Rate Limiting
Things work best when they are controlled and processed strategically. It’s true in the computer network world as well as there is a concept, rate limiting, estimating how much traffic a network interface should deal with or how many APIs can be used at a time.
A performance-optimization strategy, rate limiting is a vast topic and is covered extensively in the post. What is it, how it works, what’s its role in API security, and many more rate-limiting related questions are answered next.

What is a Rate Limiting?
Before delving any further, let’s know the simple rate limiting definition that refers to putting a cap on traffic exchange and API usage to ensure that the system is not overloaded. If that’s not enforced, it will lead to imbalanced API or network usage as few users will overflow the system, make it down, and prevent other users from utilizing them.
In general, rate limiting is enforced to optimize the performance of a system resource and ensure equal service distributions. In its absence, it will lead to hackers/threat actors to over-consume the resources and put away the legitimate users.
Example: Think of a situation when a user forgets its password, enters the wrong one, and is then denied for login. Most of the websites/applications use rate-limiting in their login process and will block the user if 3 or 4 wrong login attempts are made.
How does Rate Limiting Work?
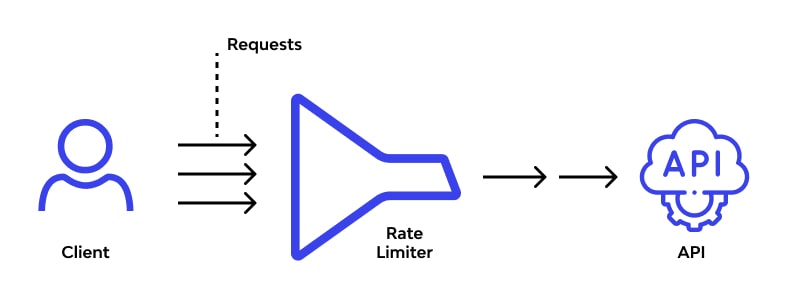
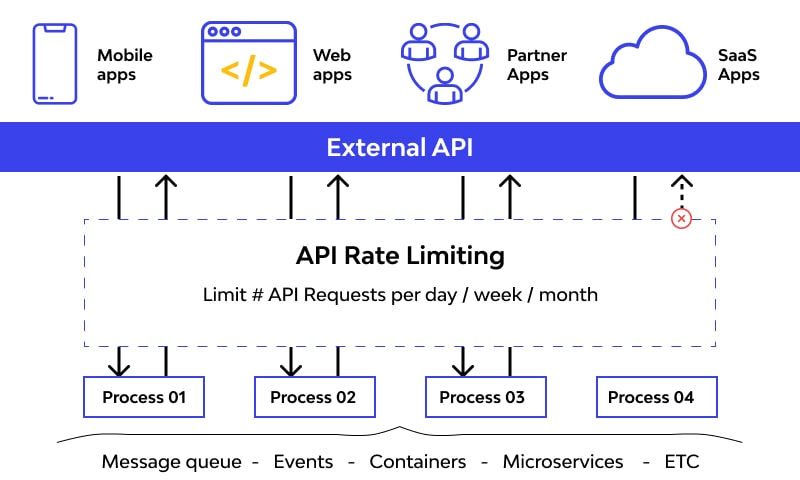
The very basic thing to understand here is the fact that rate limiting is active and operates inside an application in place of the web server. The main idea is based on tracking the IP address that made the API requests and determining the time gap between two subsequent requests.
For those who don’t know what an IP address is, it’s the unique code given to each internet connection.
With an IP address, it’s easy to figure out who, when, and how an API request is made. When rate limiting is active, the solution keeps track of total requests made and time between two requests, made from a single IP address. If there are too many and too frequent requests are made, the tool will impose pre-defined limitations on the said IP address.
A typical error message will be forwarded to the user, having a limited IP address. Just like we have traffic police in real-life that keep track of over-speeding and impose penalties on those who are the culprit, the virtual world has rate limiting. It is a precautionary measure that could save severe accidents or scams.
Rate Limits Types
As organizational needs differ from each other, it’s not wise to have a single strategy for rate limiting in place. So, you may apply it on several basis, such as:
- User
When a system is capable of spotting the user and its API consumption, it can restrict the API request made over a specific period.
For instance, the system can permit the end-user to make only 10 API requests per minute and won’t permit the 11th request made. This is the easiest way to ensure there is fair rate limiting API usage amongst all the end-users.
- Server
API-based services tend to be distributed enabling one user request to be serviced only by one server out of many at-work In such a distributed ecosystem, rate-limiting implementation will lead to effective load-sharing between the used servers.
Each server will have a limit on handling the user request ensuring all the servers are used and no one is overburdened or remains idle. When the user request exceeds the imposed limitation on a server, the request will be auto-forwarded to the next server in the system. This plays a crucial role in limiting the DDoS attack incidences on the servers.
- Geographic
It is concerned to ensure effective utilization of servers spread across the world. In API-based services, user issue requests are handled by the server, located at the nearest location to the end-user. This can lead to uneven server utilization.
With geography-based rate-limiting, an organization can ensure that distant servers also handle the requests so that immediate remedy is offered. One can make this type of rate-limiting time-based. For instance, organizations can set rules for request forwarding to the distant server after a certain period.
What is Rate Limiting used for?
As explained previously in this article, rate limiting is a preventing and defensive approach ensuring that system/networks are not overburdened and is maintaining optimized performance. This holds great importance in the case of shared services and many users access/consume them a single time. Crucial for both the client and server-side resources, rate-limiting is used for many purposes.
- To avoid resource overconsumption
With rate limiting, one can improve the API service availability as resources are not starved. It’s a fact that the majority of DoS attacks, impacting the large systems, are by chance as there are some hidden software and configuration errors in any system part.
Resource starvation, caused by unplanned DoS, is also known as friendly DoS and can be stopped by rate limiting, applied with safety warning margins.
Margins are important to deal with load lag. In absence of rate-limiting, a scalable API is most likely to make huge calls to the API database that leads to resource overconsumption.
- For effective policy and quotas management
The ideal service is one that delivers service equally to everyone, without any discrimination and a rate-limiting strategy helps organizations to make it happen. With rate limiting, per-user service consumption is monitored and optimized. Quota caps are enforced so that every single user can use service resources uniformly.
- For intelligent flow control
In case there are complex linked systems, handling huge data and messages, are in place, information flow can be too tedious to handle. However, one can’t get rid of this responsibility.
With rate limiting, controlling data flow is possible as it will allow seamless merge of multiple streams into a single device. Also, it leads to uniform workflow distribution between workers as data won’t be accessible by a single end-user.
- To keep the cost under control
Rate limiting, other than performance utilization, is useful in cost-optimization as well as it empowers a resource auto-scale without investing any further. It can also be used for SaaS solutions and offer per-customer service delivery.
Rate Limiting Methods
- Fixed window
It limits API requests except for a certain time period. For instance, a server, with this strategy deployed, will accept requests only for the allowed time window.
Suppose, the administrator has set the window as 10:00 AM to 10:30 AM, with 100 requests per second. The server will only follow this rule. The method is applicable on both the server and user levels. However, at each level, it has different meanings.
For instance, when it’s implemented on a user level, one user can make 100 requests, within that time limit. When this is implemented on server-level, one server will accept 100 requests per second, whether these requests are made by one user or many.
This method is very easy-to-use and won’t lead to new request starvation. However, there is one major drawback of this method as well and it can cause a request rush when the time window starts.
- Sliding Window
This method is also time-based and is easy to use. It’s a fixed window method, minus the starvation issue as it begins the time window once any new user -request is made. Also, it’s free from the starvation issue, which is the case with a leaky bucket.
- Token bucket
It adopts progressive usage budget and uses tokens to display the balance. It features a high-end technique ensuring that all the incoming requests should correspond to a 1:1 request ratio. At the same rate, tokens are added to the token bucket.
When a service request is generated, the corresponding service tries to make a successful token withdrawal attempt so that the request is fulfilled. Empty bucket or no tokens signifies that the request limit is reached, so the service is experiencing backpressure.
The simplest example of this method is observed in the GraphQL service wherein a single request will lead to various results that will be combined to form a result. Each of the formed results will feature a token to keep track of the capacity.
- Leaky Bucket
This is not a time-based method and features a fixed-length queue, independent of time. As we all know, the web server handles/caters to the service requests on the ‘first-come, first server approach.
The request, which is made earlier, will stand first in the queue,next ones will follow it in the queue. The length of this queue is fixed. No more requests are considered when the queue reaches the predetermined length.
This rate-limiting approach is easy to follow and ensures that the server is receiving API requests constantly. As requests will be forwarded to the server one by one, there won’t be any request outburst. However, it’s not flawless. As the queue maintained is static, starvation has a higher chance of occurrence. The new request could remain unattended till eternity.
The Utilities of Rate Limiting
On being used diligently, rate limiting can be very useful to prevent certain attacks and dangers.
- DDoS
DDoS attack is performed by overflowing the system with unexpected API requests. It sometimes even trouble the legit users from accessing the system under attack. As rate limiting can control requests’ frequency completely, it can stop DDoS (Distributed Denial of Service).
- Brute Force Attack
It also involves sending endless AP requests in hope that at least one will be accepted at the end of the day. Mostly, hackers use automation to send innumerable requests. Limiting the request count can handle it well and notify the unfamiliar behavior to your cybersecurity experts in time.
What is Rate Limiting in API?
API doesn't need an introduction as it’s the backbone of an application and is crucial for client-server communication. Whenever a connection request is made, API has to respond to it API owner has to bear the API compute time expense.
Here, the compute time is referring to the server-deployed resources essential for code execution and generating an API request-response. It certainly comes with a cost and its effective utilization is crucial to ensure that every API user has the same experience.
This is where API rate limiting comes into play. In this context, we call it API limiting.If you work with APIs and API security, it is something they must learn about.
This method can be used to keep API dangers at bay. It is the practice to optimize and limit the incoming traffic to the API from a single IP address. It ensures that not a single API user overconsumes API and API accessibility is uniform. It makes the API available to everyone within the limit.
Other than keeping the API secured from DDoS and Brute Force attacks, rate-limiting API is very useful to scale the APIs. In case an API becomes hugely popular, API limiting practice will help you control the traffic, prevent operational failure, and even usage amongst the end-users.
A few common ways to do API limiting are -
- In the hard stop method, API users will get an error message when the API request limit is reached and a request is still made.
- Soft stop won’t stop the system from receiving requests but put these requests to wait for a certain interval of time. In this duration, API providers can pursue API users to pay for the extra API requests or upgrade a package.
- The other method, Throttled stop, refers to slowing down the response time process once the limit is exceeded.
read more in OWASP API4 - Lack of Resources and Rate Limiting
API Throttling Vs Rate Limiting
You think these are almost the same? Well, no. There are differences.
Let’s talk about each of them one by one.
Rate limiting implicates total request count by time or by queue length criteria. Any request, made after exceeding the limit, will be auto- rejected or declined. One is allowed to configure various limits with time windows having limits of milliseconds to years.
Imitations are imposed in API throttling but in different manners. It targets how the request is being processed. Here, requests that have exceeded the limits will be queued. If processing can be done after certain attempts, then API will reject all further requests.
One is allowed to configure the retry delay and several retries. It’s something the server imposes and clients have to follow. API throttling exists with certain other policies like Retries and Exponential Backoff.
Both these practices impose limitations on requests and resources. Before one tries to understand ‘how to implement API rate limiting?’, it’s crucial to find out whether or not there is an SLA-based policy in place. In case, there is no SLA-based policy, limits configuration and policy application happen simultaneously.
Wallarm Solutions to Empower Rate Limiting
Your organization needs to handle unauthorized requests carefully and Rate limiting can help in it. When applied diligently, it can be proved a game-changer in API security. However, this alone is not enough to make things more secure than ever.
End-to-end security of API and other resources demands a more detailed defensive approach combining multiple other API security measures that Wallarm offers. Here is how Wallarm strengthens the defensive measures of an organization.
Capable of protecting all sorts of APIs and serverless resources, the Wallarm Cloud WAF is an inventive security technique that can be paired with rate limiting and improve the end protection. The WAF is fully automated and is very easy to use. A simple DNS setting change will lead to all-around protection.
As the WAF meets PCI and SOC2 compliances, it’s worthy of your trust. It features best-of-breed detection techniques like zero RegExps, lib detection, and bypass resistance to provide compressive protection. In case of any difficulties, there is a highly responsive analyst team to guide and fix the issues.
With Wallarm, there is a fully -integrated API threat prevention is a place that features API protection, automated incident response, and API discovery. With this all-inclusive API threat prevention, it’s very hard for any vulnerabilities to reach your APIs and exploit them. The best part about this approach can handle all sorts of leading APIs, serverless resources, microservices, and web applications.
Also, it’s independent of the digitization ecosystem used. Resources, deployed in any cloud-enabled environment, can be protected. It features a highly intelligent API call parsing feature supporting WebSocket, XML, JSON, and graphic. When such defensive and inventive security approaches are at place, the working rate-limiting policy becomes more active and powerful.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")
.png "AWS with Wallarm")