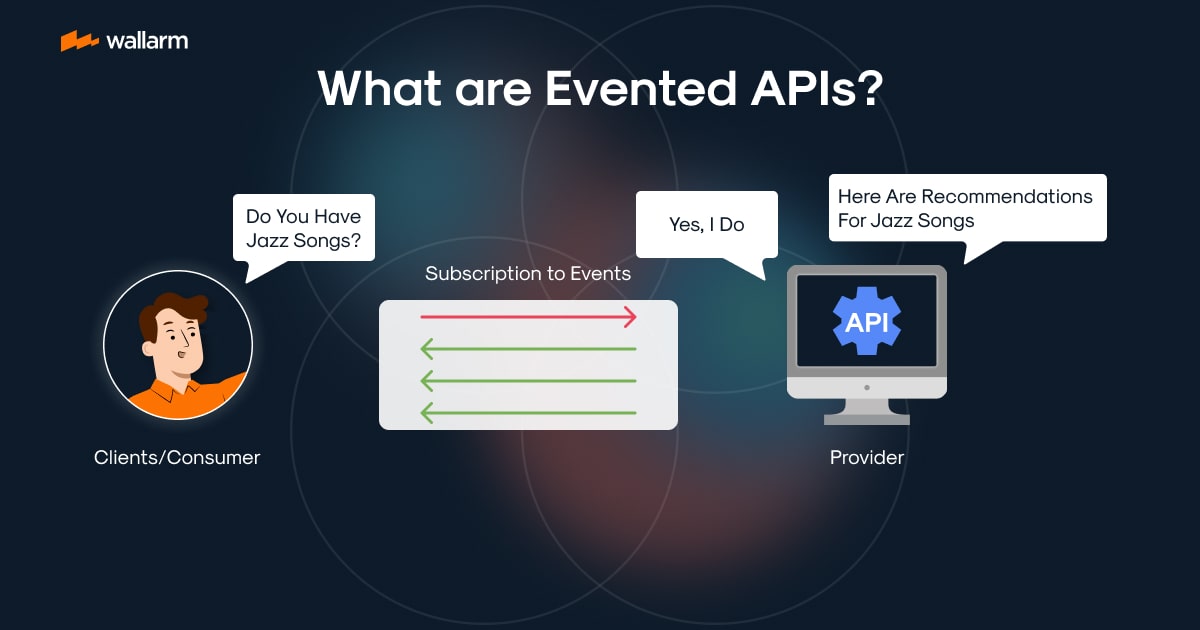
Recovery point objective concept
What Is The Recovery Point Objective?
The recovery point objective is an approximate or accurate measure of the extent of a disaster (such as data loss) by using the time of occurrence as the reference point, to determine the extent of data that needs to be recovered. Essentially, it is the measure of the specific time of disaster in order to determine the extent of damage control and recovery action an organization will take. Think of recovery point objective like some sort of time travel mechanism; it is like going back in time to see the source of a problem; to see when exactly it happened and how far back in time the recovery process would cover.

A little contextual explanation should properly highlight the immense importance of RPOs to organizations (especially in cyberspace). Imagine when a cyber-structure (let’s say a database) becomes subject to attacks from criminals. Naturally, the immediate effects of these cyber-attacks are disruption of service (as in the case of DDOS attacks) and data loss. As an organization – in the event of a data loss disaster – the first step would be to address the loophole and initiate a sequence of backup for the essential sets of data. This may prove to be difficult when the data loss is partial.
In continuation, the organization in question – without the necessary information on the extent of the data loss – stands the risk of data tautology. This is where RPOs come in; they help to ascertain the exact time frame of any attack and the amount of data that needs restoration. That way, the lost data are recovered fully (with respect to time) without any repetition or loss.
The immense importance of data and a proper database structure is no longer news. As far as technology and cyber development are concerned, data translates to power. Without argument, this truth cuts across all spheres of the global economy. Due to that, every organization (especially those in the cyber industry) needs to have recovery point objectives as part of disaster control measures. For the purpose of evidence, the following are some of the situations that may warrant the use of RPOs;
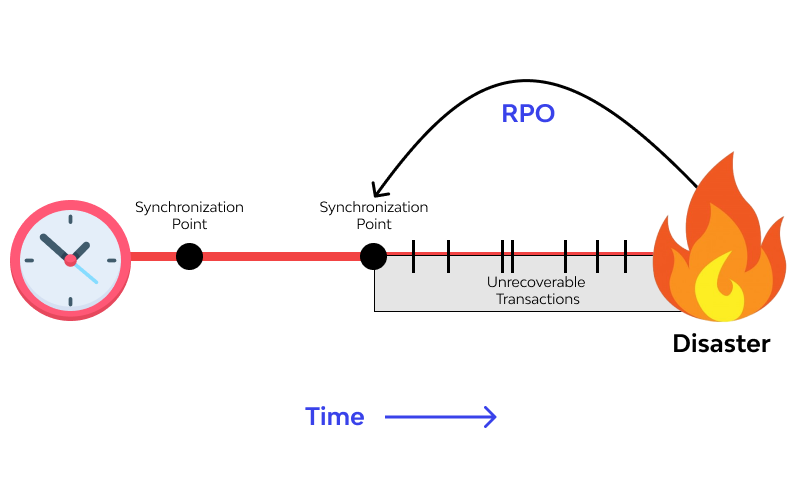
Data loss – This could resultfrom dreaded cyber-attacks from criminals or database system failure on thepart of the organization
- Data loss – This could result from dreaded cyber-attacks from criminals or database system failure on the part of the organization
- Ransomware – In a situation where a database is attacked and users are restricted from having any access to their data. This could be particularly serious when users depend on databases as reminders for certain personal information
- Prolonged power outage – especially when data have not been saved on the database
- User error problems
- Data corruption – Just like data loss, this could be due to certain attacks on the company’s database or a malfunction in the database system. Since data corruption renders a data set inaccessible (or let’s say unusable), a backup procedure has to be initiated.
Recovery point objectives can be used to determine;
- The size of the data lost after a disaster (irrespective of the intensity)
- How many times (frequency) you need to back up your data just in case of a disaster
- The exact time frame of specific disasters
How Does A Recovery Point Objective Work?
The fundamental approach of a recovery point system is simple – it defines a specific timeframe for data loss. In other words, it sets a standard for how much time data can be kept in a database before backup. After that specific time of time has passed an automatic backup occurs. In the same vein, any data lost within that time frame gets restored when the RPO is activated. Like all other aspects of cybersecurity, this time frame is predetermined by the administrator. Technically, the time allowed for data to be lost before an automated recovery is the enterprise loss tolerance.
The enterprise loss tolerance is usually very specific to different organizations. Here are some of the factors that affect the enterprise loss tolerance for different companies;
- Company size – The size of an organization – in most cases – may be affect the size of the organization’s database size. This is very crucial in setting a recovery point objective. An organization may decide to reduce the time for recovery because of the weight of the data set in the context
- The size of the database – Some company’s database is continually functional compared to some others. The nature of the service of some organizations may be data-intensive when compared to some others. For instance, an organization like Facebook may have to handle a larger amount of user data than McDonald's. This plays a great role in determining the enterprise loss tolerance of an organization.
- The nature of the data contained – The sophistication of database security and anti-data loss protection may differ with organizations with respect to the nature of the data in their database. This may also affect what the enterprise loss tolerance of their database would be. For instance, an institution like the CIA – with very sensitive data – may be more careful with recovery point objectives than a restaurant or a sushi brand.
Summarily, a response time objective is activated by putting up an ideal backup frequency. That way, the system automatically backs up the data after a certain period of time has elapsed. Security administrators often set (or adjust as the case may be) this as a setting synchronized with the software used for data storage.
For the purpose of simplicity; think of the autosave and auto-recovery feature of Microsoft word. When you work with the recent versions of the Microsoft work app, it automatically saves up your document (after your first save). If your device experiences a power outage, you can always get your work back at the last time of the save. As an additional feature, the auto-recovery panel appears on the left side of the application interface.
On close observation, you would discover that the documents save automatically at a Microsoft-determined time interval. That synced feature that measures and regulates the time interval is the recovery point objective. In essence, the whole principle of “last saved document”, auto-recovery of the different saved versions of your documents, and the continuity, is what the recovery point objective is all about.
What Is The Relationship Betweem RTO And RPO?
Real-time objective happens to confused with recovery point objective; especially with the “time” tag, it has. In theory and practice, these two are very distinct. However, they do share some things in common. In fact, RPOs and RTOs are always mentioned together in disaster control and cybersecurity. This is solely because they share the common end of data loss prevention and damage control. Let’s carefully observe the contrast between these two; how similar they are, how different they are, and the relationship between them when it comes to database security.
First, what does “real-time objective” even mean? It basically defines the time frame between the disruption of a system and the time when this would wreak any serious havoc on the system. That is, it measures some kind id like a safety window period. It’s like asking what time you have left before cyber framework May Day. That is, it answers the question of the time gap between database disruption and completion of the system recovery procedure.
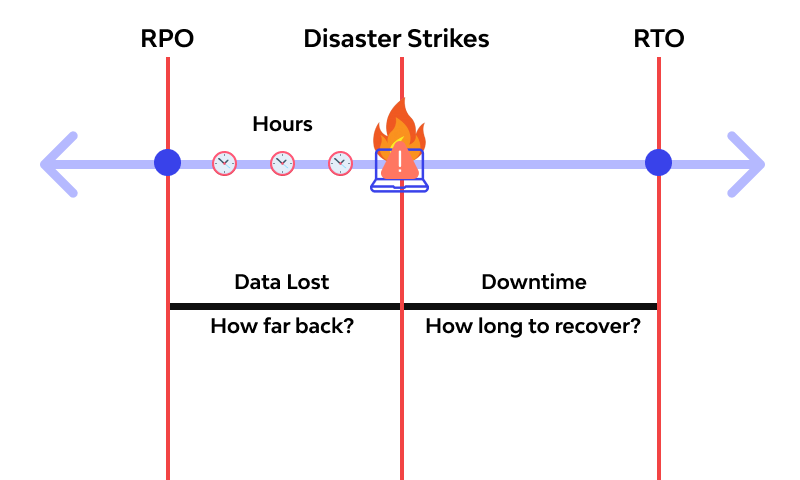
So what similarities are there between them? The only traceable similarity between RPOs and RTOs is that they both allude to managing a cyber-disaster (especially). Other than that, there are quite a number of significant differences between them – in terms of goals and how do they work to achieve that end. Here are some of the basic difference between RPOs and RTOs;
- Response point objective measures the quantity of data that needs to be recover and makes sure those sets of data are recovered. It does measure time too but as a point of reference instead of the actual human
- Real-time Objectives measure time (actual time) needed before danger zone – this difference fundamental (even in the definition).
- RPOS is set to refer to a time of the past so as to be able to make the correct decisions.
- RTOs are designed to measure a time that has a futuristic conclusion. In short, unlike RPOs, they maintain time and take a record of how much time before the database device goes haywire.
- Both the RPO and RTO are not fixed figures; they are susceptible to how large the effect of a data breach is. They are also susceptible to the sophistication of the attacker or the level of framework dysfunction (as the case may be). The extent to which the factors affect the system or the database in question is directly proportional to the RPO and RTO of the systems in question.
Finally, the relationship between RTO and RPO with regard to disaster management is simple; the whole process of time measurement, response, and backup must be within the real-time objective. Both are important and must be factored into the business plans of any serious organization with a functional database (or network) security structure.

Sampler Tiers You Can Use When You Want To Choose The RPO For Your Business
Now that you know a little about RPOs and their importance for your business, it is also important to know the different tiers available for different business sizes and nature. A kaleidoscope of factors (nature, size) – as discussed above – affects a business’s choice of range in this context. Here are some of the examples of tiers you can use;
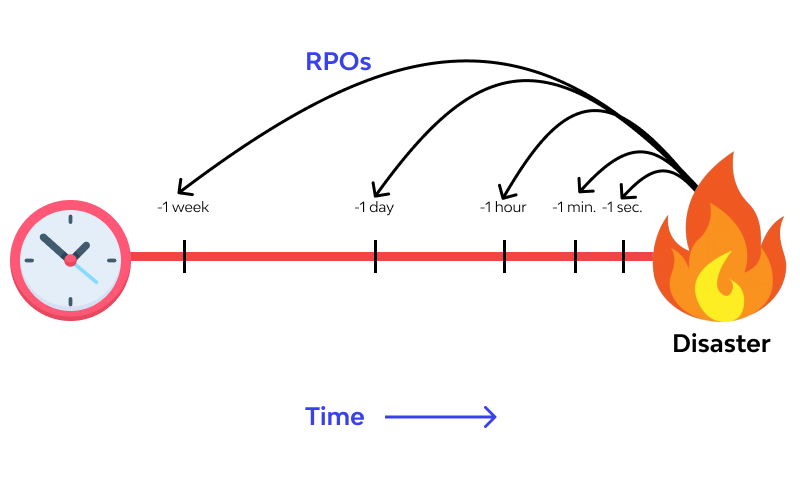
0-1 HOUR
Remember, RPOS is measured in hours. If your business requires intermittent monitoring and securing of data, this is the best RPO tier for you. This tier of RPO is used in businesses with high data flow and many variables. Therefore, if you run a financial institution (let’s say a bank) or you are in charge of records in hospitals or universities – you may use this range of hours as your RPO.
1-4 HOURS
This tier of RPO is available to organizations with a sensitivity level that is relatively lower compared to the above institutions. This RPO tier is used for certain sub-sections of an organization’s database because of the sensitivity of those sub-sections. Examples of such include log records, time books of staff activity, customer information sections, a grocery store list of sales.
4-12 HOURS
This tier of Response point objective is used for businesses with a relatively free data set compared to the two above. In some instances, the time required for gathering complete data set could make a business fall into this category. Few examples of data sets in this category include Email lists, marketing records, sales logs etcetera.
13-24 HOURS
RPO tiers in this category are not as sensitive as the above. The database of these businesses or the subsets in question can still tolerate up to 24 hours of an RPO backup. These businesses have less data activity when compared to the top-tier RPOs. Some examples of these subsections include;
The human resource management department, the purchase records of a business,
The above examples are by no means fixed. It always left to the discretion of the administrator to make the judgment of data sensitivity and set up an RPO tier. In other words, a human resources department may decide that the 1-4 hours is the best for his organization. So it is best for you to first gauge the extent of a database breach on the business or subsection. It is after that you can choose from any of the tiers above.
Some other factors like company finances and the administrator’s levels of expertise are some of the external factors that may also determine the tier of RPO that can be used in a business. Irrespective of the tier, it is important that demo crashes are introduced into the databases of any organization to test the efficiency of the RTO and RPO fixed. That way, the lapses are exposed and the administrator has the foresight of his next decisions in the instance of a cyber-attack or system software malfunction.
How To Calculate Your Response Point Objective
As stated earlier, the RPO of organizations differs,s and they are determined by a couple of distinct factors. Let’s examine – from the perspective of an organization – what it means to set an RPO for its database security. At this point, you want to calculate your organization’s RPO; you want to determine what tier of RPO would be suitable for the database of your business. Here is a detailed explanation of the different things to consider when calculating RPO and determining a suitable RPO tier;
- Create a list of the various types of datasets you may need to keep in your business – The first step to calculating the RPO for your business is to highlight all the types of data that you would need to record within the space of your operation. Depending on the type of business you run, creating a data set types list may be difficult. You could employ the use of a data analyst (and data analysis tools) to make it easy. Furthermore, a priority assessment would help you determine the most important types of data type you need to consider. That way, you can put together a list without much stress.
- Conduct risk analysis on these data types – Armed with a clear list of the various types of data you intend to keep for your business. You may want to run a deeper priority analysis. You need to determine the most important ones that could cost you a lot in the event of a security breach or a system malfunction. For instance, it could be your financial records if you run a financial institution, it could be your customer’s private data if you run a telecommunication company, it could even be transaction histories. You need to properly consider the types of data set that are crucial to the continuity of your business.
- Now is when to consider the time factor – Now that you armed with the above information, it is time to consider how long your business can hold on if you lose these sets of data. How much time would you need to recover when you no longer have access to the sets of data in your priority list? Would it be immediate close of operation? Would it take you a couple of seconds? Putting your major value proposition into consideration as a business entity would go a long way to help you determine the perfect time frame.
- That is it; you can set up your RPO already – The above questions have given you a perfect representation of when your response point objective (even RTO) is. Now that you have successfully gotten your RPO, the next step is to synchronize it into your database and recovery system. After that, you no longer need to worry much about the abrupt data breaches as before. Response time rates can vary from a few seconds (for a business that cannot handle data loss at all) to 24 hours. By the time you successfully answer the questions above, you can give an approximate time value and set your RPO as that.
Why Is an RPO Necessary To Your Organization
To reiterate the whole point of this exposition; RPOs are very important components of disaster control and management for any organization
By now, you have most likely picked up a few reasons why RPOS is necessary to your organization. However, let’s take a closer look at the importance of having a proper RPO structured into your database security;
- RPOs are directly linked with the flow of a business – In every business, data is kept in one way or the other. As businesses grow (both in size and in age), the amount of data they need to store increases. Most times, easy access to these sets of data define perfection in service delivery and business decisions. For instance, in a food organization, the sales data that is recorded at the introduction of new recipes is an indicator of the market’s reception of that recipe. This data would be a strong determinant in the decision-making process of the company when it comes to recipe re-introduction. Now imagine the organization is 40 years old; it needs to be able to store its data of 40 years successfully (digitally). The loss of these data could mean that the company would run out of business. With the proper RPO system in place, data loss is assuredly forestalled irrespective of any technical inconsistency.
- RPOs mean speed, time, accuracy, and immunity – Recovery point objectives help to forestall the issues that may be attributed to the manual panic backup process. In the case of a manual recovery process, the organization is susceptible to data loss that may occur due to human error. For instance, an individual may likely miss out on a couple of files if he is meant to copy and paste from a large directory. Even in the case of multiple personnel, a slight misunderstanding or wrong interpretation of information may lead to massive data loss. Furthermore, automated RPOs save manpower and time.
What this means in continuation is that it would take a computed RPO less time to pull off data recovery when compared to human efforts. In the same vein, it saves the organization the problem of diverting manpower to solving the problem of data loss. An organization would always need as many people as possible to engage in productive company activity rather than monotonous data recovery processes, don’t you think? Finally, automation guarantees speed, it would take a system with automated RPOs less time to accomplish data backup and recovery than it would human beings. Human effort is more likely to exceed the RTO and cause irreparable damage to the database when compared to automatic Recovery Point Objectives. Being able to work your way around those three setbacks provides some sort of immunity to the repercussions of data loss for businesses. How superb is that?
Implications Of RPO Tier Choice
RPOs – as we have discussed – is measured in time. The time frame choice of an organization’s RPO is a strong determinant of how much data would be lost before recovery. In essence;
- Low RPOs mean that small or noamount of data would be lost needs to be lost before an auto-recovery processis activated
- High RPOs on the other hand meanthat a substantial volume of data would be lost before the initiation of an already automated recovery process.
Summarily, the timeframe width of an RPO is inversely proportional to theamount of data susceptible to lose before recovery.
SUMMARY AND CONCLUSION
RPOs are one of the most effective means of disaster management for all sets of business, especially when it comes to data loss prevention. To reiterate this, let’s check a brief recap of what has been written;
- RPOs are a measure of the disaster range and the extent of recovery a database (this is specific to context) may need to undergo with respect to time frame
- RPOs are important in various instances of disaster and system failure. For instance, power outages, Ransome wares, data attacks, data corruption, user error problems, and so on.
- RPOs are used to determine some important things like data size, backup frequency, and disaster time-frame
- RTOs are distinct from RPOs. RTOs is the time frame that the system can stay without backup before it goes totally non-functional
- Both RTOs and RPOs are not fixed values for all organizations. They differ with a couple of factors that include data nature, data size, company budget, and so on.
- Calculating RPOs for your business requires a series of procedures and decision making that needs to be done by the stakeholders of the organization in question
- RPOs are proven to be a necessity for all organizations that operates a database system. It is not necessary for all the data sets in an organization’s database should be under the same RPO length. They may also differ from the data subset.
- The width of an RPO time frame is inversely proportional to the amount of data loss that the affected database would experience.
Finally, database management and cybersecurity have evolved with time. Cybercriminals have become smarter due to the sophistication of their resources. Aside from this fact, data disasters are not predictable in reality. Sometimes, they happen without tear and wear signals from the engines or the algorithms. Due to these things, organizations, businesses, and institutions have to not only properly define recovery point objectives for their databases but also have to continually optimize the RPOs and their data framework. The future of computing is data. The future of global authority is computing. At the moment, the world has begun to recognize this fact and to shift its gaze towards data collection, management, and control. It is only logical in this situation that all organizations that intend to stay relevant through the data revolution should pay more attention to data preservation. Recovery point objectives, recovery time objectives, and all other components of disaster control should therefore attract a significant part of an organization's budgetary considerations.
FAQ
References
Subscribe for the latest news