrutiny from legislative bodies forces organizations to consider liability. Misbehaving decision models affecting loan applications, employment, or parole decisions may provoke regulatory fines and legal action. Often, responsibility falls back on organizations using the technology despite sourcing it from third parties.
Machine learning systems can be turned against themselves. Hackers have previously created AI-generated phishing campaigns, synthetic identities, and real-time vulnerability scanning tools. Using neural networks, attackers automate reconnaissance and social manipulation faster than human teams could.
Examples of negligence or misuse underline the critical risks:
- Autonomous Driving Miscalculations
Driver-assistance systems in electric vehicles have misinterpreted road markers, failing to initiate braking or changing lanes unsafely. These examples show that even redundancy systems cannot fully mitigate knowledge gaps within a learning model. - Troll-Influenced Language Bots
A conversational agent trained in real-time on public social media adopted offensive speech within hours of operation. The bot’s real-world training data became a vector for behavioral corruption—a case of on-the-fly data contamination. - Unregulated Access to Text Generation APIs
Large-scale text generators have been coerced into outputting malicious code, fraud scripts, and misinformation. API-level overreach allowed nefarious prompts to bypass safeguards and generate dangerous content—highlighting insufficient access granularity.
Model integrity spans data, processing, and logic layers. Not only must infrastructure be protected, but models themselves—if deployed via APIs, cloud functions, or edge devices—must be audited. That includes controlling who can interact with them, inspect results, or observe their performance under stress.
When AI pipelines increase automation and real-time operations, the potential attack vectors widen. Common sources of compromise include:
- Training Set Interference
Individuals seeding incorrect information during model-building phases skew learning trajectories—impairing trust in every future inference made using that corrupted base. - Public-Facing Interfaces
APIs used in chatbot deployments or analytics dashboards invite reverse engineering if rate limits and access filters are insufficient. Attackers can test edge cases or provoke behavior anomalies. - Prediction Routings
AI determining security incidents, loan approvals, or medical outcome projections becomes vulnerable when adversaries introduce format-specific traps designed to degrade output quality. - Storage and Retrieval Weakness
Model files kept on shared drives or improperly secured cloud endpoints can be downloaded, tampered with, or fed into comparative tools to reconstruct architecture details for replica development. - Visualization Layers
Tampering with metrics display tools enables attackers to mask performance anomalies. Obscuring drops in precision or increasing latency may delay incident response.
Misunderstandings further expose businesses to preventable threats:
- “Machine learning belongs to IT so it’s covered under IT rules.”
IT departments apply policies centered around static infrastructure. Models and training data fall outside this paradigm, requiring bespoke treatment. - “We’re using a major cloud provider, so they’ll handle security.”
Cloud compliance covers physical hardware and shared security responsibilities. Model training, configuration, and endpoint exposure remain internal obligations. - “We don’t make automated decisions—our AI just sorts customer emails.”
Something as minor as routing service requests carries business significance. Unfiltered or spoofed inputs can affect internal workflows or degrade customer experience. - “AI figures out errors through feedback.”
Models often rely on passive data input but rarely detect malicious manipulation without specific input filters or human-assisted retraining cycles.
Consequences of neglect involve operational, financial, and reputational fallout:
- Revenue Degradation
Tampered ML logic may mislead forecasting weapons, driving poor inventory, pricing, or market decisions. - Brand Damage
AI suggesting gender-biased hires, or falsely classifying harmless user behavior as threatening, can provoke media backlash. - Non-Compliance Fines
When algorithms operate without proper logging or bias checks, agencies may investigate. EU, U.S., and Asia-Pacific laws increasingly enforce standards for automated processing. - Intellectual Theft
Cloning of proprietary AI with stolen weights and logic structures empowers competitors to offer mirrored services while skipping long-term R&D costs.
Security of learning systems is difficult due to:
- Continuous Updates
Models retrain periodically on variable data sources, creating a non-static environment resistant to traditional baselining. - Opaque Calculations
Deep networks bury meaning across countless internal nodes, minimizing interpretability. Identifying a poisoned result after the fact is difficult without exhaustive auditing. - Critical Data Dependence
Behavior stems from input quality. A biased or mislabelled set will propagate errors regardless of algorithmic rigor. - Emerging Attack Typologies
Threat types like gradient leakage or shadow model inference go beyond current mitigation strategies and often remain unnoticed until too late. - Inadequate Defensive Ecosystem
Many cybersecurity suites don’t extend visibility into probability distribution shifts, overfitting signs, or adversarial example exposure areas.
Enterprise-wide coordination is required for deploying and protecting intelligence systems:
- Decision-Makers
Set directives that demand auditability, safety testing, and asset prioritization during AI procurement and deployment. - Legal Stakeholders
Track global rulesets—especially related to AI transparency, bias liability, and consumer data handling. - Technical Engineers
Build secure ergodic logic structures that resist manipulation through input clipping, response filtering, and noise calibration methods. - Security Analysts
Integrate drift detection, scoring stability assessments, and AI-focused incident response playbooks into security operations. - Education Facilitators
Trainees and departments responsible for onboarding should develop separate curriculums around safe AI usage for data stewards and line managers.
Understanding Data Poisoning in Machine Learning
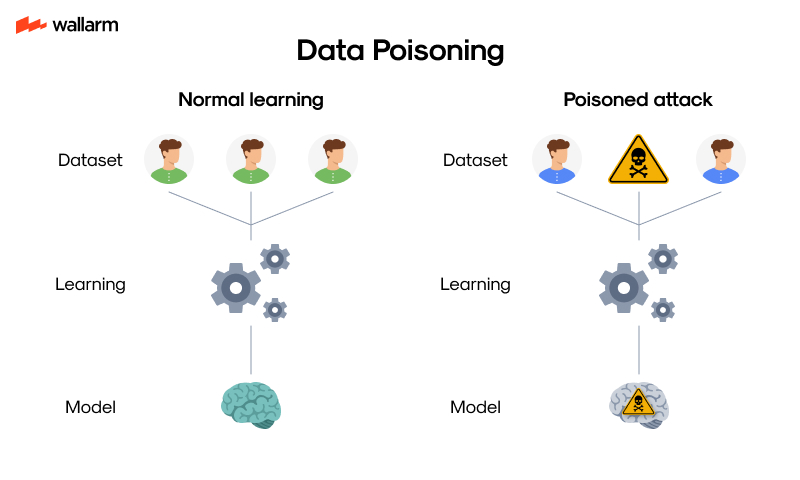
Data poisoning refers to a manipulative attack strategy where adversaries deliberately introduce corrupted samples into the training dataset. By embedding deceptive or disruptive inputs during model development, the attacker steers the behavior of the resulting model toward flawed, unsafe, or intentionally biased outcomes. These manipulations can compromise classification accuracy, reduce trustworthiness, and create vulnerabilities for future exploitation.
This approach diverges from traditional exploits aimed at code or infrastructure. Instead, it disrupts the core logic of AI development — the data-driven learning process. Poisoning the dataset undermines pattern recognition and predictive responses, creating persistent risks embedded within the model’s inference logic.
Two principal strategies emerge:
- Target-Specific Poisoning: The attacker embeds malicious patterns to induce a particular behavior in response to certain inputs. Example: making a face recognition system misidentify one particular individual as someone else.
- Model-Wide Poisoning: The attacker broadly contaminates training data to overall reduce accuracy, causing widespread misjudgments without focusing on specific targets.
Entry Points for Poisoned Inputs
Attackers insert harmful data by exploiting weaknesses in data sourcing mechanisms and training pipelines:
- Community-Contributed Content: Models trained on user-submitted content (e.g., social media posts or product reviews) are exposed to synthetic submissions from bots or coordinated campaigns.
- Open Data Repositories: Public datasets, especially those allowing open contributions, may include malicious records that serve as camouflage for tampered entries.
- Internal Threats: Team members or contractors with permissions to curate or modify datasets might deliberately plant irregular samples.
- Third-Party Integrations: Vendors or data providers who supply resources to the ML pipeline become potential vectors if they're compromised.
Consider a spam filter. If an attacker repeatedly labels spam messages as legitimate and injects them into training sets, the system might eventually “learn” to ignore authentic spam, degrading its filtering function.
Incidents Caused by Data Poisoning
Red Flags Indicating Data Manipulation
Detecting contaminated data is difficult, but subtle abnormalities can reveal the presence of poisoning:
- Degradation in Accuracy: A consistent increase in prediction errors, especially following dataset updates, may point to compromised training inputs.
- Case-Specific Misbehavior: The model performs optimally on most data but reacts inappropriately to particular entries — a hallmark of target-specific attacks.
- Increased Biases: Sudden skew in model results along demographic, linguistic or categorical lines may stem from poisoned classes.
- Outlier Memorization: Models that learn insignificant or rare patterns too rigidly might be overfitting to engineered poison triggers.
Countermeasures and Mitigation Strategies
Defensive tactics should focus on securing input channels, improving model robustness, and maintaining full oversight over data provenance:
Pre-Training Data Screening
Apply anomaly detection and statistical inspections to identify elements outside expected distributions before training.
Curating from Verified Origins
Limit training sets to vetted or contractual data providers. When community-generated samples are needed, apply consistency checks and label audits across sources.
Restrict Live Feedback Loops
Systems that update themselves dynamically using live user interaction or content (e.g., voice assistants or recommendation tools) must include sandboxing stages where flagged or unusual inputs are isolated for review before retraining commences.
Continuous Analysis of Outcomes
Automated regression monitoring should detect divergences in accuracy, misclassifications, drift in feature saliency, or abnormal response types.
Privacy-Aware Training Methods
Differential privacy algorithms, through deliberate noise injection, reduce the impact that any singular malicious entry can have on model formulation.
Robust Model Architectures
Training algorithms designed to ignore extreme input samples (e.g., using trimmed losses or median filtering) build selective resistance to tampered data trends.
Auditable Data Versioning
Implement logging for every dataset modification. Track contributors, timestamps, and change reasons using tools designed for data pipelines.
Simulated Infiltration Exercises
Test model resilience under staged poisoning environments. By mimicking adversarial data scenarios internally, teams can refine vetting, retraining, and rollback protocols.
Contrasts Between Valid and Subverted Data
Detection and Hardening Toolkits
- Snorkel: Leverages weak labeling frameworks to increase data supervision at scale
- Cleanlab: Evaluates and flags mislabeled entries based on model outputs
- TensorFlow Privacy: Enables private training modules that limit individual data influence
- DVC (Data Version Control): Tracks evolving datasets and restores safe states when needed
- Great Expectations: Defines validation checks pre-training and enforces schema rules
High-Risk Operational Lapses
- Trusting public datasets without comparison or validation
- Neglecting automated anomaly scans before ingestion
- Allowing unrestricted API-to-model feedback training loops
- Ignoring legacy data that no longer matches current distribution norms
- Underestimating threat actors embedded within the pipeline chain
Data Security Checklist for Machine Learning Pipelines
- Accept data only from vetted, trackable sources
- Perform anomaly checks and label audits before training sessions
- Integrate monitoring agents for model drift and anomaly behavior
- Implement multi-tier permissions for data editors and researchers
- Favor training strategies that neutralize malicious outliers
- Use tools for version control, traceability, and rollback capability
- Run adversarial simulation exercises quarterly
- Train engineers to recognize and respond to data-tampering risks
What Is Model Theft and Why It Matters
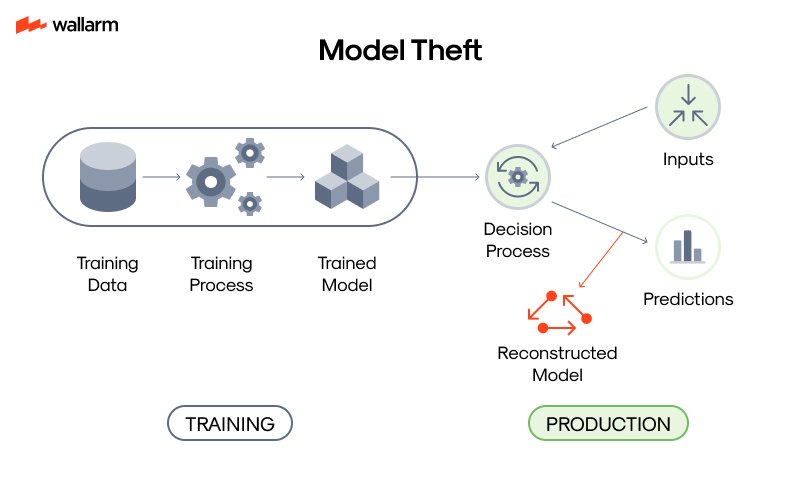
Model theft, also known as model extraction, is a type of cyberattack where an attacker replicates a machine learning (ML) or artificial intelligence (AI) model without having direct access to its internal architecture or training data. Instead, the attacker sends queries to the model—often through a public-facing API—and uses the responses to reverse-engineer a near-identical copy.
This stolen model can then be used for malicious purposes, such as:
- Bypassing security systems (e.g., facial recognition or fraud detection)
- Launching adversarial attacks using the replicated model to test weaknesses
- Avoiding licensing fees by using a pirated version of a commercial AI product
- Undermining competitive advantage by stealing proprietary algorithms
Model theft is especially dangerous because AI models represent a significant investment in time, data, and computational resources. Losing control over them can result in financial loss, reputational damage, and regulatory consequences.
How Model Theft Happens
There are several methods attackers use to steal AI models. The most common approach is through query-based extraction, where the attacker interacts with the model via an API and collects input-output pairs to train a surrogate model.
Here’s a simplified breakdown of how this works:
- Access the target model via a public or semi-public API.
- Send a large number of inputs (often random or semi-random).
- Record the outputs returned by the model.
- Train a new model using the collected input-output pairs.
- Refine the surrogate model to match the behavior of the original.
This process can be surprisingly effective, especially if the original model is exposed without proper rate limiting, authentication, or obfuscation.
Example: Query-Based Model Theft
This simple script demonstrates how an attacker could automate the process of querying a model and collecting data to replicate it.
Real-World Examples of Model Theft
These examples show that model theft is not just theoretical—it’s happening now, and the stakes are high.
Key Indicators of Model Theft Attempts
Organizations often don’t realize their models are being stolen until it’s too late. However, there are some red flags to watch for:
- Unusual API traffic patterns: High volume of queries from a single IP or region.
- Repeated queries with slight variations: Suggests systematic probing.
- Access from unknown or suspicious clients: Especially if they mimic legitimate users.
- Sudden drop in model performance: Could indicate adversarial training using a stolen model.
Monitoring for these indicators can help detect and stop model theft in progress.
Defensive Strategies Against Model Theft
To protect your AI models from being stolen, you need a multi-layered defense strategy. Here are the most effective techniques:
1. Rate Limiting and Throttling
Limit the number of queries a user or IP address can make in a given time period. This makes it harder for attackers to collect enough data to replicate the model.
2. Authentication and Authorization
Require users to authenticate before accessing the model. Use role-based access control (RBAC) to limit what each user can do.
- Use API keys or OAuth tokens
- Implement multi-factor authentication (MFA)
- Assign permissions based on user roles
3. Output Obfuscation
Reduce the amount of information returned by the model. For example:
- Return only class labels, not confidence scores
- Round probabilities to fewer decimal places
- Add noise to outputs (differential privacy)
This makes it harder for attackers to train an accurate surrogate model.
4. Watermarking AI Models
Embed unique patterns or behaviors into your model that can later be used to prove ownership or detect stolen copies.
- Add specific trigger inputs that produce known outputs
- Monitor for these triggers in the wild
- Use them as forensic evidence in legal disputes
5. Model Fingerprinting
Create a unique “fingerprint” of your model’s behavior that can be used to identify it if it’s stolen.
6. Monitoring and Logging
Track all API usage and analyze logs for suspicious behavior.
- Use anomaly detection on query patterns
- Set alerts for high-volume or repetitive access
- Correlate access logs with user identities
Comparison: Exposed vs. Secured Model API
This comparison shows how simple changes can drastically reduce the risk of model theft.
Legal and Ethical Considerations
While technical defenses are essential, legal protections also play a role. Organizations should:
- Use licensing agreements that prohibit reverse engineering
- File patents for unique model architectures or training methods
- Pursue legal action if model theft is detected and proven
Ethically, companies must also consider how their own models are trained. Using data or models without permission can lead to legal trouble and reputational harm.
Summary Table: Model Theft Defense Checklist
Use this checklist to evaluate your current defenses and identify gaps.
Sample Code: Output Obfuscation
This simple function reduces the information available to attackers while still providing useful predictions to legitimate users.
Final Thoughts on Staying Ahead
Model theft is a growing threat in the AI landscape. As more organizations deploy AI models through APIs and cloud platforms, the risk of unauthorized replication increases. By implementing strong technical, operational, and legal defenses, you can protect your most valuable AI assets from being stolen and misused.
Stay vigilant, monitor your systems, and treat your AI models like the crown jewels they are.
Adversarial Attacks in Artificial Intelligence
Adversarial attacks aim to deliberately distort input data to misguide AI decision-making processes. These manipulations are often subtle—frequently invisible to the naked eye—but cause AI models to interpret the altered data incorrectly. For instance, modifying just a few pixels in a traffic sign image can cause an object classifier to mistake a stop sign for a yield sign.
Accuracy failures triggered by such perturbations pose serious threats in task-critical domains. In self-driving cars, a misread traffic sign could trigger dangerous navigation decisions. In medical diagnostics, a manipulated CT scan might produce false negatives. In financial fraud analytics, seemingly legitimate transactions could evade flagging.
Mechanisms Behind Adversarial Perturbations
AI models learn to categorize inputs by defining mathematical boundaries separating different classes. Adversaries exploit these separation zones by calculating tiny shifts in data that nudge the input content across boundary thresholds.
Two operational strategies exist for launching these attacks:
- White-box approach: The attacker operates with full visibility into the model's structure, weight configurations, and training dataset. This enables precision-tailored attacks designed to exploit known vulnerabilities.
- Black-box approach: The intruder has no insight into the model's internals and must rely on output feedback to conduct probing and optimization. Often, this strategy leverages adversarial examples developed for other, similar models that share behavioral patterns.
Code simulation example: A convolutional neural network detecting road signs may initially output the correct label.
After injecting mathematically computed interference:
A shift in prediction from "Stop Sign" to a speed sign occurs as a direct consequence of minimal, targeted interference.
Industry-Specific Adversarial Exploits
Common Methods for Generating Adversarial Inputs
Attackers employ specific techniques with trade-offs between subtlety, power, and complexity:
- Fast Gradient Sign Method (FGSM): Computes gradient signs to introduce rapid-performed perturbations that increase loss output for targeted categories.
- Projected Gradient Descent (PGD): Iteratively applies refined noise vectors while ensuring the altered image stays within a controlled perturbation space.
- Carlini & Wagner (C&W): Generates high-success low-magnitude attacks using optimization-focused objectives that maximize stealth.
- DeepFool: Traces the smallest route to cross model decision thresholds by incrementally shifting image features.
Response Tactics to Resist Adversarial Interference
Adversarial Retraining
Expose models to both clean and corrupted samples during supervised learning. This hardens their ability to detect and dismiss deception patterns.
Input Purification
Process incoming data to remove malicious alterations via signal-level techniques:
- Coarsening image depth
- Applying Gaussian denoising
- Executing lossy compressions like JPEG re-encoding
While easy to deploy, these methods sometimes degrade essential input fidelity and reduce accuracy on legitimate cases.
Model Redundancy (Ensembling)
Deploy multiple models, each architecturally distinct or trained with varied data segments. Final predictions rely on consensus among models, reducing susceptibility to attacks targeting a specific model structure.
Gradient Obfuscation
Mask gradient information to slow down attackers’ ability to calculate useful perturbation vectors. Technique often integrated at training time. However, savvy attackers use transfer methods or numerical approximation to sidestep such masking.
Adversarial Pattern Detectors
Attach auxiliary models to the pipeline tasked with anomaly detection. These models score inputs for potential adversarial modifications and trigger rejection or alert mechanisms when detection surpasses thresholds.
Proactive Stress Testing of Models
Security emphasis includes adversarial trials during development and production. Use open-source frameworks to simulate attacks and identify blind spots:
- CleverHans: TensorFlow-compatible tool for generating various adversarial examples
- Foolbox: Offers attacks and defense benchmarking across multiple backends
- Adversarial Robustness Toolbox (ART): IBM contribution supporting multiple modalities and threat models
Recommended Practices for Hardening AI Systems
- Team specialists must research and stay updated on algorithm vulnerabilities.
- Training pipelines need checks to guarantee dataset integrity.
- Neural architectures should favor models shown to be robust under attack simulations.
- Anomaly-aware monitoring across all inference APIs prevents untracked exploitation.
- Limit external access to model endpoints using gated API keys or rate throttling.
Threat Matrix: Offensive Techniques and Matching Defensive Strategies
Example: FGSM Exploit Implementation in TensorFlow
Small-gradient additions computed via loss gradients shift the prediction in favor of an attacker’s desired class.
Operational Security Checklist: Adversarial Defense Readiness
- All models audited for adversarial vulnerability in pre-production phases
- Defense mechanisms such as adversarial retraining implemented
- Preprocessing filters enabled on model-serving pipelines
- Real-time output monitoring infrastructure deployed
- Endpoint protection enforced via access control and rate limiting
- Public access tightly controlled and exposure minimized across platforms
AI API Exploitation Vectors and Security Countermeasures
AI platforms commonly expose interfaces that allow other systems or users to request model outputs and interact programmatically. These interfaces, if exposed or misconfigured, become critical points of vulnerability.
Attackers can subvert these systems by exploiting authentication gaps, improperly managed secrets, or logical flaws in API access control. Once inside, malicious actors can siphon off data, manipulate AI decision logic, and use the system's computational resources covertly.
Attack Tactics Against AI Interfaces
Leaked Authentication Tokens
Authentication tokens such as API keys or bearer tokens grant programmatic access to machine learning endpoints. Once exposed, they give attackers undetected control over AI assets.
Weak or Missing Identity Verification
Endpoints with insecure or absent identity checks accept requests from any source. This allows automated attacks to repeatedly probe, extract, and stress system resources.
Observed misconfigurations include:
- Tokenless public endpoints
- Shared static keys across environments
- Lack of IP-based rules or client validation
Access Scope Escalation via Validation Gaps
Improperly enforced authorization boundaries allow adversaries to transform one level of access into a gateway to broader capabilities. Limited users can, via insecure endpoints, invoke unauthorized actions or permissions meant only for administrative roles.
Endpoint Enumeration and Reverse Mapping
Adversaries inspect mobile apps and browser clients to discover undocumented routes and operations. By fuzzing these hidden endpoints, threat actors can discover systemic weaknesses, extract payloads, or mimic internal services.
Credential Replay and Exhaustion Tactics
When services rely on basic authentication, attackers deploy dictionaries or reuse known leaked credentials. Without rate limits and anomaly detection, services are vulnerable to persistent brute-force credential stuffing or session hijacking.
Real-World Breach Scenarios
Data Leakage via Open AI Client Interfaces
In a brokerage’s intelligent assistant platform, a machine learning endpoint lacked tokenization and was directly queryable over the public web. The attacker formatted controlled inputs to extract metadata and user-specific training information, uncovering confidential records and triggering escalation into systems not meant for public interaction.
Compromised Medical Insight System
A biometric analytics firm embedded persistent API tokens in their test automation scripts and committed them to an accessible version control instance. Logs later revealed third-party access patterns from unknown IPs, conducting inference at scale on private patient diagnostic models.
Severity of Exploits
Unregulated presence on critical AI endpoints places organizations at risk of confidentiality breaches, model theft, and inflatable costs due to compute misuse.
Framework for Securing AI Interfaces
Verified Access with Robust Authentication Systems
Reject static key access in favor of ephemeral tokens issued by identity providers. Adopt frameworks such as OAuth2, implementing precise scopes and token expiry protocols.
Encrypted Transport Channels
Every API exchange must traverse encrypted channels (TLS 1.3 minimum) to eliminate the possibility of passive eavesdropping or man-in-the-middle injection.
Load Governance and Throttling Measures
Implement ceiling caps to prevent flooding attempts. On detection of rate anomalies, temporarily revoke access and require revalidation.
Client Context Restriction
Use allowlists to tie permissible access to specific IPs, networks, or geolocations. Systems communicating from unapproved origins are denied upfront.
Real-Time Log Analysis Pipelines
Push all request activities to audit pipelines that flag new usage patterns, unusual response timings, and mismatched token-client pairs.
Flag scenarios include:
- Geographic outliers accessing accounts
- Sudden increase in model usage volume
- Inconsistent client fingerprints across tokens
Secret Isolation and Lifecycle Enforcement
Passwords, tokens, and certificates must reside in cryptographically protected stores. Centralize access in tight-scoped secret managers and rotate periodically.
Use services like AWS Secrets Manager or Azure Key Vault for policy-enforced lifecycle governance.
Layering Through API Gateways
Route requests through secure ingress platforms that provide deep request inspection, pattern matching, threat classification, and dynamic routing based on user privilege or risk score.
Common platforms:
- Apigee (policy enforcement)
- AWS API Gateway (serverless integration)
- Kong with OPA plugins
- NGINX reverse proxy with ModSecurity
Deployment Patterns: Hardened vs Exposed
Secure Interaction Blueprint
- User authenticates using an MFA-integrated interface.
- Identity server issues a scoped, short-term access token.
- API gateway inspects request headers and validates session.
- If usage criteria pass, the AI model processes the query.
- All transactions get logged with timestamp and confidence scores.
- Anomaly engine correlates usage against behavioral baselines.
Red Team Simulation Tasks for ML Endpoints
Programming Practices That Eliminate Access Vulnerabilities
- Avoid inline secrets by extracting them to secured configuration layers.
- Sanitize and validate incoming parameters rigorously.
- Choose maintained libraries with active security patches.
- Audit code dependencies with vulnerability scanners before deployment.
- Commit to code reviews focusing on privilege and access flow.
CI/CD Pipeline Security Enablers
Automations must enforce security standards persistently through build, test, and deploy phases.
Summary: Core Tactics for API Endpoint Fortification
AI Hallucinations Explained
AI hallucinations occur when a language model provides details that appear logical or authoritative but are incorrect, invented, or unverifiable. Systems like ChatGPT, Claude, or Gemini can produce plausible-sounding responses without grasping the legitimacy of their content. These hallucinations arise not from technical errors, but from design limitations in predictive modeling: such systems determine output based on probability rather than empirical fact.
Patterns learned during training become the basis for future outputs. If misinformation was present frequently enough in training data, the model may reproduce it confidently. This behavior becomes riskier in professional settings—legal drafts, healthcare communication, financial forecasting—where users might trust output at face value.
Real-Life Scenarios of Hallucinated Output
These failures aren't harmless. When unchecked, fictional information escalates into reputational, financial, or legal consequences.
Roots of Hallucinated Responses
- Flawed Training Sets: A language model's responses are molded by datasets collected from online sources. Errors, biases, and fictional content embedded within this material transfer directly into model behavior.
- Stagnant Knowledge Base: Unless models incorporate tools for accessing current databases, their knowledge remains outdated. Without real-time correlation, fact accuracy can't be assured.
- No Internal Reality Testing: Generation mechanics favor statistically likely responses, not verified truths. Without embedded validation layers, no source review occurs.
- Prompting Volatility: Changing the way a question is asked can result in entirely new outputs—some less reliable than others. Small phrasing shifts can yield drastically different levels of correctness.
- Projection of Authority: Even made-up facts are expressed with fluent confidence. Unless listeners are trained, these inaccuracies go unspotted.
Classification of False Outputs
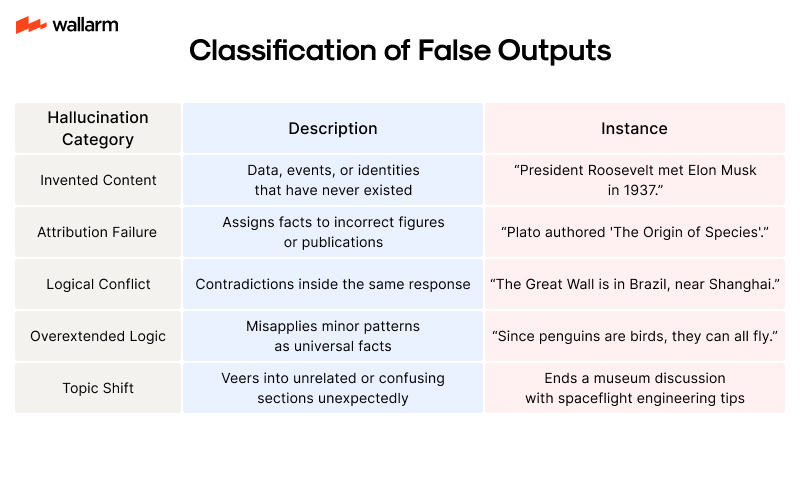
Identifying categories makes diagnosing vulnerabilities easier across diverse environments.
Documented Incidents from Misleading Outputs
- Federal Court Filing, 2023: A lawyer submitted a brief incorporating six legal precedents fabricated by an AI tool. All citations were fictional. Resulting penalties included a monetary fine and a formal warning on AI usage in court filings.
- Digital Health Bot Incident: A virtual consultant erroneously recommended combining two contraindicated prescriptions. The clinic had to issue a public retraction and update safety protocols.
- Viral Death Hoax: A language model-generated news blurb claimed a famous actor had died. The false article spread across social media and required public statements from both media outlets and the celebrity’s representatives to correct the falsehood.
These examples highlight the potential magnitude of failure when oversight is minimal.
Techniques for Verifying AI-Generated Claims
- Independent Source Comparison: Match outputs against authoritative data repositories or publications. Cross-checking identifies discrepancies.
- Integrated Fact Services: Enhance your language pipelines using tools like third-party claim verifiers, which compare model output against regularly updated data sources.
- Refined Input Writing: Control hallucination rates by drafting direct and scoped prompts. Open-ended queries increase risk.
- Mandatory Human Oversight: Introduce review checkpoints where professionals review AI-generated results prior to usage in critical workflows such as law, medicine, and policy.
- Answer Confidence Indicators: Leverage tools where possible that show how strongly the model "believes” its own output. Higher scores invite deeper scrutiny, not trust.
Tactics to Limit Hallucinations Within Operations
Domain-Specific Fine-Tuning
Train models on curated data from your niche. This restricts associations only to verified, relevant knowledge, making outputs less prone to nonsense or overreach.
Protective Output Layers
Deploy moderation scripts or risk filters that monitor output against red flags—unverifiable claims, statistically unlikely phrases, or skewed citations.
User Training
Equip personnel with AI operations literacy. Teach them how to approach outputs critically and when escalation for human validation is necessary.
Ongoing Output Monitoring
Store and review generated content routinely. Pattern recognition can pinpoint vulnerabilities that manifest repeatedly under specific inputs or topics.
Grounded Retrieval-Driven Responses
Augment models with document fetch capabilities. With each prompt, attach support materials retrieved from authoritative knowledge bases.
The model builds responses using content from these live or static references instead of relying only on latent memory.
Classic Model vs. Retrieval-Augmented Alternative
Policy and Governance Guidelines
- Procedural AI Usage Rules: Mandate when AI can be used autonomously, and when manual review is compulsory.
- Validation Standards: Require independent citation checks in sectors like healthcare, finance, and compliance.
- Issue Reporting Channels: Create dashboards for employees to report problematic AI behavior for fast triage and analysis.
- Model Selection Based on Domain Metrics: Favor models validated by industry-specific testing over general-purpose benchmarks.
- Model Retraining Schedule: Regular refresh cycles for your model using updated trusted sources prevent outdated nonsense from creeping into production.
Risk Prevention Toolkit Comparison
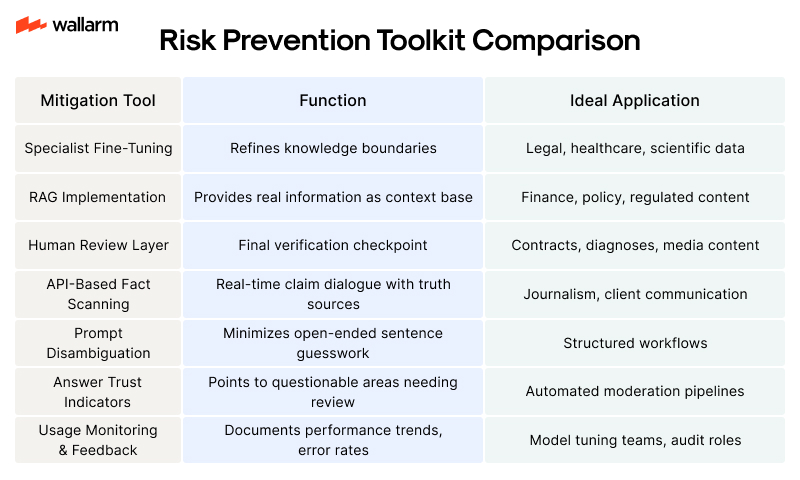
Deploying multiple techniques in tandem significantly reduces the chance of hallucinated content escaping detection, supporting accuracy across AI deployments.
The Hidden Dangers of Overreliance on AI
Artificial Intelligence has become a trusted partner in many business operations. From automating customer service to detecting fraud, AI systems are now embedded in critical workflows. But as organizations lean more heavily on these systems, a new and often overlooked security risk emerges: overreliance. When companies place too much trust in AI without proper oversight, they expose themselves to operational, legal, and reputational threats. This chapter explores the real-world consequences of overreliance on AI, how it manifests in different industries, and what practical steps organizations can take to mitigate this silent but serious risk.
When Automation Becomes a Crutch
AI is designed to assist, not replace, human judgment. However, many businesses fall into the trap of letting AI make decisions without human review. This is especially dangerous in high-stakes environments like healthcare, finance, and cybersecurity.
Example: Financial Sector
Let’s consider a trading firm that uses an AI model to execute high-frequency trades. If the model misinterprets market signals due to a rare event (like a geopolitical crisis), it could make thousands of incorrect trades in seconds. Without a human in the loop to catch the anomaly, the firm could lose millions before the system is shut down.
This table shows how human oversight can prevent AI from making catastrophic decisions. When AI operates without checks, even minor glitches can snowball into major disasters.
Blind Trust in AI Outputs
Another form of overreliance is assuming that AI outputs are always correct. This is particularly risky when the AI is used in decision-making roles, such as approving loans, diagnosing patients, or screening job applicants.
Case Study: Healthcare Diagnostics
A hospital uses an AI tool to analyze X-rays and flag potential tumors. Over time, doctors begin to trust the tool so much that they stop reviewing the scans themselves. One day, the AI misses a tumor due to a rare imaging artifact. The patient’s diagnosis is delayed, leading to worsened outcomes and potential legal action.
Why This Happens:
- Cognitive offloading: Humans naturally offload tasks to machines to reduce mental effort.
- Automation bias: People tend to believe that automated systems are more accurate than they really are.
- Lack of transparency: Many AI models are black boxes, making it hard to question their decisions.
Checklist: Signs Your Team Is Overtrusting AI
- Decisions are made without human review.
- AI outputs are rarely questioned or audited.
- Staff lacks training to interpret or challenge AI results.
- No fallback procedures exist if the AI fails.
- AI errors are discovered only after external complaints.
If you checked more than two items, your organization may be at risk of overreliance.
AI in Cybersecurity: A Double-Edged Sword
AI is increasingly used to detect and respond to cyber threats. While this can improve response times and reduce manual workload, it also introduces a unique risk: attackers can manipulate the AI itself.
Scenario: AI-Powered Intrusion Detection
An AI system monitors network traffic and flags suspicious behavior. Over time, attackers learn how the system works and begin to craft their attacks to avoid detection. Since the security team relies entirely on the AI, these stealthy attacks go unnoticed.
Comparison: Traditional vs. AI-Driven Security
AI-driven security is powerful but can become a liability if not paired with human expertise. Attackers can exploit the very intelligence that’s meant to protect you.
The Legal and Ethical Minefield
Overreliance on AI can also lead to legal and ethical violations. Many industries are governed by strict regulations that require explainability, fairness, and accountability—qualities that AI doesn’t always guarantee.
Example: Hiring Algorithms
A company uses an AI tool to screen job applicants. The tool favors candidates from certain zip codes, unintentionally discriminating against minority groups. Because the HR team relies solely on the AI, the bias goes unnoticed until a lawsuit is filed.
Legal Risks of AI Overreliance:
- Discrimination lawsuits: If AI decisions are biased.
- Compliance violations: If AI fails to meet regulatory standards.
- Data privacy breaches: If AI mishandles sensitive information.
- Lack of accountability: If no one can explain how a decision was made.
Ethical Checklist for AI Use
- Can the AI’s decision be explained in plain language?
- Are decisions audited for bias and fairness?
- Is there a clear chain of accountability?
- Are users informed when AI is making decisions?
- Is there a way to appeal or override AI decisions?
Failing to meet these ethical standards can damage your brand and invite regulatory scrutiny.
The Illusion of Scalability
AI promises to scale operations quickly and efficiently. But scaling without control can amplify errors. A flawed AI model deployed across multiple regions can cause widespread damage before anyone notices.
Example: E-commerce Recommendations
An online retailer uses AI to recommend products. A bug in the model causes it to recommend adult products to children’s accounts. Because the system is deployed globally, the issue affects millions of users before it’s caught.
Scaling Risks:
- Error propagation: One mistake affects all users.
- Localization issues: AI may not adapt well to different cultures or languages.
- Infrastructure strain: AI models require constant updates and monitoring.
Best Practices for Safe Scaling
- Pilot first: Test AI in a controlled environment before full deployment.
- Monitor continuously: Use real-time dashboards to track AI performance.
- Limit scope: Don’t let AI make critical decisions without human backup.
- Update regularly: Retrain models to reflect new data and conditions.
- Decentralize control: Allow local teams to override AI when needed.
Code Snippet: Human-in-the-Loop AI
Here’s a simple Python example showing how to integrate human review into an AI decision pipeline:
This approach ensures that low-confidence predictions are flagged for human intervention, reducing the risk of blind trust in AI.
Organizational Culture and AI Dependency
Overreliance on AI is not just a technical issue—it’s a cultural one. When leadership promotes AI as a magic bullet, employees may feel discouraged from questioning its decisions. This creates a dangerous feedback loop where errors go unchallenged.
Symptoms of a Toxic AI Culture:
- AI is treated as infallible.
- Employees are penalized for overriding AI.
- No one knows how the AI works.
- Training focuses only on using AI, not understanding it.
How to Build a Healthy AI Culture
- Promote transparency: Encourage open discussions about AI limitations.
- Reward skepticism: Recognize employees who catch AI errors.
- Invest in training: Teach staff how AI works, not just how to use it.
- Create escalation paths: Make it easy to report and review AI mistakes.
Summary Table: Risks of Overreliance on AI
Overreliance on AI is a silent threat that grows with every new deployment. By recognizing the signs early and implementing safeguards, organizations can enjoy the benefits of AI without falling into the trap of blind trust.
Strengthening AI Security Through Layered Defense
A single line of defense is never enough when it comes to protecting AI systems. Just like traditional IT infrastructure, AI requires a multi-layered security approach. This means combining technical safeguards, human oversight, and continuous monitoring to ensure that AI models, data pipelines, and APIs are not only functional but also secure.
A layered defense strategy should include:
- Data validation pipelines to prevent data poisoning.
- Access control mechanisms to restrict who can interact with AI models.
- Encryption for both data at rest and in transit.
- Monitoring tools to detect anomalies in model behavior.
- Regular audits of AI training datasets and model outputs.
Each layer adds a barrier that makes it harder for attackers to succeed. When these layers work together, they create a resilient AI environment that can withstand both internal errors and external threats.
Human-in-the-Loop (HITL) Systems for AI Oversight
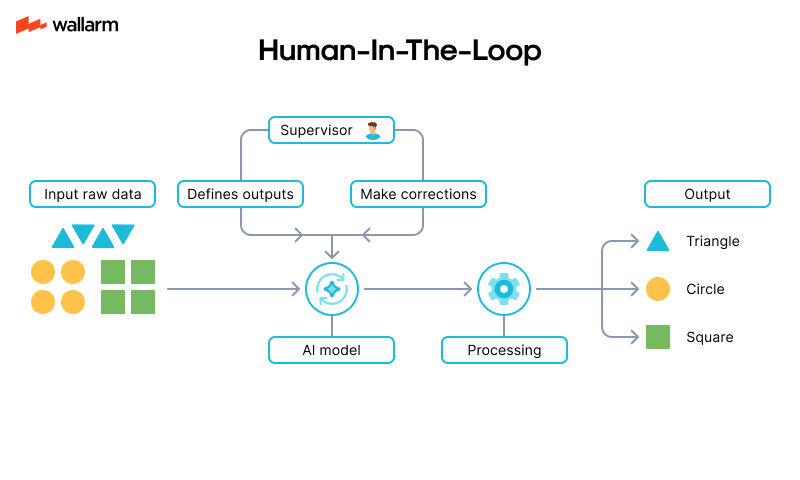
AI systems are powerful, but they are not infallible. One of the most effective ways to reduce risk is to keep humans involved in the decision-making loop. Human-in-the-Loop (HITL) systems allow AI to make suggestions or predictions, but require human approval before action is taken.
Benefits of HITL:
HITL is especially critical in high-stakes environments like healthcare, finance, and cybersecurity, where a wrong decision can have serious consequences. By combining machine efficiency with human judgment, organizations can reduce the risk of AI hallucinations and overreliance.
Real-Time Monitoring and Anomaly Detection
AI systems are dynamic. They learn, adapt, and evolve over time. This makes real-time monitoring essential. Without it, you may not notice when your AI model starts behaving abnormally due to adversarial inputs, data drift, or unauthorized access.
Key metrics to monitor:
- Input distribution changes – Indicates data poisoning or drift.
- Output confidence scores – Helps detect hallucinations or anomalies.
- API call frequency – Can reveal abuse or scraping attempts.
- Latency spikes – May indicate DDoS attacks or resource exhaustion.
- Unauthorized access attempts – Suggests credential theft or API abuse.
Use automated tools that can flag these anomalies and trigger alerts. Integrate them with your SIEM (Security Information and Event Management) systems for centralized visibility.
Secure Your AI Supply Chain
AI systems often rely on third-party libraries, pre-trained models, and external APIs. Each of these components introduces a potential vulnerability. Securing the AI supply chain means verifying the integrity and trustworthiness of every external dependency.
Checklist for AI Supply Chain Security:
- ✅ Use only vetted and signed open-source libraries.
- ✅ Scan third-party code for known vulnerabilities.
- ✅ Validate pre-trained models with checksum verification.
- ✅ Monitor API dependencies for changes or breaches.
- ✅ Maintain an inventory of all external components.
Just as software supply chain attacks have become more common, AI supply chain attacks are on the rise. Attackers can inject malicious code into a model or library that your AI system depends on. Regularly update and audit your dependencies to stay ahead of these threats.
Role-Based Access Control (RBAC) for AI Systems
Not everyone in your organization needs access to your AI models or training data. Implementing Role-Based Access Control (RBAC) ensures that only authorized personnel can interact with sensitive AI components.
Example RBAC Policy:
RBAC not only limits exposure but also creates an audit trail. If something goes wrong, you can trace it back to the responsible role or individual. This is crucial for compliance and forensic investigations.
Encrypt Everything: Data, Models, and Communications
Encryption is your last line of defense. Even if an attacker gains access to your infrastructure, encrypted data and models are much harder to exploit.
What to encrypt:
- Training data – Prevents data leakage during storage or transfer.
- Model weights – Protects intellectual property and prevents model theft.
- API traffic – Secures inference requests and responses.
- Logs and telemetry – Ensures sensitive information isn’t exposed.
Use strong encryption standards like AES-256 for data and TLS 1.3 for communications. Also consider using homomorphic encryption or secure enclaves for sensitive AI workloads.
Incident Response Plan for AI-Specific Threats
Traditional incident response plans often overlook AI-specific risks. Your organization needs a tailored plan that addresses threats like model inversion, adversarial attacks, and API abuse.
AI Incident Response Workflow:
- Detection – Use anomaly detection tools to flag suspicious behavior.
- Containment – Isolate the affected model or API endpoint.
- Eradication – Remove malicious inputs or compromised components.
- Recovery – Retrain models if necessary and restore from backups.
- Post-Incident Review – Analyze root cause and update defenses.
Make sure your security team is trained to handle AI-specific incidents. Run tabletop exercises to simulate attacks and test your response capabilities.
Educate Your Teams on AI Security Best Practices
Security is a shared responsibility. Everyone from developers to executives should understand the risks associated with AI and how to mitigate them.
Training topics to cover:
- How data poisoning works and how to prevent it.
- Recognizing signs of model theft or tampering.
- Understanding adversarial inputs and their impact.
- Safe usage of AI APIs and authentication best practices.
- Identifying and reporting AI hallucinations.
Offer regular training sessions, create internal documentation, and encourage a culture of security awareness. The more your team knows, the harder it is for attackers to succeed.
Automate Security Testing for AI Pipelines
Manual testing is not scalable. Automate your security checks to ensure continuous protection across your AI lifecycle.
Automated tests to implement:
- Data validation scripts – Check for anomalies or malicious patterns.
- Model integrity checks – Verify that weights haven’t been altered.
- API fuzzing tools – Test endpoints for unexpected behavior.
- Access control tests – Ensure RBAC policies are enforced.
- Dependency scanners – Identify vulnerable libraries or models.
Integrate these tests into your CI/CD pipeline so that every update is automatically vetted for security issues before deployment.
Try Wallarm API Attack Surface Management (AASM)
One of the most overlooked areas in AI security is the API layer. APIs are the gateway to your AI models, and if left unprotected, they can be exploited to steal data, overload systems, or manipulate outputs. This is where Wallarm’s API Attack Surface Management (AASM) solution comes in.
Wallarm AASM is an agentless detection platform built specifically for the API ecosystem. It helps organizations:
- Discover external hosts and their exposed APIs – Know exactly what’s accessible from the outside.
- Identify missing WAF/WAAP protections – Ensure that every API is shielded from common threats.
- Detect vulnerabilities in real-time – Find and fix weak points before attackers do.
- Mitigate API leaks – Prevent sensitive data from being exposed through misconfigured or outdated endpoints.
Unlike traditional tools, Wallarm AASM doesn’t require agents or invasive integrations. It works seamlessly with your existing infrastructure and provides actionable insights that help you secure your AI-driven APIs.
Engage to try this product for free at https://www.wallarm.com/product/aasm-sign-up?internal_utm_source=whats and take the first step toward a smarter, more secure AI environment.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")