Pseudonymization
It is crucial to take care of the safety of your sensitive and mission-critical data in today’s era. And for this, you can try data pseudonymization, a methodology to replace your precious information with artificial identities. Stay tuned to learn more about this data theft prevention measure that leading security-conscious organizations are adopting.

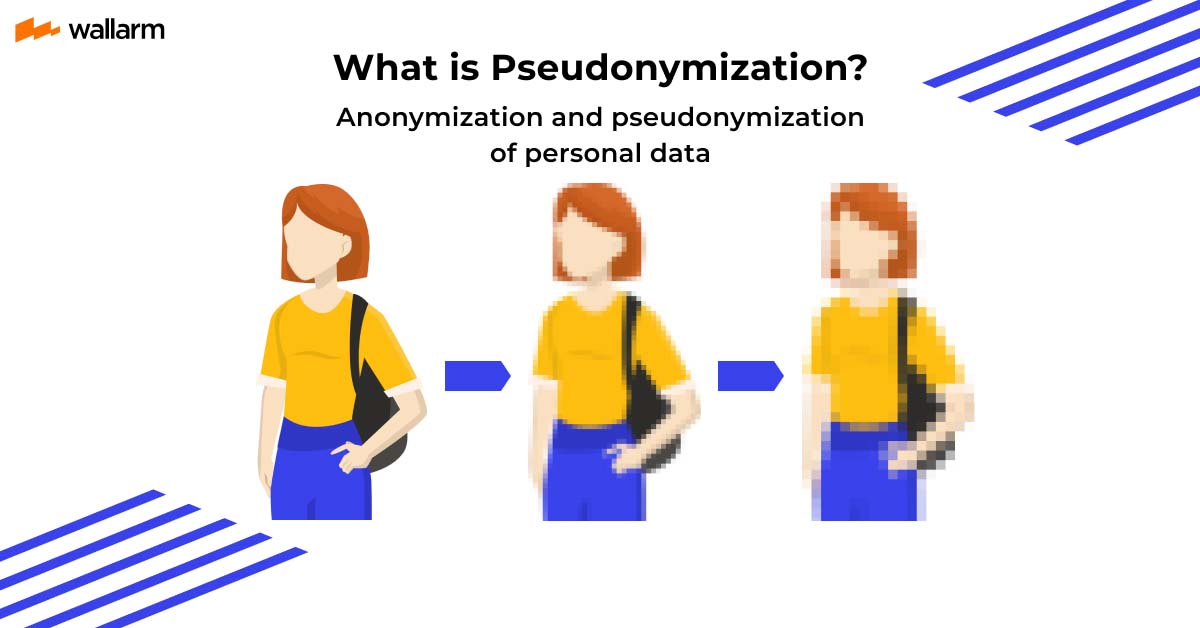
Pseudonymization Definition
It’s the technique that involves replacing key identifiers from the data with something more secure.
In general, those easy-to-guess identifiers are swapped with distinctive placeholder identifiers. These values are complex enough to elevate the data’s security.
The method is mostly used in combination with various other cybersecurity measures like encryption to harden data safety and user data privacy.
What Is a Pseudonym?
The literal meaning of "pseudonym" is being fake or hiding true identity. The concept does the same by switching the identifiable data markers with secretive values. These values are not shared or accessed over public platforms and tend to provide better privacy to their adopter.
Pseudonymization Vs. Anonymization
The former differs heavily from the latter concept. Anonymity makes data fully secretive and anonymous. The data becomes non-identifiable, and the action cannot be undone in this scenario.
On the other hand, Pseudonymization can be reversed and doesn’t provide full anonymity. It’s a more practical way to protect crucial data as the vital data is not completely stripped away.

Pseudonymization - How Does it Work?
The functionality of this concept is not complex. In fact, we all use pseudonymization in one or many ways in our day-to-day functions. However, how we use this concept in normal life and on professional fronts are entirely different processes.
Example:
Suppose John needs to open an account in a leading beauty store and has to provide details like names and email addresses to complete the sign-up process.
While John will enter its name as John, the streaming service will store his name as User_123 or so on to maintain anonymity.
Such services often maintain two databases. One database stored the pseudo names of all the users while the other database stores what services or facilities those users are availing.
For example, Database 1 displays the pseudo names of all the users while Database 2 displays which all services users are availing.
To get details about which user is using which service, access to both databases is required, which is not easy. Hence, the offered data security and privacy are better than what’s there with generic databases. To heighten security, many apply encryption to the databases.
Techniques of Pseudonymization
To cater to diverse needs, multiple versions of pseudonymization are there. Each technique has its pros and cons, and you need to learn about both these aspects before you get started.
With hashing, security experts use mathematical functions to create a unique value using the strings of text. This methodology ensures that the newly created value is not reversed and the original value is retrieved. This is mostly used in email addresses.
- Blurring
Data blurring or data masking is the process that involves replacing mission-critical data with something outdated but realistic. This is mainly used when data is shared amongst individuals of the same organization.
- Bucketing
Lastly, we have bucketing to recommend. This is a fairly common process of reducing the significance of a specific attribute so that it seems less important. This technique is mainly used on data where age details are mentioned. For instance, if a user is 45 years old then bucketing technique will define it as 40-45 instead of a specified age.
Pseudonymization vs Tokenization – What Are The Differences?
First, understand that both techniques are used to protect sensitive information but in a different way.
As mentioned above, pseudonymization involves substituting recognizing information with a pseudonym or alias so that its identification is tough. Data that is subject to data privacy regulations, such as medical records or financial data, is mostly protected by this technique. This is a reversible process and is a more practical approach.
Tokenization, on the other hand, is the process of replacing sensitive data with a non-sensitive equivalent, called a token that is erratically generated character strings with no value and meaning when used outside the defined context. It is irreversible and is used to protect payment card data in e-commerce transactions.
Does GDPR Require Pseudonymization?
GDPR, or General Data Protection Regulation, is a globally acclaimed data privacy regulation implemented by the European Union. It instructs organizations on how they should collect and protect the personal data of their users.
GDPR encourages organizations to use pseudonymization and anonymity for elevated data protection. As per the pseudonymization GDPR, pseudonymization must be adopted. Below mentioned articles of GDPR clearly mention pseudonymization and encourage organizations to adopt this practice.
- Article 6 (4) (e) of GDPR allows organizations to process personal/sensitive data for purposes like business analysis, profiling, data outsourcing, and so on should be well protected for future usage.
- According to Article 11 (2), a Data Controller is expected to take care of accessing, erasing, or porting the data of individuals. Hence, pseudonymization is a must-have practice.
- Article 25(1) of GDPR gives huge importance to pseudonymization and recommends it to be used as a default data protection method.
- In Article 32(1), pseudonymization is explained as the key measure to safeguard personal user data and confirm that it remains safe.
- Article 34 (1) of GDPR requires the use of pseudonymization to make sure that data breach and data leak incidences are as less as possible because the technique ensures that the key information remains unidentifiable.
- Article 40 (2) (d) is all about Codes of Conduct, and it also mentions pseudonymization.
- Lastly, we have Article 89 (1) of GDPR, which explains the use of pseudonymization to protect user data for various workflows.
In a nutshell, GDPR is in favor of pseudonymization and keeps it a priority to protect personal/identity-related data.
Concluding Words
Organizations dealing with sensitive personal data need to make sure that the collected data remains safe from generation to disposal. Any leniency in data storage or usage can lead to endless hassles.
Pseudonymization is a practical approach to keep identifiable data a secret and reduce the odds of threats and attacks. This practical approach is easy-to-use and is applicable to all the leading data types.
FAQ
References
Pseudonymization - GitHub Topics
Firewalls and Security Protocols Alone Cannot Keep Hackers Out - www.infosecurity-magazine.com
What Is Minification? - Wallarm
Subscribe for the latest news

.png "AWS with Wallarm")