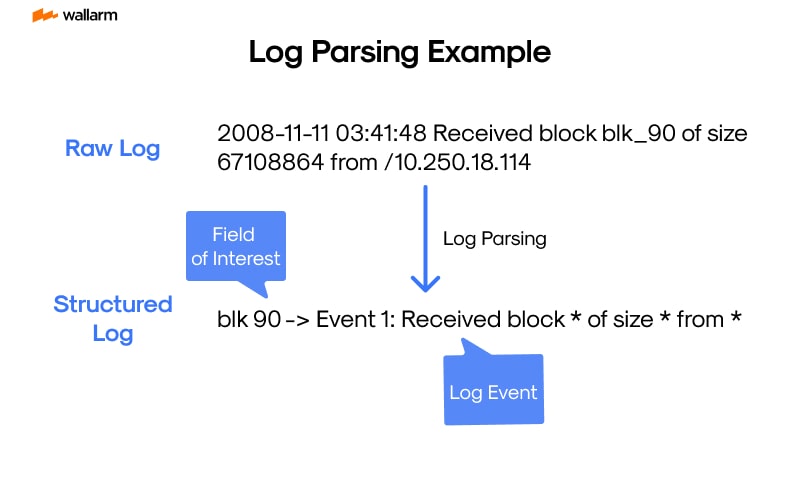
Log Parsing
In the heart of system management and cybersecurity, rests a key process named log deciphering. Such a process focuses on dissecting and comprehending log records. These logs are produced by a variety of entities, such as servers, network gadgets, and software programs. They churn out a trove of data, for instance, system transactions, user engagement, and possible cybersecurity risks. Nonetheless, comprehending this data could pose a challenge due to its unstructured nature, thereby emphasizing the significance of log deciphering.


Unlocking the Log Deciphering Code
Unraveling the mystery of log depiction echoes the deciphering of an intricate cipher. The procedure implies splitting log records into smaller, easier chunks and decoding them to pull out purposeful data. This decoding step is the key to comprehending system operations, identifying prospective cybersecurity risks, and resolving any issues.
Log records are typically amassed in text mode, where each log record adheres to a detailed form. This structure can differ based on the source of the log record - whether it is a system or an application. The log record might deliver information including, but not limited to, the occurrence time, event kind, user involved, and pertinent particulars.
Log Deciphering: Not Just a Need but a Necessity
Visualize hunting for a minute detail in an overwhelming heap of unsorted documents. The Herculean task of sorting and comprehending these documents would almost be impracticable without a system. An evidently similar challenge is encountered by IT system supervisors and cybersecurity experts dealing with unrefined log data.
The role of log deciphering comes into play here. By disentangling and decoding log records, it enables distilling specific, significant details from the vast universe of log file data. This freshly sifted information can then be harnessed for functions such as system scrutiny, troubleshooting, and security assessment.
Log Deciphering: A Deeper Insight
To shed more light on log deciphering, consider a scenario where an IT system supervisor wishes to pinpoint all unsuccessful login endeavors on a server. The server's log records encapsulate details of every login endeavor, victorious and failed alike. However, the task of identifying the unsuccessful ones is daunting due to the presence of numerous other records.
This obstacle can be tackled by parsing the log records. This operation could involve recognizing the log records corresponding to login endeavors, distinguishing successful ones from the failed, and extracting critical aspects like the attempt's timestamp, the user in question, and the cause of failure.
Thus, log deciphering remodels unrefined log data into an organized framework that can be easily comprehended and scrutinized. It serves as a pivotal instrument for IT system supervisors and cybersecurity specialists, facilitating system behavior vigilance, issue detection, and timely threat responses.
The Essentiality of Log Parsing in IT Security
The sphere of internet safety stresses the essentiality of dissecting audit trails, or logs. Inspecting these raw logs can decode invaluable information used for studying and countering cyber threats. Let's deep dive into the essence and benefits of log dissection and the perils encountered when it's dismissed.
Log Dissection: A Pivotal Role in Internet Protection
Log dissection refers to the extraction of critical insights from raw audit trails. These trails, generated by a myriad of systems and apps, host an array of information yielding helpful knowledge about operational systems, user behavior, and lurking security threats.
In digital safety, log dissection resembles a system's heartbeat. Analogous to a doctor who assesses a patient's well-being by checking their pulse rate, digital safety professionals use log dissection to determine the fortification and wellness of a system. It’s indispensable in identifying anomalies, predicting potential dangers, and examining security breaches.
Perks Associated with Utilizing Log Dissection in Internet Protection
- Spotting Hazards: Log dissection bolsters the real-time capture of internet dangers. Interpreting audit trails allows internet protection experts to identify suspicious activities, initiating an immediate reaction to decrease probable hazards.
- Examining Incidents: During security breaches, log dissection can impart essential details on the source and the implications. It aids in tracing the initiation point of the attack, the compromised systems, and the degree of inflicted damage.
- Aligning with Compliance: Various statutory mandates require organizations to maintain and examine audit trail data. Log dissection simplifies these mandates' fulfillment, offering an organized method to scrutinize and tabulate audit trail data.
- Boosting System Efficacy: By scrutinizing audit trails, businesses can detect system performance obstacles, subsequently optimizing their workflows. This leads to enhanced system efficiency and productivity.
Dangers Associated with Neglecting Log Dissection
Neglecting log dissection in internet protection can expose a business to various threats, such as:
- Failure to spot Hazards: In the absence of log dissection, threats may slip by unnoticed, increasing the risk of data exposure and system penetrations.
- Delayed Incident Management: Without log dissection, incident responses can be sluggish and ineffectual. Lacking the data gathered from logs, understanding an incident cause and implementing a suitable action becomes challenging.
- Compliance Violation: As mentioned earlier, preserving and examining audit trails are a requirement by numerous regulations. Neglecting this could lead to compliance violations, imposing potential fines, and penalties.
- System Inefficiency: With the absence of log dissection, system performance issues may go unobserved, leading to decreased productivity and potential system failures.
In summary, log dissection is vital to internet protection. It provides crucial insights about operational systems, improves hazard detection and security incident examination, whilst also supporting organizations to align with regulatory standards. Ignoring log dissection could leave a company exposed to severe threats, thus emphasizing the importance of log dissection in internet protection.
Understanding the Basics of Log Parsing
Primary focus lies in decoding logs, which are records of sequences of events within a computing environment. The aim of log decoding is to uncover actionable insights into activities or patterns within an operating system or a software application.
The Anatomy of a Log Entry
Understanding a log entry, akin to unraveling the secrets of a diary documenting serial operations, is key. Well-defined elements within log messages include:
- Timestamp: Corresponding to the exact occurrence of an event, it enables the mapping and interlinking of different actions across diverse logs.
- Event Origin: Signifies the software or system responsible for logging the operation. It's crucial in pinpointing the origin of any abnormality.
- Event Identifier: A unique tag that accumulates more detailed insights about the event.
- Description: Sums up the event, specifying the context, any issues faced, and actions performed subsequently.
Log Decoding Techniques
Fundamentally, log decoding involves the breaking down of logged events into their simplest constituents, a strategy termed as tokenization. A program element named a parser accomplishes this by systematically scanning the log entry and segregating diverse factors of each logged event.
When the parser discerns the recurring layout of the log entries, it slices the details into separate tokens. If an entry has the format: "[Timestamp] [Event Source] [Event ID] [Message]", the parser perceives the sections enclosed within square brackets as separate segments.
The segregation of data eases the identification of patterns, abnormalities, and tendencies. Thus, automatic logging tools supersede manual ones in user preference.
Techniques and Tools for Log Decoding
Several techniques and tools can boost the pace and productivity of log decoding. Some notable ones include:
- Regex: A potent method used for detecting and modifying text. Regex searches for patterns within logs and extracts critical information.
- Logstash: A widely used open-source tool for decoding logs. Captures data from diversified sources, edits it, and forwards it to a central point, like Elasticsearch.
- Python: Popular for its adaptability and repositories like Pandas and PyParsing, it's the preferred language for log decoding tasks.
Practical Implementations of Log Decoding
Let's consider a simplistic log entry: 2021-01-01 12:00:00 INFO Application started.
In such a situation, a regex powered parser could employ the pattern: \[(.*?)\] \[(.*?)\] \[(.*?)\] \[(.*?)\].
The pattern instructs the parser to look for four sets of characters enclosed in square brackets. The unit "(.*?)" in the pattern operates as a wildcard, catching any character sequence.
Upon the implementation of this pattern, the logged event gets compartmentalized into:
2021-01-01 12:00:00INFOApplicationstarted
Each token infers specific insights about the logged event.
In conclusion, log decoding is an essential aspect of IT management and cybersecurity. Simplifying logs into more basic components enhances visibility, amplifies debugging efficiency, and accelerates in-depth system analysis.
Advancement in Log Parsing Techniques
In the data protection sector, the methods of interprepting audit trail information have notably transformed over time. This change is spurred by the escalation of intricacy and quantity of audit trail datasets, along with the burgeoning necessity for better ways to scrutinize and comprehend this information.
The Progression of Audit Trail Interpreting Methods
During the inception years of audit trail interpretation, procedures were quite straightforward and completely manual. Data protection experts would painstakingly analyze audit trail files, dissect them line by line, scanning for oddities or specific sequences. However, this method was labor-intensive, prone to mistakes and didn't scale well with increasing sizes of audit trail data.
Progress in technology soon brought changes to these methods. The arrival of scripting languages such as Perl and Python made it feasible to mechanize audit trail interpretation. These languages offered potent tools for textual data manipulation, like regular expressions that simplified the task of identifying sequences in audit trail data.
By the mid-2000s, big data tools such as Hadoop and Spark catalyzed a new age in audit trail interpretation. Such tools facilitated processing and examination of extensive audit records in a synchronized manner, drastically slashing the time taken to interpret logs.
Present day sophisticated methods of interpreting audit trails utilize machine learning and artificial intelligence to autodetect irregularities and sequences in audit trail data. These tactics can adapt based on past records and forecast potential data, thereby placing them as highly effective tools for preemptive data security.
Contrast of Audit Trail Interpreting Methods
Impact of Machine Learning in Audit Trail Reading
Machine learning has brought a seismic shift in the audit trail interpretation field. Training a machine learning model with past audit trail records allows automatic detection of irregularities and sequences in newer records. This comes in handy for tracking down security breaches that could pass unnoticed.
Here's a practical example of how a machine learning model could be employed for audit trail interpretation:
In this instance, an Isolation Forest model is schooled with past audit trail records. Later, this model is utilized to find anomalies in new audit trail data. The contamination parameter is used to specify the proportion of anomalies in the data, which can be recalibrated depending on the specific circumstances.
Upcoming Scenario of Audit Trail Interpretation
Looking forward, it's visible that the sector of audit trail interpretation will remain on an upward trajectory. Future technologies such as quantum computing and brain-inspired computing foretell even more progressive methods of interpreting audit trails. These technologies offer to provide unmatched processing capacity and swiftness, potentially overhauling the manner of audit trail examination
In summary, the enhancement in audit trail interpretation methods has been spurred by the escalating complexity and volume of audit trail data, accompanied by the growing necessity for efficient and effective ways to scrutinize and comprehend this data. As we step into the future, we can anticipate continuously innovative and potent methods of reading audit trails.
Log Parsing: The Crafting Process Explained
Creating an intentional strategy for dissecting log files involves a mix of keen insight, detailed data analysis, and targeted information retrieval. This discussion will break down this intricate operational procedure, presenting a step-by-step guide to composing a profitable system for log file analysis.
Deciphering The Log File Blueprint
Embarking on the journey of log file analysis requires you to build familiarity with the blueprint of your data. Log files come in an array of formats, tailored to the individual system or app that brings them to life. They might exist as straightforward text files or embrace more intricate designs like JSON or XML.
A classic log entry may offer information like when the event happened, the birthplace of the event, its nature, and a narrative outlining the event. Grasping the blueprint of your log files facilitates the identification of crucial information pieces relevant for extraction.
Designing the Analysis Directives
Once you're familiar with your log file blueprint, your next move is to develop your parsing rules. These directives provide your log data analysis tool with a framework, guiding it on how to digest the data. For example, you can have a rule that directs the analysis to fetch the timestamp and nature of each event from every entry.
The parsing directives you create will align with your specific project requisites. If your goal is to uncover potential security threats, your focus might center on fetching data allied to failed login ventures or dubious network operations.
Bringing the Analysis Tool to Life
With your parsing directives in place, you can breathe life into your analysis mechanism. This process involves crafting a script or software that audits the log files, enforces the parsing directives, and mines the data that matters.
Here's a basic example of a log parsing script penned in Python:
This script employs a regular expression to compare the log entries' pattern and mine the timestamp, event group, and content.
Validating and Polishing the Analysis Tool
Following your analysis tool sketch, you need a meticulous validation routine to ascertain that it is extracting the appropriate data. This might demand running the analysis on a slice of your log files and confirming the output manually.
If the tool fails to hit expected outcomes, you have to fine-tune the parsing directives or make adjustments to your script. This task often calls for a recurring set of tests and corrections until you get it right.
Operationalizing the Analysis Procedure
Once satisfied with the tool's performance, the last stretch is to transform the parsing procedure into an operational routine. You can establish a regular task that runs the analysis tool at specified intervals or set up a trigger that activates whenever a fresh log file appears.
Operationalizing this procedure guarantees that your logs are in constant review, enabling swift extraction of any vital information.
In short, a sound log file analysis strategy is a woven product of understanding your log files' blueprint, tailoring analysis directives, developing the analysis tool, validating its performance, and ultimately operationalizing the procedure. By adhering to these methods, you are set to dissect your logs effectively and mine the invaluable info encapsulated within their confines.
Unpacking the Elements of Log Files
Log records serve as invaluable information repositories, harbouring a comprehensive chronicle of transpiring activities within endpoints, such as an operating system, an application, a server or alternative types of devices. Their primary utility surfaces in the realm of log dissection. To dissect logs adeptly, comprehension of the diverse constituents in a log file takes precedence.
Constituents of a Log File
An archetypal log file houses several constituents, each bestowed with a distinctive functionality. Here, we demystify the principal constituents:
- Temporal Marker: This is the specific instant of time when the incidence was recorded. This element serves paramountly in pinpointing when certain occurrences transpired and in interlinking incidences across an array of log files.
- Log Severity: This displays the intensity of the incident. Predominantly encountered log levels encompass INFO (informational), WARN (precautionary), ERROR, and FATAL.
- Origin: This is the middleware, service, or apparatus that spawned the log. Its relevance lies in pinpointing the location of an event.
- Incidence ID: This is a distinct identifier attributable to the event. It finds application in sourcing extra details regarding the occurrence from the software's reference manual.
- Narration: This manifests as an interpretation of the event comprehensible by humans. It frequently incorporates specific facets about the event, such as the variable values or the system status during the event.
- Thread ID: In systems with multiple threads, the thread ID comes in handy to identify the thread engaged during the occurrence of the event.
- User ID: Provided the event corresponds to a distinct user action, the log might contain a user ID.
- Session Marker: For events associated with a user's session, the log might contain a session marker.
Log File Conformations
Log files conform to an assortment of formats, each bearing its unique element set and structural arrangement. Predominant formats constitute:
- Unformatted Text: Here, each event is recorded as a text sentence. The elements are typically spaced by blanks or tab spaces.
- JSON: Herein, each event is recorded as a JSON object, enabling easy log parsing with standard JSON toolkits.
- XML: Analogous to JSON, each event is recorded as an XML constituent. Although XML logs are easily parsed using standard XML toolkits, they tend to be more verbose compared to JSON logs.
- Binary: Certain systems record events efficiently in a binary conformation. Binary logs are less bulky, quicker to inscribe and read than text logs, but call for specialized toolkits for parsing.
- Syslog: This is the standard structure for system logs in systems similar to Unix. It encompasses a priority code, a timestamp, a hostname, a process name, a process ID, and a message.
Log File Illustration
Here's an exemplification of a log entry in an unformatted text conformation:
In this illustrative example, the temporal marker is 2021-07-01 12:34:56,789, the log severity is INFO, the origin is com.example.MyApp, whilst the narration reads User 'john' logged in.
Being well-versed with the constituents of log files is the maiden stride towards adept log dissection. In subsequent chapters, we'll delve into the methodologies and apparatuses for parsing these constituents and deriving invaluable intelligence from your logs.
How to Parse Logs: A Step-by-step Guide
Log interpretation is a critical capability for technology professionals, particularly for those operating in the realms of system administration, cyber defense, and data scrutiny. It's the process of deriving significant insights from the log records produced by systems, software, and networking hardware. This section offers a detailed, lucid, and straightforward walkthrough on deciphering log data.
Decoding the Structure of Log Records
Before beginning with the interpreting process, you should familiarize yourself with the structure and what the log records encompass. Log records exhibit diverse formats, which largely depend on the software or system generating them. Nevertheless, the majority of log records embed comparable information, such as time markers, event descriptors, originating and recipient IP addresses, and error indicators.
Take a glance at this standard log entry:
The elements of this log entry are:
- Time Marker:
2021-09-01 12:34:56 - Log Tier:
INFO - Originating IP Address:
192.168.1.1 - Request:
GET /index.html - Status Indicator:
200 - Time Taken for Response:
0.012
Organizing the Log Records
Before you proceed with the deciphering process, it might be necessary to tidy up the log records. This step includes eliminating extraneous lines, like commentary and vacant lines. Certain instances may require you to standardize the log records, translating all text into a specific format like lowercase.
Here's a sample of log tidying using a rudimentary Python script:
Interpreting the Log Records
With an organized log ready, you can kick-start the interpretation process. The most elementary method to decipher a log record is by using Python’s split()function; it dissects a string into a collection of substrings based on a separator.
Here’s an illustration of log interpretation using the split() function:
Examining the Log Records
Upon interpreting the log records, you can proceed towards evaluating the gathered data to discern patterns, tendencies, and inconsistencies. This process involves computing metrics, like requests per minute, average time for response, and the proportion of error responses.
Here's a concept of how to assess a log using Python:
In this methodical guide, we’ve examined the rudiments of log interpretation, including the comprehension of log structure, organizing log records, interpreting, and finally, assessing them. Nevertheless, log interpretation can turn highly intricate, contingent on the log format and encompassed data. In the ensuing sections, we'll delve into more sophisticated methodologies and utilities for log interpretation.
Utilizing Command Line for Log Parsing
Inarguably, the Direct User Interface — otherwise referred to as the Terminal or Shell Prompt — acts as a powerful utility that simplifies the interpretation of log-derived data. This interface presents itself as a direct conduit to the operating system, granting users the flexibility to run an array of commands and scripts to automate and manage distinct tasks. Considering log data inspection, the command line becomes a viable choice for sorting, arranging, and studying data, asserting itself as an invaluable resource for cybersecurity specialists.
Unlocking Log Data Interpretation through the Command Line
Primarily, the methodology of analyzing log data through the command line occurs through a collection of specific commands and instructions that seize and scrutinize data from log records. This approach can be segmented into three fundamental actions: data extraction, data modification, and data preservation.
- Data Extraction: This initial maneuver includes an in-depth study of the log file, recovering pertinent details with commands like 'cat', 'less', 'more', and 'tail'. These instructions shine in revealing the underlying content of the file, while 'grep' excels in detecting particular elements within a file.
- Data Modification: This task focuses on tweaking the harvested data to augment understanding. Instructions such as 'awk', 'sed', and 'cut' are proficient in refining and transforming data, while 'sort' and 'uniq' capably classify and eliminate repetitive data.
- Data Preservation: The consequent task involves storing the revised data in an appropriate format for simpler future scrutiny. The 'echo' and 'printf' commands enhance data presentation, and '>>' and '>' direct the output to a specific document.
Key Tools in the Command Line for Log Dissection
There exist various command line tools vital for tearing down logs, including:
- 'grep': An adaptable utility that pinpoints distinct features within a document. It assists in sifting log data based upon certain standards, such as timestamps, IP addresses, or alert types.
- 'awk': A tool specifically designed for versatile data manipulation. Useful in pulling specific data from a log record, compiling statistics, and executing extensive modifications.
- 'sed': A tailored editor useful in modifying and filtering data. It seamlessly substitutes specific strings, eliminating lines, and accomplishes additional amendments.
- 'cut': An adept tool in isolating predefined fields from a line of text. It helps in sectioning off data particles from the log record.
- 'sort' and 'uniq': Utilities that organize data and obliterate duplicates. They play a paramount role in arranging log info and identifying unique events.
A Hands-on Illustration of Basic Log Dissection
In this live example, we utilize the command line to decode a log file. Suppose we have a log file gathering data about server requests, and our concern is to ascertain the number of requests instigated by each IP address.
Here's a pathway to follow:
This command renders a list of IP addresses adjacent to the number of requests each address instigated, sequencing the data in descending order.
Command Line Log Dissection: Perks and Snags
The command line presents several merits for log dissection. It is quick, adaptable, and robust, enabling users to swiftly sieve and scrutinize an abundance of log data. It also has task scheduling capabilities, indicating users can schedule analysis tasks and perform them autonomously.
Drawbacks, evidently, exist too. Firstly, becoming adept at using the command line requires substantial time and effort, necessitating users to comprehend and memorize a host of commands and syntax. Secondly, the absence of a visual user interface could potentially impede the interpretation and visualization of log dissection results.
Despite these minor setbacks, the command line remains an essential analytical instrument. With persistence and practice, cybersecurity practitioners can harness its potential and flexibility, dissect log data efficiently and glean essential insights about their systems.
The Role of Machine Learning in Log Parsing
Advancing AI Through Advanced Analytical Systems - Enhancing Log Examination Functions
The advent of advanced analytical systems in AI is generating considerable alterations across various sectors; IT security is one of them, where new techniques are being applied for log data oversight. This avant-garde method significantly improves the efficiency of handling voluminous log data.
Forging New Pathways - Advanced Analytical Systems and Their Impact on Log Examination
These state-of-the-art learning algorithms are instrumental in discerning patterns and detecting anomalies within the log data, effectively dealing with the challenges upon traditional log analysis associated with human error. This cutting-edge technology streamlines and elevates the process.
Utilizing advanced analytical systems aids in classifying log entries based on their content. This results in the easy identification of normal behavioural trends and unusual activities that might hint at cybersecurity threats. Moreover, the convergence of predictive analysis fortified by imaginative learning algorithms facilitates comprehensive use of legacy log records for forecasting future actions, thereby cultivating a proactive method to pinpoint and avoid security risks.
Solidifying Log Analysis through Advanced Analytical Systems
Positioning diverse advanced analytical models strengthens log analysis:
- Guided Learning: This technique entails educating an algorithm on a dataset with previously identified labels showing the expected outcomes, assisting the algorithm in identifying particular patterns or anomalies in the log data.
- Autonomous Learning: In this scenario, the algorithm operates on unlabeled data by finding patterns and structures independently, boosting log analysis by spotting latent threats.
- Consequence Learning: In this model, the algorithm amasses knowledge from the outcomes of different choices, leveraging this freshly gained understanding to enrich log analysis and threat detection.
Practical Case Study: Leveraging Advanced Analytical Systems for Log Examination
A corporation that churns out an extensive amount of log data from its IT infrastructure can unearth valuable insights related to its operations and potential security risks. Conventional log analysis techniques can be burdensome for IT personnel; however, the induction of advanced analytical strategies can hasten this process, escalating the company's threat detection competence.
Through guided learning, the corporation can lead the algorithm with selected log data to identify anomalies suggestive of potential threats. The educated algorithm can then examine any remaining log data, underlining possible threats and alerting IT personnel.
Additionally, by choosing autonomous learning, the corporation can identify threats that were obscured or overlooked. The algorithm independently discovers latent patterns and structures in the log data, assisting in the identification of neglected threats.
With consequence learning, the business can refine its log examination by empowering the algorithm to make educated decisions when processing and studying log data, thereby amplifying the effectiveness of their threat detection mechanisms.
Upcoming Trends: The Impact of Advanced Analytical Systems on Log Examination
The effect of these systems on log examination is predicted to escalate in the future. As IT systems continue to evolve and produce more log data, the need for efficient log analysis methods will skyrocket. The adaptability of advanced analytical systems proffers the perfect resolution by automating procedures and enhancing threat detection ability.
In gist, advanced analytical systems are an indispensable tool for interpreting huge volumes of log data, offering an improved and efficient approach for collating, processing, and scrutinizing large databases. Moreover, these analytical systems augment threat detection capabilities, allowing businesses to meticulously safeguard their IT network and safeguard data privacy.
Best Practices for Efficient Log Parsing
An effective procedure to process logs is vital to maintain robust IT security. It necessitates a precisely planned scheme to achieve the ideal outcome. Compliance with tried-and-tested methods allow IT experts to simplify the routine, bolster precision, and amp up productivity in their approach to sift through logs. This section will delve deep into the superior methods used in proficient log processing, offering an exhaustive guide.
Learning about Your Logs
The groundwork to proficient log processing hinges on comprehending your logs. Various platforms and applications produce logs in disparate styles, and comprehending these layouts is fundamental for competent processing.
- Decipher Your Log Layout: Log files can come in organized styles like JSON or XML or unorganized styles such as plain text. Knowing the structure of your logs will guide you in picking the most suitable resource and strategy for processing.
- Appreciate Log Details: Log files house massive data, incorporating timestamps, event categories, originating IP addresses, amongst others. Realizing the specifics embedded in your logs will guide you to retrieve the extremely valuable information.
- Spot Essential Data Nuggets: Not all the information in a log file holds the same significance. Spot the most relevant data nuggets crucial to your security analysis like user IDs, IP addresses, timestamps, and event categories.
Picking Appropriate Software
The selection of log processing resources can notably influence the proficiency of your log processing workflow. Diverse resources are obtainable, each possessing its own benefits and drawbacks.
- Dissect Your Requirements: Distinct resources are created for different tasks. Some resources are planned for processing extensive quantities of logs, while others are devised for handling sophisticated log formats. Scrutinise your necessities prior picking a resource.
- Assess Resource Abilities: Evaluate the abilities of distinct resources. Certain resources offer superior features such as machine learning algorithms for anomaly detection, while others offer rudimentary parsing abilities.
- Exam Resources: Before accepting a resource, examine it to confirm it matches your criteria. This can prevent wastage of time and resources on unfitting software.
Smoothening the Processing Workflow
Proficient log processing necessitates a simplified workflow. This encompasses automating tasks when viable and ensuring efforts are centred on valuable data.
- Automate When Achievable: Automation can notably boost the proficiency of your log processing workflow. Numerous resources offer automation options, saving effort and minimising the potential for human blunders.
- Concentrate on Valuable Data: Not every piece of data in a log file bears significance. By concentrating on valuable data, you can enhance the productivity of your operation.
- Utilise Regular Expressions: Regular expressions can be an efficient ally in processing logs. They allow extraction of specified information from your logs and can be applied to automate the processing workflow.
Asserting Precision
Precision is important in log processing. Parsing errors may mislead conclusions, which can risk IT security.
- Confirm Your Results: Consistently affirm your processing results. This can be done by manually reviewing a portion of your processed data or employing validation resources.
- Address Errors Professionally: Errors are inescapable in log processing. Make sure your processing method addresses them professionally, preventing crashes or yielding incorrect results.
- Stay Informed with Changes: Log formats may change over time. Staying updated helps to ensure that your processing method remains reliable and competent.
In summary, proficient log processing requires a well-planned scheme, comprehensive knowledge of your logs, the best software, simplified process, and a focus on precision. By adhering to these exceptional methods, you can enhance the productivity and effectiveness of your log processing efforts and upgrade your overall IT security, thereby maintaining a strong, secure IT infrastructure.
Challenges Associated with Parsing Large Log Files
In the context of cybersecurity, dissecting logs can help in uncovering potential vulnerabilities and aberrations. Nevertheless, the larger the log files, the more arduous the task becomes. This section explores the distinct obstacles encountered while dissecting voluminous logs and proposes feasible remedies to conquer these obstacles.
Coping with Mammoth Data
Handling humongous log files often proves to be a formidable task primarily due to the enormity of the data. In bulky systems or networks, log files have the capacity to expand to gigabytes or even terabytes rapidly. The colossal magnitude of data can easily be the downfall of routine log dissection tools and methodologies, leading to time-consuming analysis and wastage of resources.
Tangling with Data Complexity
The intricacy of data housed within log files adds a layer of complexity to the process. Often, log files encompass a hybrid of structured and unstructured data, which can be tricky to dissect and examine. This complexity is a potential source of errors during dissection, leading to undetected vulnerabilities or false alarms.
Tackling High-Speed Data Generation
In a real-time system environment, log files are constantly refreshed with new data. The velocity at which this data amasses can be a limiting factor for log dissection. Conventional dissection methodologies may fail to keep pace with this rapid data accumulation, causing a lag in vulnerability detection and mitigation.
Conquering the Obstacles
Despite the obstacles summarized, there exists an array of strategies to efficiently dissect bulky log files. One such example is leveraging distributed computing. By segmenting the dissection chore across multiple systems, it becomes feasible to manage larger data sets more efficiently.
Another viable approach involves harnessing the power of machine learning algorithms. When trained rightly, these algorithms can discern patterns within the data, thus simplifying the dissection and analysis of complex logs.
Lastly, real-time log dissection can be actualized via stream processing techniques. These methods allow continuous data analysis as it amasses, which drastically minimizes lag in vulnerability detection.
Even with these complexities, dissecting voluminous log files remains an essential exercise in cybersecurity. By grasping these complexities and executing effective strategies, efficient and successful log dissection becomes achievable thus bolstering the overall defense of the system.
Case Study: Detecting Anomalies through Log Parsing
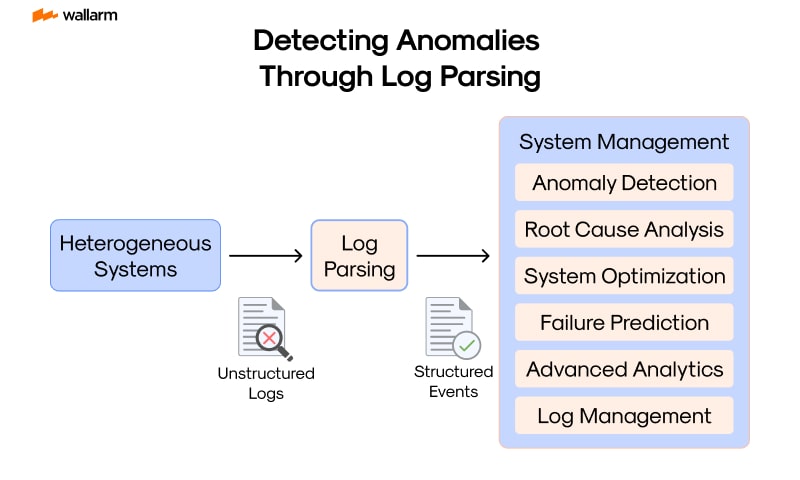
Working within the information technology (IT) security landscape, one critical method used to pinpoint irregularities that stand out from the norm is anomaly detection. These deviations often represent grave incidents, encompassing unauthorized access, fraudulent actions, or glitches in the system. One effective tool for identifying these anomalies is log parsing.
Let's consider a hypothetical situation exploring this process.
Hypothetical Entity
Imagine a thriving e-commerce enterprise that depends upon a sophisticated server network to streamline a myriad of functions on the web. Within this setting, an IT security unit is responsible for monitoring the intricate system activity, securing it against potential threats and ensuring optimal performance. Given the extensively recorded activity data generated by the servers, manual examination of this information becomes an improbable task. That is where log parsing comes in useful.
The Methodology
The stratagem set by the IT security unit was to apply a log parsing system to transform the log data review process into an automatic operation. The proposed system would dissect log entries and filter out pertinent details such as user agents, request methods, IP addresses, timestamps, and status codes. This pile of details, once processed, would then become easily analysable data to spot anomalies.
Python programming along with regular expressions were the tools of choice used to parse logs. Regular expressions identified patterns within log entries, whilst Python scripts automated and structured the parsed data.
The Parsing Sequence
The systematic approach followed during the log parsing protocol included these stages:
- Data Aggregation: Here, the unprocessed log data was sourced from the servers.
- Data Purification: The collected data underwent a scrubbing process to discard unimportant details.
- Pattern Recognition: Identifying and filtering relevant details from the log data was accomplished using regular expressions.
- Data Organization: Information derived was then organized in a format conducive to thorough analysis.
- Data Inspection: Lastly, the organized data sets were evaluated for anomalies.
Outcome of the Study
The execution of the log parsing mechanism was hailed as a success. It transformed a massive heap of log data into a more digestible format for analysis. This procedure provided the IT security personnel an efficient way to pinpoint irregularities within the network activity.
There was an instance where the system recognized an odd increase of requests from a specific IP address. This lead the team to uncover an attempted Distributed Denial of Service (DDoS) attack orchestrated by a botnet linked to the concerned IP address. Owing to the log parsing system, a potentially disastrous attack was detected and neutralized early on.
Final Thoughts
This example emphasizes the crucial function log parsing plays in anomaly detection. With the automation of log data analysis, it facilitates the IT security squad in their surveillance of network activities. Consequently, helping them to promptly spot irregularities that might be indicative of looming threats. Therefore, log parsing is an indispensable resource for those invested in IT security.
Processing and Analyzing Logs with Python
Python is noted for being an adaptable and potent coding language that has become a favored choice for log parsing. This can be attributed to the straightforwardness it provides and its resilience. Moreover, Python hosts an extensive collection of toolkits and modules that streamline the task of scanning and scrutinizing logs.
Libraries in Python Favourable for Log Parsing
Python extends a plethora of libraries specifically engineered for the purpose of log parsing. Some of the frequently leveraged ones incorporate:
- Pygtail: A tool that specializes in reading lines within a log file that have not been previously read. This suits scripts that need to be run incessantly and manage log rotation.
- Loguru: A toolkit easing the task of logging by offering an easily understandable interface along with built-in configurations.
- Logging: An inherent module present in Python designated for logging that offers a flexible framework for the purpose of transmitting log messages originating from Python applications.
- Watchdog: A toolkit that aids in the observation of directories for alterations within the log files.
- Pyparsing: An extensive parsing module which can be employed to scan log files.
Adopting Python for Log File Parsing
Adopting Python for parsing log files entails reading the file, decomposing each line into discernible segments, followed by a keen analysis of the parsed information. Here is a rider of how a log file can be parsed with the built-in logging module that Python offers:
In the given illustration, the parse() function present in the logging module is employed to parse each line of the log file. The resulting parsed information is directed to the analyze() function for an in-depth examination.
Examination of Parsed Log Data
Post parsing of the log data, it can be dissected for seeking out meaningful information. This may comprise patterning, anomaly detection or excavating specific data points. The degree of complexity for the analysis can range from rudimentary to intricate.
An instance of this would be counting the occurrences of a certain error message within a log file. Here's the method of performing this task with Python:
In the provided scenario, the analyze() function traverses through the parsed data, augmenting a counter each time it stumbles upon the mentioned error message. Post traversal, the function displays the count of the error message.
Final Thoughts
The uncomplicated nature of Python, combined with its collection of potent libraries, emphasize it as an excellent tool for log parsing. Equip yourself with the knowledge of how Python can be used for parsing and analyzing log files. IT security experts can derive beneficial insights from their log data, aiding in implementations such as system monitoring, anomaly detection, and potential threat hunting.
The Power of Regular Expressions in Log Parsing
In the tech space, parsing through log data without a tool of caliber, such as Regex or Regular Expressions, would be akin to attempting a high seas voyage without a compass. Regex is akin to a connoisseur's powerful search engine, engineered with bespoke symbols for adept pattern scrutiny. Incorporating Regex into the science of log file analysis maximizes the critical insights to be had, by tracing specific sequences in the log data.
Unpacking the Notion of Regular Expressions
How best to understand Regular Expressions? Visualize it as a reimagined language comprising alphabets and symbolic characters. This decoded language can emulate and mirror assorted data strings. For instance, a Regex model like 'a.b' could pursue data strings containing 'an A', followed by any symbol, and culminating with a 'B'. Therefore, it finds string patterns such as 'acb', 'a2b', or 'a$b'.
A cutting-edge Regex goes beyond fundamental processes to accurately pinpoint patterns, detach sections from a data chain, and substitute sectors of a data string with alternate information. When scrutinizing log data, the main goal is to sift out and extract chosen data shards from a large text domain, and Regular Expressions accomplish this task with commendable finesse.
Employing Regular Expressions in the Scrutiny of Log Files
The meticulous scrutiny of log files greatly benefits from Regex, as it aids in emphasizing discrete data sectors within the conglomerate of log data. Consider a context where a log entry chronicles a user's login activities, appearing somewhat like this:
To pluck out the username and IP from each log entry, a suitable Regex would appear like so:
This Regex model scours for text components such as 'User ', followed by one or multiple alphanumeric indicators (the username), then the exact string ' logged in from IP ', and finally, four clusters of numerals separated by periods (the IP address). The parentheses function as data lassos, securing the corresponded text units.
Thanks to Regex, extracting usernames and IPs from log entries is accelerated, making the assessment of user login activities more efficient.
Amplifying Benefits from Regular Expressions
The full-potential of Regex in log data analysis is accessible through multiple applications. A proficient Regex can engage with nearly any textual pattern, simplifying the task of drawing out a myriad of data kinds from log data.
Imagine a hypothetical log file logging web server requests. Each logged entry might mirror this:
Here we have a scenario where a GET request for '/index.html' is processed via HTTP/1.1, with the status code returned being '200', and data transmission totalling '1234' bytes. To parse the request method, file path, HTTP version, status code, and data size from all entries, construct a Regex like so:
This Regex aligns with alphanumeric symbols, a forward slash followed by alphanumeric symbols or periods, the string ' HTTP/', one digit, a period, another digit, and finally, the required volume of digits. All secured groupings are emphasized by parentheses to guarantee the fruitful extraction of matched text.
In Summary
Given the complexities of parsing log files, the sheer efficacy of Regular Expressions is undeniable, banking on their adaptable nature, precision, and versatility in extracting a plethora of data from colossal data repositories. Whether it's unmasking security infractions, observing system operations, or merely deciphering user behavior models, Regular Expressions can augment and amplify any exploration into log data analytics.
Log Parsing Tools: An In-depth Exploration
Assessing and interpreting log files are indispensable activities in the realms of computer security, system surveillance, and network investigatory work. Typically, this requires sifting out pertinent details from log records for review and analysis. Even though one might opt to manually sift through logs, the process could be lengthy and littered with mistakes, more so when big data is involved. This is why employing log parsing tools is beneficial. These utilities simplify the process, enhancing speed, correctness, and efficiency. In this excerpt, we will take a closer look at a few widely-used log parsing utilities, understand their distinct features, and discuss their relative pros and cons.
Logstash
Logstash is a complimentary, server-oriented data handling pipe that admits information from multifarious sources, alters it, and channels it to your selected "stash" (like Elasticsearch). As a component of the Elastic Stack, alongside Beats, Elasticsearch, and Kibana, it is commonly utilized for log consolidation and analysis.
Key points of Logstash include:
- Variety: Logstash permits numerous information classes and origins, such as logs, quantifications, and web applications.
- Immutability: Logstash provides over 200 plug-ins, enabling users to combine, switch, and manage various information clusters.
- Ahead in Elasticsearch and Kibana integration: This feature facilitates dynamic data depiction and analysis.
Fluentd
Fluentd reigns as an open-source data assembly platform that combines information gathering and usage for optimal understanding and application. It’s tailored for large-scale log handling, supplying the tools required for log analysis.
Focal features of Fluentd cover:
- Adaptability: Fluentd can accumulate and project data from and to an array of origins.
- Dependability: Fluentd incorporates a resiliency feature to guarantee data reliability and fortitude.
- Immutability: Fluentd includes a plug-in framework which lets users augment its capabilities.
Graylog
Graylog has positioned itself as a premier centralized log administration system engineered based on open standards for capturing, conserving, and offering real-time examination of immense volumes of machine data. Graylog aims to improve user satisfaction with its speedy and efficient analysis orientation, offering a more comprehensive approach to data admission.
Notable features of Graylog are:
- Scalability: Graylog is equipped to manage a high data volume and can be adjusted to fit your needs.
- Potent search: Graylog calls upon a robust search feature which lets you sieve and delve into your logs.
- Alerting: Graylog gives you the option to strategize alert notifications based on your logs, giving you a heads up on imminent issues.
Comparative Look at Log Parsing Tools
Each of these utilities brings its unique power, but your choice depends on your stipulated requirements and the type of data at hand. For instance, Logstash could be your ideal choice if you need a tool that caters to a wide array of data styles and has excellent coordination with Elasticsearch and Kibana. Conversely, if you prioritize an instrument with strong alert capabilities, Graylog would be the preferred choice.
In summary, log parsing tools are pivotal for accurate and efficient log analysis. They simplify the process and add valuable features like data representation, alerting, and scalability, a prerequisite in our data-oriented world.
Demystifying the Process of Log Consolidation
Melding logs is a paramount facet of log parsing, so much so that it cannot be disregarded. This indispensable process encompasses the accumulation of logs from a myriad of sources and fusing them into a single, unified repository. This practice is crucial to efficient log control and evaluation, creating one comprehensive outlook of all log info, allowing for convenient recognition of repetitions, tendencies, and irregularities.
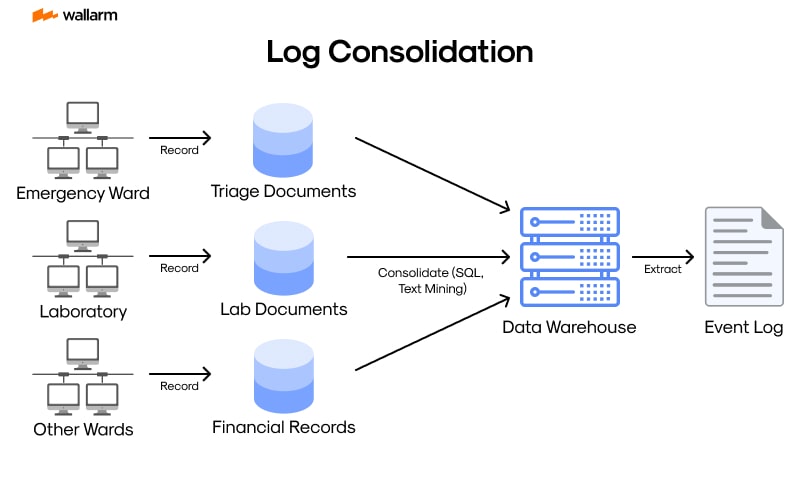
Log Melding: The Why and How
Log merging is essential due to a couple of fundamental reasons. Firstly, it declutters log management by narrowing down the locations where logs need inspection and evaluation, saving both time and resources for tech teams. Next, it gives an all-in-one snapshot of the system's operations, useful for recognizing consistent tendencies and patterns that may go under the radar otherwise. Lastly, log melding can be the key to adhering to certain regulations on maintaining and overseeing log data.
The Procedure for Log Melding
Log merging usually includes these steps:
- Accumulation: The initial phase where diverse log sources, including servers, applications, databases, and network devices, provide the logs.
- Standardizing: The logs gathered undergo normalization or conversion into a uniform design, a vital step to guarantee constancy and uncomplicate their evaluation.
- Stashing: Once standardized, these logs are stashed into a central hub, which may be a hard server, a cloud-based storage system, or a specialized log management system.
- Examination: Logs, now stored, can be studied to spot patterns, trends, and deviations, helpful for unearthing possible security threats or performance glitches.
Obstacles in Log Melding
Log merge, though beneficial, does not come without hurdles. A primary issue is managing the sheer influx of log data, especially for larger corporations with an overload of log sources.
Ensuring the logs' safety is another concern since these might carry sensitive info, calling for protection against undue intervention or tampering.
Lastly, guaranteeing the logs' holiness also poses a challenge. The logs must be kept safe from alterations or deletion, which can jeopardize their viability for assessment and regulatory compliance.
Solutions to the Hurdles
Despite these issues, there are solutions to make log merging less daunting. Using log management tools that automate the accumulation, standardization, and stashing phases can be one way. Such tools might also offer secured storage and integrity verification features.
Adopting a log retention policy is another viable solution, helping manage data overload by setting deletion or archiving benchmarks.
In summary, log melding is an obligatory component of log parsing that could declutter log management, give an all-in-one snapshot of system operations, and help adhere to compliance. The challenges could be suitably tackled with appropriate tools and regulations.
Log Parsing in Network Forensics: A Deep Dive
Decoding Digital Echoes: Dismantling Logs for Networked Forensic Study
Explorations in networked forensics utilize designated operations to shield virtual space from malicious infiltrations. A pivotal operation in this endeavor is the deconstruction of data logs, an essential technique for detecting, investigating, and blocking webborne threats. This section sheds light on the importance of undergoing log disassembly in networked forensic inquiries, the various techniques adopted, and the significant benefits it bestows.
Log Deconstruction: An Essential Gadget in Network Forensics
Networked forensic pursuits involve the monitoring and analysis of digitized traffic within a network. Such exploration facilitates the gathering of data, assembling of court-worthy proof, or tracing hidden vulnerabilities. In such contexts, dismantling logs can serve as a powerful strategy to extract pertinent details from the stream of information generated by network devices.
Devices like digital routers, virtual barricades, and server machines conventionally generate a flow of data. These details encompass the entire chronological actions within the network, from the birth of data packets to their destination, temporal activity markings, and system breakdown notifications. However, most of the time, these logs are encumbered with technical jargon and abundant, making it tricky to manually extract specific data points. This is where log dismantling enters the scenario.
Procedural Approach in Networked Forensics for Log Dismantling
In the domain of networked forensics, specialists draw upon a variety of approaches to meticulously dissect logs. These methodologies include:
- Sequence Recognition Indicators: This robust tool proves crucial in identifying patterns captured in textual logs. It proves instrumental during log deconstruction to extract clear-cut data from comprehensive entries.
- Scripted Automation Languages: Tech-savvies harness languages like Python, Perl, and Bash to perform log dismantling in a non-manual mode. These languages offer extensive libraries and functions that simplify the act of navigating and decoding log entries.
- Tailored Log Dismantling Software: A broad spectrum of dedicated utilities has been birthed purely for log dismantling. These tools come equipped with features like options for refining, searching, and graphical representation for a more comprehensible understanding of the deconstructed logs.
Elucidating the Benefits of Log Disassembly in Networked Forensics
Log disassembly brings about myriad advantages to networked forensics, such as:
- Data Deciphering Simplified: Log dismantling facilitates easy interpretation of log entries, effectively automating the process and conserving time and additional resources.
- Risk Detection: Scrutinizing dissected logs can expose potential threats and inconsistencies, thus enabling proactive risk mitigation processes.
- Evidence Assembly: In instances of security breaches, disassembled logs can turn out to be precious legal proof. Log disassembly translates this raw data into accessible and meaningful information.
- System Monitoring: Log disassembly aids in maintaining a vigilant eye on system functionalities and prospective malfunctions.
Challenges and Countermeasures
Despite offering a number of benefits, log disassembly in networked forensics can pose a few obstacles. The sheer volume of log entries can prove daunting to manage and interpret, and the procedure might turn time-consuming. The intricate nature of the data also poses challenges in extracting meaningful insights.
Implementing superior log disassembling techniques and tools can prove resourceful in surmounting these hurdles. Techniques like sequence recognition indicators, scripted automation languages, and specially-designed utilities help streamline and enhance the process. Additionally, advanced technologies such as machine learning and artificial intelligence are being explored for their potential to augment the log disassembly process.
In conclusion, the deconstruction of logs plays a significant role in networked forensic investigations. It efficiently manages data, identifies potential threats, compiles legal evidence, and monitors the system. Despite potential challenges, the value added by log disassembly renders it a non-negotiable component in the domain of network forensics.
Advanced Log Parsing Strategies for Threat Hunting
In the realm of data protection, proactive threat containment recommends detecting and disarming likely digital threats prior to their harmful impact. Log interpretation is an essential backbone to this undertaking, yielding the crucial information needed to spot unusual activities and suspicious transactions. Threat containment initiatives can increase their success rate significantly by harnessing sophisticated log interpretation techniques.
Log Interpretation: The Vital Component in Threat Containment
Turn logs into user-friendly, dissectible facts via log interpretation is of ultimate importance in threat containment. It functions as the eyes and ears of the cyber safety unit, revealing invaluable snippets of system tasks. The breakdown of logs equips threat trackers with the capability to bring to light inconsistencies and regular sequences that may act as pre-warnings of a security breach or imminent digital attack.
Elevated Methods of Analyzing Logs
There exists a number of elevated methods for log interpretation suited for threat containment, which include:
- Pattern Identification: Reviewing logs for possible threats by recognizing recurring sequences like persistent log-in failures traced to a single IP source may indicate an attempted comprehensive force attack.
- Deviation Recognition: This implies noticing variations from the norm, suggesting potential threats. An unusual surge in network traffic might allude to a DDoS onslaught.
- Affiliation Analysis: Interpreting various log sources for co-related data to identify possible threats. A suspicious IP source appearing in different logs executing unusual activities serves as an example.
- Chronological Series Study: Studying log records over a duration to note trends and sequences that might indicate a potential threat, like a steady increase in CPU usage may suggest an ongoing cryptojacking assault.
Software Aid for Advanced Log Analysis
Several tools provide log interpretation assistance for threat containment:
- Splunk: A comprehensive tool that aids in accepting extensive log data, a perfect companion in threat containment.
- ELK Stack (Elasticsearch, Logstash, Kibana): A triple threat open-source tool designed to accept, dissect, and illustrate logs, a handy aide for threat trackers.
- Graylog: A free log management software providing extensive log analysis and an impressive range of search and study features.
- LogRhythm: A full-scope solution for handling security-related information and events (SIEM), offering advanced log analysis and study capabilities, a great addition to the threat containment toolbox.
Trailblazing Techniques for Log Analysis
These tools can be amplified using trailblazing techniques including:
- Standard Expressions: Can be used to explore log data sequences, serving as a helpful tool in threat containment pursuits.
- Machine Learning: Machine learning algorithms can be programmed to bring to light inconsistencies and suspicious sequences in log data, steering towards effective threat containment.
- Scripting: Writing code lines to automate log analysis and study procedure, saving crucial time and resources.
By and large, elevated log analysis techniques remain crucial for digital threat containment. By incorporating these methodologies into their workflows, professionals can adopt a proactive approach, identifying and disarming cyber threats, thus strengthening the system's security framework.
Log Parsing Metrics: A Vital Component for System Monitoring
The sphere of system oversight relies heavily on log parsing metrics. They form the fulcrum of the surveillance course, supplying invaluable perspectives on the system's efficiency, safety, and comprehensive wellness. This article will dive into the essence of log parsing metrics, their distinct typologies, and their integration into productive system surveillance.
Grasping the Concept of Log Parsing Metrics
The deductions from log file assessments provide the concept of log parsing metrics. A quantified illustration of the undertakings of a system is thereby produced, simplifying the monitoring process, scrutinizing, and identifying any potential hitches. They can be as straightforward as tallying specific occurrences to convoluted computations comprising of multi-faceted data.
For instance, a rudimentary log parsing metric might involve totting up unsuccessful login trials to a system. A convoluted metric could incorporate establishing the mean time between certain occurrences or discerning behavioral patterns that could hint at a looming security menace.
Segmenting Log Parsing Metrics
Several categorizations of log parsing metrics exist, each tailored to a different facet of system surveillance. Here are some illustrated examples:
- Occurrence Tally Metrics: These metrics tally the frequency of a particular occurrence within a log file. For example, the total number of successful or failed login attempts.
- Chronological Metrics: Metrics of this type ascertain the time interval between specific occurrences. In essence, the duration from when a user logs into the system to when they log out, or the period between a system glitch and its rectification.
- Sequence-Based Metrics: Metrics in this category help decipher patterns or events’ sequence within log files. This aids in spotting anomalies or impending security threats.
- Probabilistic Metrics: Applying statistical principles to analyze log data defines these metrics. They assist in pinpointing trends, deviations, and other pivotal information.
Influence of Log Parsing Metrics in System Surveillance
Log parsing metrics prove vital in system oversight for various reasons:
- Efficiency Surveillance: Log metrics prove instrumental in tracking system efficiency. Time-based metrics handy in discerning procedures taking more time than expected, indicative of possible efficiency complications.
- Safety Surveillance: Log metrics aid in spotting security risks. An abrupt rise in failed login attempts could suggest a brute force onslaught.
- Troubleshooting: Parsing metrics prove helpful in troubleshooting by detecting patterns that precede system breakdowns or crashes.
- Capacity Projection: Log metrics offer insights into system usage tendencies, thereby assisting in capacity projection and resources’ allocation.
Applying Log Parsing Metrics: A Live Illustration
Imagine a situation where a system administrator intends to oversee a web server's efficiency. They could utilize log parsing metrics to keep tabs on HTTP inquiries, mean reply time, and failed requests' percentage.
By assessing these metrics, the administrator could detect any efficiency glitches like a sudden surge in traffic or an uptick in failed requests. They could then rectify the issues by bolstering server resources or rectifying identified bugs.
Wrapping up, log parsing metrics are essential components in system surveillance. They offer a numerical snapshot of system tasks, simplifying efficiency monitoring, discerning security risks, and troubleshooting hitches. By harnessing these metrics' power, firms can guarantee seamless operations of their systems and swiftly respond to potential glitches.
Future Trends in Log Parsing: A Forecast
IT security protocol now relies heavily on the process known as log parsing, a strategy projected to develop and innovate to suit the continually changing demands. Let's delve into the advancements predicting to shape its path forward.
The Reign of Machine Learning and AI: Automated Innovations
The projection is clear - Machine Learning (ML) and Artificial Intelligence (AI) are poised to revolutionize log parsing. The integration of these high-tech mediums can significantly lessen the labor-intensive, time-consuming nuances associated with log parsing.
For instance, ML techniques can learn to recognize distinct patterns in log data, providing invaluable help in exposing unusual activity that may signify a security leak. In a similar vein, AI can streamline log data analysis, minimizing the delayed response to security infringements and preventing additional damage.
Harnessing Big Data: Far-reaching Processing Power
The reliance on big data techniques is becoming an upcoming trend in log parsing. Conventional log parsing methods may come up short as the sheer quantity of log data increases. Big data platforms, such as Hadoop and Spark, boast the ability to handle massive data quantities swiftly and efficiently, making them ideal for log parsing.
On the features front, the in-memory processing provided by Spark can significantly accelerate log parsing. In contrast, Hadoop's decentralized computing capability allows processing substantial log files across multiple machines, improving scalability.
Cloud Migration: Elastic Log Parsing
A discernible shift towards employing cloud-based log parsing solutions is underway. These services offer provocative advantages over the customary on-site alternatives. Businesses can outsource their log parsing infrastructure's maintenance, leading to cost reduction and freeing up IT assets.
Moreover, these cloud-based solutions can grow in lockstep with bulky log data, serving businesses with considerable log data production. They offer sophisticated features like immediate analytics and unusual activity detection, enabling businesses to respond swiftly to security hazards.
Tomorrow's Instruments: Sophisticated Parsing
Anticipate future log parsing tools with upgraded features designed to aid quicker and more efficient log parsing. These innovations may include improved search capabilities to locate specific log file data and visualization instruments to simplify log data analysis and understanding.
In a nutshell, an exciting journey lies ahead for log parsing. Advanced techniques and futuristic tools will not only simplify the procedure for IT professionals but also furnish businesses with heightened security threat defenses.
FAQ
References
Subscribe for the latest news