Infrastructure Monitoring
Operational dexterity, consistency, and optimization rest at the core of IT services. A critical aspect in achieving this is IT Resource Management, an underpinning procedure that affiliates companies to anticipate and mitigate potential technical complications, thereby promoting seamless business operations.


Deciphering IT Resource Management
IT Resource Management, a diligent process, concentrates on analyzing diverse aspects like severs, data repositories, software utilities, etc. This process expedites meticulous inspections of operational health, readiness, and integrity of these core aspects, enabling IT workforce to sustain superior service deliverables.
One of the vital results of IT Resource Management involves maintaining uninterrupted, optimal functioning of all technical systems while outperforming expected performance indexes. This process is inclusive of accumulating information from all ends, scrutinizing it to decode trends and operational patterns, and utilizing this vast data pool to devise informed decisions related to IT resource allocation.
Scope of Infrastructural Surveillance
The range of IT Resource Management extends beyond the evaluation of IT system performances. It assimilates the ongoing scrutiny of the system’s security mechanisms by ensuring every segment is equipped with the latest security updates and examining any potential loopholes that could invite cyber-attacks.
Moreover, infrastructural surveillance also includes the systematic mapping of resource usage. This aids IT specialists in forecasting future demands and planning necessary tweaks or upgradations in the existing IT infrastructure.
Monitoring Tools - An IT Lifeline
Monitoring tools in the IT realm hold cardinal importance. These tools accumulate information from multiple sources, represent data in an easily comprehensible visual format, and prompt alerts at the onset of anomalies. They can monitor a myriad of parameters including memory utilization, CPU usage, network capacity, disk space, and others.
These monitoring tools can also be integrated with other IT managerial systems including incident response, and configuration management systems. This enables the IT personnel to pool in data from several sources, providing them with a holistic view of the IT infrastructure. This comprehensive outlook bolsters understanding of the IT network‘s functionality.
Evolution of Infrastructural Monitoring
During the formative years of IT, infrastructural monitoring was a manual task was that involved physically examining servers and other hardware. However, due to progressing complexities and the wide-scale nature of IT, those methods are now archaic.
Modern-day monitoring has transitioned towards automation, employing tools that can simultaneously track vast assortments of devices and systems. Furthermore, advancements in Artificial Intelligence and machine learning have armed today's monitoring tools with the capability to identify current glitches as well as anticipate potential ones while suggesting preemptive solutions.
In conclusion, IT resource management is a key component in keeping up with the brisk pace of current IT administration. It enhances uniform operations across an organization’s tech sphere by providing real-time insights into the operational health and overall stability of IT modules. This helps to maintain service quality, tighten security controls, and optimally prepare for future needs.
The Importance of Effective Infrastructure Monitoring
With the advancement of technology, corporate environments are more dependent than ever on their tech setup to uphold operations and catalyze advancement. This underlines the vital role of comprehensive infrastructure supervision in framing a fruitful business approach.
Sustaining Uninterrupted Business Operations
A significant advantage of comprehensive infrastructure supervision lies in its capacity to maintain uninterrupted business operations. By regularly inspecting the fitness and functionality of your tech setup, it's possible to uncover and rectify budding issues before they develop into major complications that might hamper your operations. Such a preventive stance can markedly decrease downtime, guaranteeing that your business runs seamlessly and productively.
Visualize a situation where a vital server in your network encounters a hardware malfunction. Absence of effective supervision might leave this problem undetected until it triggers a full-blown outage, causing substantial downtime and productivity loss. On the contrary, having a sturdy infrastructure supervision system would alert you to the situation at the earliest, enabling a prompt resolution without hampering your operations.
Boosting Performance and Efficiency
Comprehensive infrastructure supervision can augment the capabilities and effectiveness of your tech systems. Offering immediate insights into your setup's functionality, supervision tools pinpoint obstacles and inefficiencies that might be hampering your operations. This can guide you in refining your systems and operations, bolstering performance and output.
For example, by scrutinizing network traffic patterns, you can spot areas for improvement in your network setup. These could range from excessive bandwidth consumption by less important applications or network congestion during specific timeframes. Recognizing these issues allows you to enhance your network setup to improve overall performance.
Strengthening Security and Compliance Adherence
The contemporary digital security landscape perpetually exposes businesses to risks from hackers and cybercriminals. Comprehensive infrastructure supervision can contribute significantly to your organization's security blueprint by offering transparency into your tech environment and helping identify potential security risks.
Monitoring tools, for example, can alarm you to unusual occurrences on your network, such as an alarming number of login attempts or unexpected alterations to system settings, signaling a likely security breach. Such tools enable you to act swiftly in response to potential threats, reducing the possibility of a security compromise.
In addition, infrastructure supervision can assist in ensuring adherence to industry norms and standards. Several regulations mandate businesses to oversee their tech environments and maintain logs of system activities. Infrastructure supervision capabilities can aid compliance with these prerequisites, preventing expensive violations and sanctions.
Cost Efficiency
Lastly, comprehensive infrastructure supervision can result in remarkable cost efficiency. By assisting in preventing downtime, enhancing performance, and fortifying security, supervision can help steer away from the expenses related to system outages, inefficiencies, and security breaches. Further, by enabling transparency into your tech environment, supervision tools aid better decision-making regarding tech investments, enabling resource optimization and cost reduction.
In conclusion, comprehensive infrastructure supervision is not merely desirable but of critical importance for businesses in the contemporary digital era. By offering insights into your tech environment, preventing downtimes, boosting performance, fortifying security, and achieving cost efficiency, infrastructure supervision can significantly contribute towards business profitability.
Understanding Different Infrastructure Monitoring Techniques
Overseeing IT systems can be likened to an involved puzzle, utilizing a spectrum of techniques to maintain a dynamic and optimized network. This can be primarily sorted into two modes: Dynamic Evaluation and Static Evaluation.
Dynamic Evaluation
Dynamic Evaluation or "proactive monitoring" as some might cite, is a methodology wherein details are requested from networking equipment to ascertain their status. Primarily preventative, it allows for quick detection of issues as soon as they emerge. It involves the use of fabricated communications, or modeled interactions, to pinpoint any performance lapses or potential bottlenecks.
Consider this example, a dynamic evaluation tool might forward a request to a web host every several minutes to confirm its availability. If the host fails to respond within the set time, the tool escalates a warning to alert the IT staff.
Static Evaluation
In contrast, Static Evaluation, or "reactive monitoring," involves analyzing the data moving through the network, without direct interaction with it. This methodology is focused on pinpointing aberrations or irregular patterns in data movement. Static evaluation typically involves data collection from a broad spectrum of sources such as record logs, data traffic metrics, and packet histories.
For instance, a static evaluation tool would audit a web server's record logs to pinpoint any peculiar activities. If it finds an unexpected surge in traffic or heightened error alerts, a warning would be triggered.
Dynamic and Static Evaluation - An Analogy
Supplemental Evaluation Techniques:
Additional methods to enhance dynamic and static evaluations for stronger IT system oversight could include:
- Capability Inspection: This deals with inspecting the productivity of all IT equipment elements which includes servers, database systems, and connectivity networks; the goal being early detection of potential problems and maximal resource utilization.
- Availability Inspection: This seeks to ensure all vital mechanisms and services are perpetually available and performing at peak efficiency.
- Anomaly Inspection: This is centered around discovering any discrepancies or faults in the IT systems that need urgent rectification.
- Protection Inspection: This technique involves continuous surveillance for any security breaches to the IT systems, and protection against data breaches and cyber threats.
Employing the appropriate amalgamation of these distinct but essential techniques can ensure an organization's IT systems function seamlessly. Adept comprehension and practical application of these methodologies can significantly enhance the potential of IT systems oversight.
Key Elements in Infrastructure Monitoring
Infrastructure surveillance entails many interconnected components. Familiarizing with these parameters can lead to a seamless and robust oversight of your IT ecosystem.
Component 1: Information Collation
The inaugural stage of IT environment supervision is information collation. This process extracts data from several parts of your IT environment that includes workstations, networks, software, and information systems. The different types of data obtained include system logs, metrics, and events.
System logs provide comprehensive data of system activities, while metrics offer measurable data that track system performance and overall health. Events data, alternatively, reveals specifics about certain occurrences within the system.
Component 2: Information Interpretation
Post-data collection, data interpretation ensues to spot anomalies, trends, and patterns. Recognizing potential complications at an early stage before they magnify aids in preventing significant issues.
Several platforms and methodologies can assist in data interpretation. Pictorial representation can help in recognizing patterns and trends while AI-based algorithms can highlight abnormalities and foresee future trends.
Component 3: Alarms and Communication
Alarms and communication play a vital role in IT environment supervision. When specific conditions arise, alerts can notify the concerned authorities to take immediate action.
For example, an alert notifying elevated usage of CPU on a specific server can forewarn about an impending issue allowing you to handle it before the server exhausts its resources and potentially stops functioning.
The communication technique is situational, depending on the alert's urgency and the recipient's comfort; choices range from email, SMS, or push messages.
Component 4: Pictorial Representation
The pictorial representation of collected data facilitates easy interpretation and understanding, making it an essential aspect of IT environment supervision.
Various methods of pictorial representation such as dashboards, diagrams, and graphical representation provide a comprehensive and simple view of data. For instance, a graphical representation can illustrate the trend of CPU usage over a period.
Component 5: Task Automation
Task automation plays a crucial role in IT environment supervision; implementing it makes processes more streamlined, reducing manual errors and enhancing efficiency.
Processes that can be automated include data collection from servers, alert activation when certain conditions are met and routine management tasks like server restart when unresponsiveness is detected.
Component 6: System Synchronization
The final aspect of IT environment supervision is system synchronization – tying up your supervising system with other systems in the IT environment like the incident management system or the ticketing system.
If an alarm rolls off, an automated ticket gets created in the ticketing system resulting in faster and efficient issue resolution.
To summarize, Information Collation, Interpretation, Alarms and Communication, Pictorial Representation, Task Automation, and System Synchronization are all imperative for successful, efficient, and robust IT environment oversight. Having thorough knowledge and executing these processes strategically will warrant a fool-proof and efficient IT environment supervision.
Best Practices for Infrastructure Monitoring
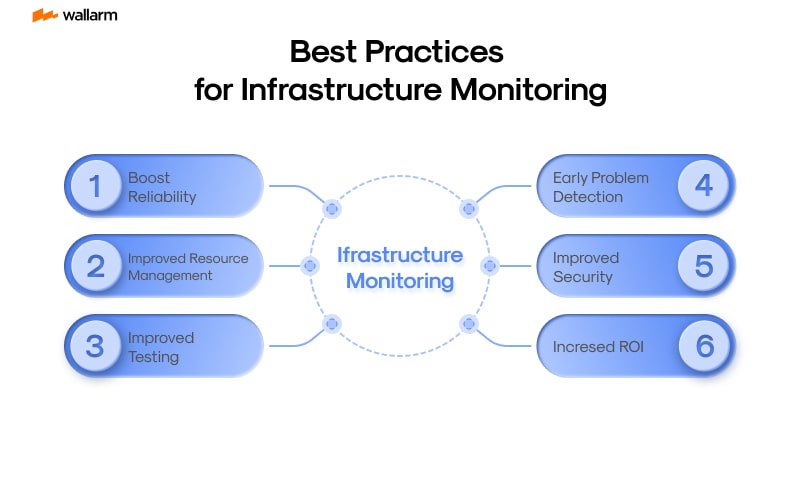
Strategic Moves towards Advanced IT Systems Management
Mastering the digital realm while ensuring a high performance is largely dependent on a rigorous monitoring of your Information Technology (IT) environment. This management is not limited to securing the operational efficiency of your IT services and solving problems swiftly. It also includes adopting concise and systematized procedures.
Identifying Concrete Objectives
Embarking on a fresh IT systems watchkeeping process demands the composition of a strategic plan that’s steered by clear-cut goals. These benchmarks could extend from a wide range that includes sustained system operations, identifying delays in performance, anticipating possible hold-ups or even achieving optimal functioning stages. The formation of such focused objectives can guide your selection of the right supervisory tools and matching schemes.
Choose Suitable Technology Arrays
There’s a vast offering of IT systems management programs available, and choosing the one that fits your predefined goals, set budget, and the complexity of your tech landscape is key. These programs, each offering unique characteristics, range from free, open-source tools to paid ones. Some are designed specifically for smaller environments while others are built to handle large, complex system configurations.
Encourage Comprehensive Monitoring
The range of system management stretches beyond the confines of servers and networking channels. It ought to include a wider approach that takes into account every element of the IT environment in play. This means keeping an eye on databases, services, applications, inclusive of user-interface experiences. This comprehensive view of your system’s performance may highlight possible issues that could complicate your entire system’s functionality.
Set Up Proactive Alert Mechanisms
Engaging IT systems management essentially aims at rectifying system challenges before they worsen performance or cause system escalation. Consequently, it is vital to set up alarms and notifications to alert relevant teams about the upcoming issues. The cautionary messages should be precise, provide actionable insights, and funneled directly to the corresponding teams.
Modify Inspection Plan Occasionally
The fast-paced nature of the IT industry constantly introduces new systems, applications, and technologies. Therefore, your system monitoring strategy should also welcome evolution and allow necessary adjustments regularly. This might involve incorporating new performance metrics, tweaking the intensity of alert systems, or swapping between monitoring software.
Incorporate Automation
Integration of automation within your IT system oversight can significantly enhance efficiency by mitigating the chances of human errors and freeing up valued time. Automation could be utilized either in data gathering, scrutinizing compiled data, or even in acknowledging alert signals.
Fortify Your Team
Finally, your team should be thoroughly familiar with the monitoring tools and schemes in place, able to decode the gathered data, respond to alert signals, and troubleshoot persistent issues. This will ensure expedited and highly efficient problem resolution.
In conclusion, advanced IT system management is dependent on a logical strategy formulated around the right technology stream, holistic monitoring, timely alert mechanisms, periodical plan assessments, automation, and a well-trained staff team. Implementation of these operational strategies will strengthen your system's dependability and performance, rendering it completely prepared to support your business objectives.
Identifying The Right Tools for Infrastructure Monitoring
Selecting an appropriate monitoring solution for your IT framework is a pivotal move in ensuring the hassle-free administration of your technological ecosystem. Given the large array of alternatives out there, picking the one that best fits your specific requirements can often seem like a formidable challenge. Here, we aim to shepherd you through the process of pinpointing just the right systems for overseeing your infrastructure capabilities.
Pinpointing Your Criteria
Prior to launching your search through the multitude of technologies available, it's a top priority to pinpoint the unique criteria that your operation entails. Doing this demands distinguishing the critical elements of your framework requiring surveillance, the level of scrutiny needed and the frequency of checks needed.
For instance, if the structure of your operation is predominately server-based, you may require a system focusing on server surveillance. Conversely, should your operation rely on a complex web of multiple devices, your needs may be better met with a system offering an extensive suite of network monitoring tools.
Evaluating Specifications and Capacities
Once your leaf of needs is clear, you will be in an excellent position to assess the functions and capacities of the myriad of offerings out there. A selection of essential specifications to consider include:
- Holistic Surveillance: The system should be proficient in overseeing all aspects of your framework, including servers, networks, apps, databases, and storage.
- Instantaneous Scrutiny: The system should deliver immediate comprehension of your framework's efficiency, allowing quick issue identification and resolution.
- Alert and Update Capacities: The system should possess robust alert and update features, ensuring that potential problems don't go unnoticed.
- Insight and Analysis Reports: The system should furnish comprehensive analysis and reporting, aiding decision-making with trends and stats.
- User-Friendliness: The system should be straightforward to install, configure, and operate, utilizing an intuitive user interface and easy navigation.
- Upgradeability: The system should offer upgradeability, letting you enhance your framework without it compromising efficiency.
- Unification: The system should harmonize smoothly with other entities in your tech ecosystem, like ticketing systems, CMDBs, and automation processes.
Comparing Varied Offerings
Armed with a thorough evaluation of these capacities and specifications, you can compare different offerings in terms of their performance, dependability, and investment. Here's a basic comparison table to assist in your informed decision process:
Trying It Out
Many IT overseeing system providers offer a cost-free trial or demonstration. This permits you to investigate the system’s compatibility with your ecosystem and to determine if it fulfills your requirements. Throughout this trial time, focus on the system's efficiency, ease of operation, and the support quality from the provider.
In conclusion, singling out the ideal system for managing your IT framework calls for grasping your needs, assessing system functions and capabilities, weighing up differing offerings, and test driving the product. Using this formative methodology will ensure you pick a system that not only serves your present needs but can also expand with your enterprise as it grows.
Understanding Infrastructure Monitoring Metrics
IT support teams continuously analyze and manage the performance and health of their IT systems using quantifiable information known as infrastructure tracking metrics. This information is critical in providing sophisticated insights about the working efficiency of various components like servers, digital networks, software, and data repositories. Recognizing the importance of these data readings is crucial for an effective network observation. They form the foundation for informed decision-making and future planning.
Categories of IT System Observation Data Readings
Several categories of system observation data readings require familiarity from IT teams. They include:
- Performance Indicators: The statistics of this category measure the effectiveness of different parts of the IT system. They include details such as Central Processing Unit (CPU) usage, memory exploitation, disk usage, and the allocation of digital network bandwidth. By using this information, IT teams can identify inadequacies and introduce improvements.
- Availability Indicators: This category includes information that tests the reachability of the system's diverse elements. With figures like uptime, response duration, and downtime, these data readings help IT teams ensure their IT systems are always reachable and responsive.
- Capacity Indicators: These gauge the abilities of the system's components. They include information such as memory capacity, storage space, and network bandwidth restrictions. These indicators allow IT teams to plan for future needs and avoid complications related to capacity.
- Reliability Indicators: This category involves statistics that measure the dependable nature of the system's parts. They include information like error rates, recovery periods, and failure frequencies. These indicators assist IT teams in validating the resilience and dependability of their network.
- Security Indicators: This category involves statistics that evaluate the safety level of the IT system. It includes data like the frequency of security violations, their severity, and resolution periods. These indicators aid IT teams in reducing their security risks and securing their systems.
Choosing Appropriate Indicators
Choosing the right indicators for system tracking could be challenging. Here are some factors that influence this selection process:
- Relevance: Selected indicators should align with the goals of the organization and IT team. For instance, picking performance indicators would be suitable if the goal is to increase software productivity.
- Measurability: Chosen indicators should be quantifiable using the tools and technologies the IT team has access to. For instance, without suitable tools to measure network bandwidth usage, such an indicator would be ineffectual.
- Actionability: Selected indicators should inspire actions. For example, if a statistic indicates high CPU usage, the IT team should be able to take concrete actions to reduce it.
- Consistency: Chosen indicators should provide reliable readings consistently over time. This constant nature enables IT teams to track progress over time, make critical comparisons, and plan resource distributions.
Making Use of Indicators for Decision-Making
These system observation indicators serve multiple decision-making purposes:
- Enhancing Performance: For instance, if indicators show substandard performance of a component, the IT team can improve it through hardware overhauls, software upgrades, or configuration changes.
- Capacity Planning: For instance, indicators showing a potential breach of the limits by a component can encourage the IT team to plan for extra capacity through hardware purchase, network bandwidth growth, or additional storage space.
- Incident Response: For instance, security violations indicated by statistics can motivate the IT team to investigate, limit the impact, and recover from the incident.
- Risk Management: For instance, statistics indicating a risk of failures can guide the IT team to manage the risk by introducing redundancy, enhancing reliability, or strengthening security measures.
In short, understanding IT system observation indicators is crucial for effective system observation. These indicators offer valuable insights about the system's operation, aiding in decision-making and proactive planning. By selecting relevant indicators and using them effectively, IT teams can ensure optimal performance, constant availability, sufficient potential, dependability, and safety of their IT systems.
Designing an Effective Infrastructure Monitoring Strategy
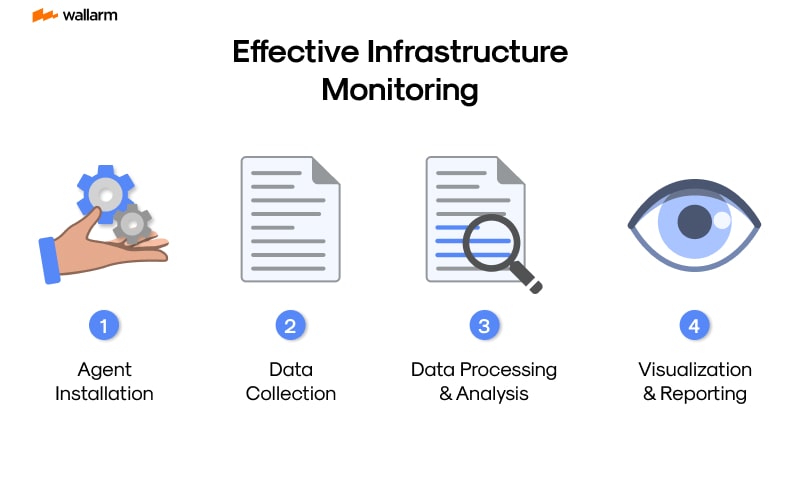
Crafting a valuable strategy for supervising your technical ecosystem is indispensable for maintaining seamless IT operations. This strategy must be exhaustive, scrutinizing every facet, from compute nodes and networks to apps and data storage, while sporting the nimbleness to adapt according to the changing nature of your infrastructure.
Gaining Infrastructure Insight
The pioneer move in architecting an indispensable infrastructure supervision methodology entails gaining an insight into your infrastructure. This requires acknowledging every piece that forms your ecosystem, including hardware, software solutions, networks, and data warehouses. Grasping how these elements intermingle and facilitate your operational processes is equally crucial.
Architecting Supervision Objectives
After acquiring a sound understanding of your ecosystem, the subsequent move is architecting supervision objectives. These objectives must sync with your venture ambitions and must carry an accountable value. For instance, you could envisage an objective to slash downtime by 10% or to boost response durations by 15%. These objectives would drive your supervising endeavors and enable you to assess your victories.
Defining Essential Efficacy Markers (EEMs)
In order to assess your advancement towards your supervision objectives, it is crucial to define Essential Efficacy Markers (EEMs). These metrics provide an overview of your ecosystem's well-being and efficiency. EEMs commonly employed in infrastructure supervision comprise system availability, reaction duration, error frequency, and resource consumption.
Choosing Supervision Instruments
With your objectives and EEMs well defined, it's time to choose the supervision instruments which will empower you to realize these objectives. These instruments must offer on-the-spot insights into your ecosystem, caution you about possible issues before they become critical, and generate in-depth analyses aiding you to scrutinize performance and detect patterns.
Establishing Supervision Directives
Having equipped yourself with the suitable instruments, you must now establish supervision directives. These directives should stipulate what elements to supervise, the supervision timeframe, and the response to supervision notices. Furthermore, they should dictate the individuals accountable for supervision as well as the protocol for concern escalation.
Periodically Reassessing and Modifying Your Strategy
To conclude, architecting an indispensable infrastructure supervision methodology is a dynamic endeavor. It calls for periodic reassessment and modification to ensure it continues to meet your venture requirements. This might entail incorporating new facets into your supervision scope, modifying your EEMs, or changing your supervision instruments.
By adhering to these steps, you can ascertain that your infrastructure supervision is targeted, valuable, and in-sync with your venture objectives.
Case Study: Successful Infrastructure Monitoring Implementation
In the intricate sphere of technological applications, a story of effective administration of technological resources appears – a performing international banking entity, aptly named 'Bank Y' for the context of this illustration.
The Situation
Geographically dispersed across different territories, Bank Y's tech network had complexity stamped on its entity. This translation of complexity to the managing crew in the IT sector led to major obstacles which included:
- Troubles in determining and addressing complications quickly, causing frequent system failovers and disservices.
- Impediments in forecasting likely system hiccups.
- Limited insight into the overall condition and efficiency of their techie backbone.
- Suboptimal resource allocation due to an absence of autonomic systems.
The Course Of Action
Bank Y considered the idea of an exhaustive tech administration system to remedy these problems. They adopted an avant-garde surveillance system that boasted of functions like instantaneous surveillance, anticipatory data analysis, auto-generated notifications, and refined reporting.
The initiation process included a few stages:
- Examination: A comprehensive review was conducted on the present tech backbone in order to determine crucial components requiring surveillance.
- Selection of Surveillance System: Numerous systems were assessed, and the optimal one was chosen considering the functionality, scalability, and economic feasibility.
- Customization and Application: The selected system was tailored to keep an eye on crucial network elements. Customized warnings were established to inform the IT crew about possible hiccups.
- Educational Initiative: The IT crew received professional training to optimally utilize the newly adopted system.
- Validation and Launch: Prior to universal deployment, extensive testing of the system was performed.
The Aftermath
The adoption of such tech surveillance system made a marked difference in Bank Y's IT operations. Some of the notable benefits were:
- Augmented Visibility: The IT crew now benefitted from an explicit understanding of the condition and efficiency of their entire network, which helped them address issues promptly, minimizing system failovers, and augmenting service value.
- Reactive Problem Handling: The predictive data analysis feature enabled the team to spot potential hiccups before realization and take precautionary measures.
- Optimum Resource Management: Auto-dynamic systems helped the team deploy their resources optimally, granting them more time for strategic tasks.
- In-depth Reporting: The new system provided elaborative reports on network efficiency, which aided the team in making decisions based on data.
Finale
There's no denying the drastic change brought upon by effective tech surveillance, as shown through this illustration of Bank Y. By adopting an in-depth surveillance system, the bank has managed to eliminate its technical hurdles and significantly better their operational productivity. This clearly emphasizes the cruciality of tech surveillance in administering intricate technological environments.
Monitoring Physical Vs Virtual Infrastructure
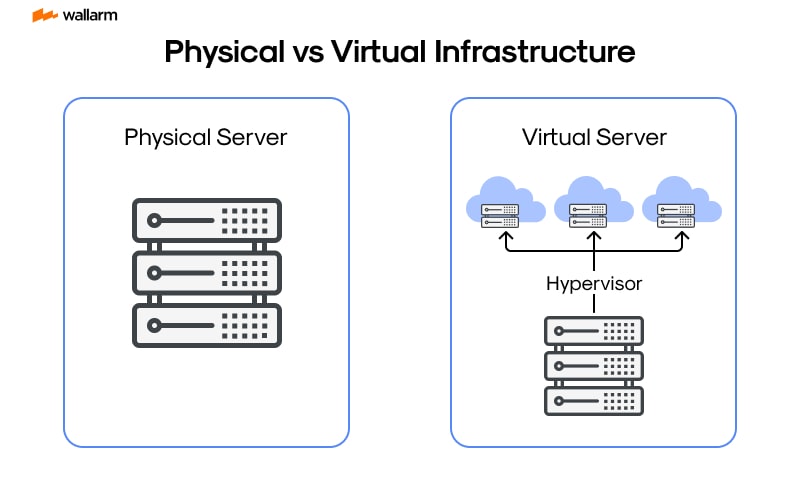
Grasping the distinctions and parallels within the expansive domain of technocentric infrastructure examination is crucial. Recognizing the unique facets of both the touchable, or physical, and the intangible, or virtual, systems, is essential for implementing specific scrutiny practices and instrumentality.
Appraising Tangible Infrastructure
Tangible infrastructure corresponds to the materialistic constituents in a tech ecosystem, which can encompass servers, routers, switches, and assorted hardware devices. Keeping tabs on these components entails comprehending their performance capacity, availability, and overall health status.
Integral Facets of Tangible Infrastructure Examination
- Materialistic Component Health: This scrutiny capitalizes on evaluating the functionality of elements like the central processing unit (CPU), spatial storage, memory, network interfaces. The breakdown of any of these components can be detrimental.
- Functionality Metrics: Metrics such as CPU usage, memory usage, disk Input/Output (I/O), and network bandwidth fall under this category. These indicators offer visibility into the hardware's functionality and can help highlight potential points of obstruction.
- Uptime Scrutiny: This entails validation checks to confirm functional hardware devices. Any instance of downtime can severely impact business functioning.
Intangible Infrastructure Examination
Contrarily, intangible infrastructure corresponds to the simulated spaces created using software, like hypervisors. This encapsulates elements such as virtual machines (VMs), virtual networks, and digital storage solutions. An evaluation of intangible infrastructure involves measuring the performance and availability of these non-tangible resources.
Integral Facets of Intangible Infrastructure Examination
- Individual VM Examination: Monitoring the functionality of each VM, inclusive of metrics such as CPU usage, memory usage, and disk I/O falls under this.
- Hypervisor Examination: Hypervisors occupy a pivotal role in virtual landscapes. Their performance and accessibility need to be kept under check.
- Resource Division: Typically, in an intangible environment, resources are disseminated among various VMs. Keeping an eye on how these resources are divvied up helps ensure no VM is monopolizing resources, causing performance degradation.
Analogy: Tangible vs. Intangible Infrastructure Examination
Tangible and intangible infrastructures although have distinctive examination conditions, also share similarities. Both mandate round-the-clock scrutiny for ensuring seamless functionality and accessibility. Specific tools, tailored for their corresponding situations, are required for each.
Nevertheless, examining intangible infrastructure can be intricate due to the volatile nature of virtual spaces. VMs can be generated, relocated, or obliterated dynamically, which complicates their examination.
Code Piece: Observing CPU Utilization
For instance, to observe CPU utilization on a physical server, a command-line utility like top in Linux can be of use:
For a simulated space, a tool like VMware's esxtop could be utilized to monitor CPU usage:
In conclusion, although contrasting examination methods apply to tangible and intangible infrastructures alike, the end goal is identical: maintaining ideal performance levels and availability. Recognizing these disparities and similarities can aid in selecting the appropriate tools and methodologies to manage your infrastructure supervision needs.
Investigation and Troubleshooting in Infrastructure Monitoring
Within the sphere of system oversight, diagnosing problems and finding solutions are pivotal elements that promote uninterrupted workflow. These elements are vital for spotting and rectifying concerns that could manifest, thereby averting possible breakdowns and endorsing ideal functioning.
The Diagnosing Procedure
Diagnosing within the field of system oversight entails a comprehensive scrutiny of your structure to single out possible drawbacks. This procedure usually initiates with the recognition of an irregularity or a discrepancy from the expected functioning. Once a concern has been singled out, the ensuing step is to unearth the source.
This can be achieved through diverse ways, such as studying system activity records, assessing functioning metrics, and admininstering system checks. For instance, if your supervising structure notifies you of an abrupt escalation in CPU consumption, you may kick off your diagnosis by examining the system records to verify if any peculiar occurrences have transpired during the anomaly.
Solution-Finding Strategies
Once the source of the concern has been singled out, the ensuing step is finding a solution. This entails making strides to rectify the concern and reinstate the structure to its routine operation. The specific strides involved in finding a solution will pivot on the nature of the concern.
For example, if the concern is a software glitch, the solution-finding procedure may involve integrating a patch or an upgrade to resolve the glitch. If the concern is a hardware malfunction, the solution-finding procedure could involve substituting the impaired component.
Contrast Between Diagnosing and Solution-Finding
Guidelines for Diagnosing and Solution-Finding
- Keep a Detailed Record: Preserving an account of all your discoveries during the diagnosing and solution-finding procedure can aid in future references and in spotting patterns or recurring concerns.
- Employ the Suitable Instruments: Use appropriate instruments for diagnosing and solution finding. This might encompass activity record analysis instruments, system check instruments, and performance supervision instruments.
- Observe a Methodical Technique: Refrain from making hasty judgements. Instead, observe a methodical technique to unearth the crux of the concern and then apply the appropriate strategies to rectify it.
- Verify Your Solutions: After integrating a solution, always administer a system check to ascertain that the concern has been rectified and that no secondary concerns have surfaced.
- Learn from Every Concern: Treat every concern as a learning opportunity. Utilize it to enhance your system and your supervising procedures.
To summarize, diagnosing and finding solutions are vital elements within the sphere of system oversight. By effectively singling out and rectifying concerns, you can promote the reliability and performance of your system, thereby diminishing downtime and amplifying productivity.
Setting Up Alerts in Infrastructure Monitoring
Within the scope of overseeing computer systems, having a well-founded alert system in place is crucial. These instant prompts serve a crucial function by warning IT personnel of impending issues before they escalate into significant crises. This analysis will explore how alerts are set up, their various types, and practical strategies for configuring them effectively.
Types of Alerts
When examining computer system supervision, alerts fall into two primary classifications: metrics-driven signals and anomaly-detection signals.
- Metrics-driven signals: The trigger for these signals is a specific benchmark exceeding a previously established limit. For instance, a signal could be programmed to sound the alarm should a server’s CPU usage surge past 80%.
- Anomaly-detection signals: Far more intricate, these triggers are set off when the system pinpoints rare occurrences that stray from routine operations. An example to imagine would be an irregular bump in network traffic during atypical hours.
Setting Up Alerts
The setup process for alerts within system management encompasses various stages:
- Identify Key Benchmarks: The preliminary step is determining which key indicators need to be tracked, such as CPU usage, memory intake, network bandwidth, storage capacity, and others.
- Establish Thresholds: For each indicator, set a limit that, once breached, will fire off a signal. These calculated boundaries should be reasonable, reflecting your system's habitual functioning.
- Define Signal Parameters: Put in place parameters for signals, including their urgency level, the message content, and the delivery method (e.g., email or text message).
- Test Signals: After setting up the triggers, their efficiency should be validated by deliberately triggering a situation that would set off the signal.
- Review and Adjust: Peruse your triggers on a regular basis and tweak thresholds and parameters as needed. This becomes critically important as your system grows and evolves.
Effective Strategies for Signal Configuration
When configuring alerts in a system management context, few valuable strategies should be observed:
- Prevent Signal Overload: An overload of alerts may cause teams to become desensitized and overlook them as a consequence of signal fatigue. Avoid this by ensuring that signals have a significant impact and cannot be easily dismissed.
- Prioritize Signals: Not every alert has equal importance; some require more immediate attention than others. Categorize signals based on the severity of their implications and their potential to disrupt your operational flow.
- Employ Diverse Delivery Methods: Use multiple delivery methods, like emails, text messages, and push notifications, to guarantee the timely arrival of alerts to relevant IT personnel.
- Furnish Detailed Context: Allow IT personnel to fully comprehend the situation by providing thorough context in your signals. This should contain details like the affected system, the incident's timestamp, and potential implications.
In closing, preparing alerts in the realm of system management is a vital procedure requiring conscientious planning and implementation. By following the steps and effective strategies stated in this breakdown, organizations can ensure that potential hitches are flagged swiftly, allowing for prompt resolution and minimal impact.
Enhancing Your Security With Infrastructure Monitoring
In the age of information technology, unrivalled attention to one's cyber protection is a requirement for any corporation. The escalating intricacy and high-tech nature of digital attacks amplify the urgency to implement top-of-the-line security tactics. An imperative strategy is the surveillance of one's technology framework, involving meticulous scrutiny of your IT network to spot irregularities or looming cyber dangers.
The Implication of IT Surveillance in Cyber Protection
The function of IT surveillance in the sphere of cyber protection is non-negotiable. It renders a clear panorama of your IT network, facilitating prompt detection and counteraction to looming cyber risks, thus mitigating substantial harm.
- Alertness to Cyber Threats: Constant scrutiny of your network by IT surveillance tools helps unearth any abnormal behavior, from an abrupt surge in data traffic to illegitimate penetration attempts. Early identification allows for swift countermeasures, thwarting a possible cyber breach.
- Oversight of Security Loopholes: Constant surveillance also assists in locating feeble points in your system, such as obsolete software, frail passwords, or inaccurately setup servers. Upon discovery, these weak spots can be corrected or upgraded, creating a bulwark against cyber manipulations.
- Bounce-back Strategy Post Cyber-attack: When a cyber violation transpires, IT surveillance contributes crucial data needed for counteractive measures. This data includes specifics about the attack, compromised systems, and potential repercussions. This intelligence subsequently enables your cyber protection team to combat the situation effectively, thereby mitigating damage.
IT Surveillance Techniques in Augmenting Cyber Protection
Several IT surveillance techniques can be applied to elevate cyber protection, namely:
- Inspection of Log Data: This involves the collection and evaluation of log data derived from multiple sources within your IT network. This data offers useful intel into system activity and potential cyber threats.
- Data Traffic Surveillance: This implies careful scrutiny of your network traffic for abnormal or questionable activity. Such surveillance can help uncover possible cyber threats like DDoS breaches or illegitimate penetration attempts.
- Monitoring of Network Endpoints: This pertains to watching the endpoints on your network, such as end-user devices and servers. Such monitoring can unveil harmful software infestations, unlawful access, among other cyber risks.
Selecting the Appropriate Instruments for IT Surveillance
The selection of appropriate tools for IT surveillance is essential in amplifying cyber protection. When choosing a tool, several aspects need to be considered:
- Adaptability: The tool should possess the capability to adapt alongside your corporate growth. As your empire expands, so does your IT network. Hence, the tool needs to be proficient in managing this expansion.
- Real-time Surveillance: The tool should offer real-time surveillance capabilities. This results in immediate identification and counteraction to potential cyber threats.
- Compatibility: The tool should seamlessly incorporate with other systems and tools in your IT setting. This allows for more extensive surveillance and enhanced cyber protection.
- User-friendliness: The tool should be simple to operate and manage, ensuring your IT squad can proficiently use the tool to augment the cyber protection.
In summary, IT surveillance is an empowering strategy for improving cyber protection. It offers insight into your IT network, allowing for swift identification and counteraction to potential cyber attacks. By selecting suitable tools and methodologies, you can drastically augment your protection stance, thereby guarding your company against digital threats.
Entire Network Visibility with Infrastructure Monitoring
Unraveling Clarity in Network Operations
Specifically, network clarity signifies the degree to which IT specialists can scrutinize and interpret their network function and efficacy. This entails analyzing data pathways, identifying interconnected machinery, and evaluating the efficiency of network components. Full visibility in the network enables IT personnel to proactively control their systems, resulting in amplified speed and enhanced security.
The Role of Supervising Tools in Boosting Network Clarity
Tools designed to supervise the framework have an essential role in promoting network clarity. These tools work tirelessly to survey the network, gathering data on varied aspects such as machine states, data routes, server durability, and software efficacy. The accumulated data is analyzed and then rendered in a digestible format, offering a lucid image of the network's well-being at any point in time.
Benefits of Comprehensive Network Clarity Through Framework Supervision
- Proactive Problem Identification: Complete network clarity empowers IT personnel to anticipate and counteract possible issues before they balloon into major hurdles, lowering system idle time and enhancing network productivity.
- Heightened Security: Network clarity facilitates early identification of suspicious activity that may signal potential security breaches, enabling rapid detection and resolution, while minimizing potential damage.
- Increased Efficiency: By tracking network components, performance blockages are quickly detected to enact required adjustments, improving network productivity.
- Knowledge-based Decision-Making: Comprehensive network clarity provides useful insights that enhance strategic decision-making, improving efficiency in planning, budget allocation, and other critical IT-related decisions.
Essential Qualities of Framework Supervision Tools for Network Clarity
- Quick Surveillance: An effective tool should provide immediate feedback on network speed, enabling IT personnel to respond rapidly to any arising issues.
- Substantial Examination: The tool should be capable of inspecting every facet of the network, encompassing both physical and virtual servers, programs, and services.
- Alerts and Alerts: In the event of deviations from established performance metrics or potential problems, the tool should issue immediate warnings.
- Detailed Study: The tool should produce comprehensive reports that highlight patterns in network speed over time.
- Effortless Synthesis: The tool should integrate seamlessly with other IT survey systems, offering a unified view of the IT structure.
To conclude, meticulous supervision of the framework forms the basis for achieving comprehensive network clarity. It advances the understanding of network speed, cultivates proactive management, fortified safeness, and well-thought-out decision-making. Choosing a suitable framework surveillance instrument empowers IT teams to maintain extraordinary network efficiency and safety, by extension enhancing business attainment.
Automated Analysis and Reporting for Infrastructure Monitoring
In the world of systems oversight, incorporating automated evaluation and automated updates is crucial to amplify both productivity and adequacy of monitoring strategies. Such features not only simplify the data compilation and interpretation, but they also offer significant insights that can influence policy formulation and tactical programming.
Embracing Automation in Data Evaluation
Leveraging automation in data scrutiny is a valuable method capable of converting raw information into actionable knowledge. It employs sophisticated formulas and AI techniques to examine countless chunks of data, discern patterns, and forecast results. This procedure eradicates the necessity for manual data review, which can be labor-extensive and susceptible to inaccuracies.
An essential advantage of automated evaluation is its capacity to manage colossal amounts of information. As the intricacy of IT networks grow, the data produced can be staggering. Tools for automated evaluation can speedily handle this data, underlining crucial points that require consideration.
Additionally, a standout benefit is the rate at which results from automated evaluation can be obtained. In a high-speed corporate setting, possessing immediate access to knowledge can shift the game. It permits IT squads to spot and rectify issues before their full flare-up, thus reducing non-operational periods and guaranteeing smooth functions.
Accurately Categorizing Updates Through Automation
Automated updates supplement automated scrutiny by availing a well-organized and uncomplicated interpretation of the examined data. It creates reports according to preformulated templates, which can adapt to particular demands.
Periodic automated updates can be set, assuring that parties involved receive punctual knowledge about the system’s condition. These updates can exhibit numerous measurements, such as system availability, performance, and security breaches, providing a holistic view of the system's condition.
Furthermore, automated updates can also assist in abiding by stipulated regulations. Many rules necessitate periodic reporting on definite aspects of IT operations, and through automation of this process, firms can consistently and precisely fulfil these requirements.
Manual Vs. Automated Examination and Updates: A Comparison
Instituting Automated Examination and Updates
The inception of automated scrutiny and updates in systems oversight incorporates multiple phases. Initially, identifying critical measurements that require monitoring should take place. These could relate to performance, security or any other vital aspect of your structure.
Following that, allocation of appropriate tools for automation is necessary. There's a surplus of tools in the marketplace, each with unique features and abilities. It's important to select a tool that coincides with your demands and seamlessly incorporates into your existing network.
After tool placement, the setup of automated procedures can commence. This consists of tool configuration to compile data, carry out the analysis, and create updates following your requisites. It's also critical to arrange alerts for crucial issues, ensuring they receive immediate attention.
To summarise, automated scrutiny and updates are fundamental elements of efficient systems oversight. They do more than merely boost productivity - they offer decisive insights that can impel tactical policy formulation. By harnessing these tools, firms can safeguard the health and productivity of their networks, ultimately bolstering their business goals.
Future Trends in Infrastructure Monitoring
As we chart the course of the next advancements, we're witnessing an undeniable transformation of system surveillance methods. The brisk development of tech sectors, along with complex, tech-enabled ecosystems, prompts a demand for more advanced, self-driven, and smart monitoring tools. Here's how certain emerging trends are expected to steer the course of system surveillance strategies.
A Rise in Use of AI and Machine Learning
The penetration of technologies, such as AI (Artificial Intelligence) and ML (Machine Learning), has begun reshaping the dynamics of system surveillance. These empower entities to streamline repetitive tasks, identify recurring themes and inconsistencies in data, and foresee issues before they escalate.
For example, ML-based methodologies can sift through colossal volumes of data from diverse origins, discovering recurrent themes that may signal potential risks. This proactive management decreases system interruption and enhances the overall system efficacy.
AI, meanwhile, mechanizes the monotonous surveillance tasks, allowing IT professionals to concentrate on strategic undertakings. Also, AI extends insightful interpretations and proposals, aiding entities in making well-informed IT infrastructure decisions.
Proliferation of IoT Gadgets
With more digital gadgets getting internet-enabled, the IoT (Internet of Things) revolution will definitively reinvent system surveillance mechanisms. As IoT gadgets generate enormous amounts of data, processing and comprehending these could be challenging. Hence, futuristic system surveillance tools necessitate the capacity to process this data surge and derive valuable insights.
Proclivity Towards Predictive Surveillance
Anticipatory surveillance, equipped with data and analytics to foresee issues before their onset, is gaining momentum. This methodology helps circumvent extravagant system interruptions, enhancing efficacy and enabling IT teams to focus on urgent matters first.
Increase in Adoption of Cloud-Dependent Surveillance Tools
Owing to their scalability, adaptability, and economical nature, cloud-dependent surveillance tools are witnessing a surge in adoption. They enable entities to supervise their system from any location, at any time, and using any gadget. Moreover, as all information is aggregated and centrally stored, deriving accurate and timely insights becomes more straightforward, enhancing decision-making and boosting overall system efficacy.
Inevitability of Comprehensive Surveillance Solutions
With the increasing intricacy of tech ecosystems, the inevitability of comprehensive surveillance solutions is more apparent. Such solutions offer an all-encompassing view of the entire tech infrastructure, spanning servers, networks, applications, and gadgets.
Comprehensive surveillance solutions aid entities in quickly spotting and dealing with issues, leading to decreased system interruptions and enhanced efficacy. They provide beneficial understandings of how different tech infrastructure components interrelate, aiding entities to streamline their systems and procedures.
To conclude, the future trajectory of system surveillance seems bright, with impressive trends awaiting to emerge. By harnessing the potential of these trends, entities can augment their surveillance prowess, boost system efficacy, and propel their business success.
Incorporating AI and ML in Infrastructure Monitoring
The continuously developing technology environment has been greatly reshaped by two predominant tools - artificial intelligence (AI) and machine learning (ML). These advanced mechanisms have sparked progress by broadening the scope of oversight over digital systems, granting a more hands-on approach by computerizing redundant tasks, pinpointing patterns, providing early warnings for potential roadblocks, and generating impactful insights.
The AI and ML Impact on Digital System Examination
The utilization of AI and ML has initiated an unprecedented shift in the way corporations scrutinize their digital systems. Traditional monitoring tools heavily rely on preset limits and rules and often fall short in detecting complex issues and outliers. However, AI and ML excel in handling and exploring vast data collections, identifying trends, and presaging possible complications in advance, thereby avoiding possible disruption in business flow.
Advanced AI-centered monitoring systems examine multitudes of data, encompassing logs, metrics, and events from numerous sources, crafting a holistic comprehension of the digital systems' layout. These tools' fundamental capability to identify patterns and outliers indicating potential problems allows technical teams to stay ahead and proactively tackle these hiccups.
Machine learning, a vital component of AI, mines, learns from, and adapts based on historical data to improve future predictions - enhancing its potential to identify patterns and trends, possibly overlooked by human analysts. For instance, ML provides forecasts for possible server irregularities based on past system behaviour, preparing preventive steps that technical squads can employ.
Parallel Review of Traditional and AI/ML-based Digital System Surveillance Techniques
Maximizing AI and ML for Future Digital System Inspections
AI and ML can significantly amplify the process of inspecting digital systems in several ways:
- Anomaly Detection: AI and ML probe data to detect discrepancies, leading to potential problems, aiding technical teams to tackle these hindrances proactively.
- Prescriptive Forecasting: Machine learning modules utilize past data to predict potential hitches, enabling technicians to foresee server glitches and malfunctions.
- Automated Central Issue Evaluation: AI streamlines the complex and time-investing task of pinpointing the main issue by autonomously examining data from various sources.
- Resource Calculation: By studying past data, AI and ML can project future resource requirements, assisting enterprises in better planning and effectively steering clear of resource deficits.
The Way Forward - AI and ML in Digital System Inspections
Although the integration of AI and ML in digital system oversight is still an emerging trend, the prospective benefits are extremely promising. The future growth of these technologies will allow businesses to proactively monitor their digital networks, minimize system downtime and augment operational performance.
To sum up, AI and ML serve as robust allies in enhancing digital system oversight. These ground-breaking technologies' capabilities to automate regular workloads, recognize patterns, predict future predicaments, and deliver significant insights empower businesses to manage their digital operations proactively and maintain relentless business endeavors.
Importance of Regular Audits in Infrastructure Monitoring
Monitoring any tracking system in an organization calls for an in-depth examination process known as an audit. Judging the effectiveness of your tracking systems, highlighting potential security gaps, and ensuring conformance to industry norms and laws form integral segments of this vital process.
Audits: An Essential Strategy in Infrastructure Tracking Management
A three-pronged approach outlines the significance of audits within the workings of infrastructure tracking. Auditing primarily undertakes the role of investigating the effectiveness of the tracking systems, ensuring they fulfill their intended functions of detecting and resolving emerging problems promptly. This includes verifying that alerts are triggered accurately, data records are maintained, and identified issues are addressed.
Secondly, the audit process uncovers potential security lapses within the framework. It brings to light any areas where the tracking systems are unable to thoroughly investigate or any existing systems are inadequate in preventing possible threats. Recognizing these loopholes paves the way for enhancing your tracking systems and strengthening your security defenses.
Lastly, audits ensure adherence to industry norms and legal obligations. The importance of this aspect cannot be overstated in sectors such as healthcare and finance, where any deviation from mandatory regulations can result in substantial fines.
Executing Infrastructure Monitoring Audit
To carry out an infrastructure monitoring audit effectively requires a series of essential steps,
- Assessment of Tracking Systems: An in-depth review of your tracking systems is required, focusing on the data gathered, methods of analysis, and trigger-response of alerts.
- Identification of Vulnerabilities: The focus here is on spotting areas where your monitoring systems might be overlooking things or existing systems are unable to fend off potential threats sufficiently.
- Conformance Check: This step verifies that your tracking systems conform to industry norms and legal requirements.
- Proposals for Improvement: Depending on what the audit uncovers, suggestions are provided to elevate your monitoring systems. These may include the introduction of new systems or technologies, adjustments to existing systems, or changes to the present monitoring approach.
Why Regular Audit is Beneficial
Conducting frequent audits offer several noteworthy benefits. They assure your monitoring systems align to their designated objectives, preventing potential problems from growing into serious complications. They also help in exposing vulnerabilities, facilitating the implementation of pre-emptive security precautions. Moreover, they ensure the organization meets the industry's norms and legal demands, which steers clear from the risk of potential fines and helps maintain the company's reputation.
In conclusion, regular audits are an irreplaceable aspect of a fruitful infrastructure monitoring strategy. Regular audits enable evaluations of your monitoring systems, reveal potential loopholes and assure adherence to industry norms and legal mandates.
Infrastructure Monitoring for Cloud Environments
In the business landscape, incorporating emerging technologies with cloud platforms is becoming increasingly prevalent. The advantage is a cloud-centric strategy comes from the blend of remote data warehousing and easily accessible touchpoints, pushing businesses to a whole new level. However, such adaptations come with challenges, which necessitate constant examination of the cloud layout. This paper, therefore, digs into the importance of persistent cloud server surveillance, the entailment of such surveillance, and strategies for its effective management.
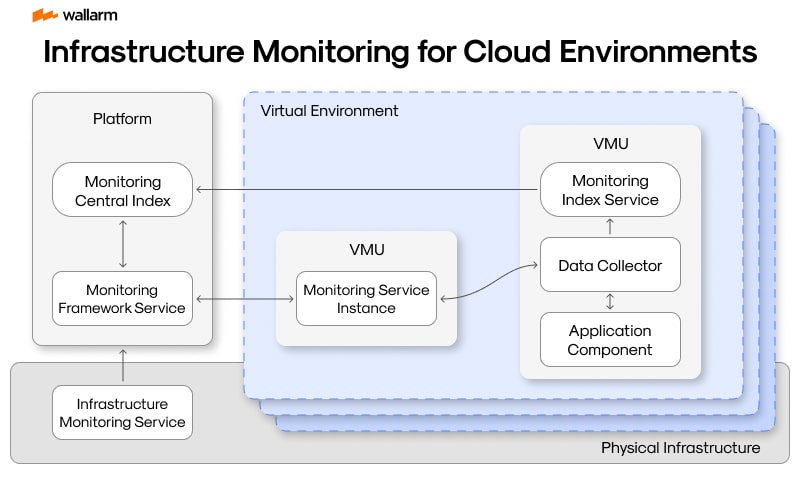
Requisite Observance in the Cloud Environment
The functioning of cloud-tailored apps and services is of utmost significance to companies as a lapse in oversight can imperil not only smooth functioning and constant access to data but also the crucial confidentiality of data.
The pulse points of observing the cloud include:
- Tuning Resource Consumption: Administrating how resources are apportioned within a cloud environment aids the understanding of peak usage periods, which in turn helps boost efficiency and cut costs.
- Timely Problem Resolution: Proactive monitoring systems equip businesses to predict potential problems, thereby averting the amplification of security or operational issues.
- Amplifying Security Strategies: Regular checks on the network can spot inconsistencies or threats, which allows for quicker security reactions.
- Compliance Adherence: In-depth monitoring enables businesses to adhere to stringent data privacy and safety regulations.
Obstacles in Uninterrupted Cloud Monitoring
Here are a few road bumps that can be expected on the path to constant cloud surveillance:
- Complexity: The intricate layout of the cloud environment calls for undivided attention and poses significant challenges due to its vast array of services and resources.
- Restricted Control: Traditional wired networks offer complete control, a luxury forfeited in cloud platforms.
- Integration Hurdles: Combining surveillance solutions and cloud services can be a herculean task, especially when numerous cloud vendors are involved.
Successful Strategies for Cloud Supervision
To tackle these obstacles, consider the following:
- Tailor-made Monitoring Solutions: Tools designed considering specific business needs offer superior integration and clarity.
- Task Automation: Automation reduces the strain on IT personnel while freeing their time for strategic endeavors.
- Detailed Network Assessment: Care should be taken to evaluate every layer of the cloud platform, including the app layer.
- Instant Alert Mechanisms: A swift alert system speeds up damage control, thereby reducing extended service disruptions or downtimes.
Picking an Apt Tool for Cloud Monitoring
Cloud surveillance tools, each with its unique positives and negatives, have a wide variety on offer. A decision based on factors such as the preferred cloud architecture, user-friendliness, and lucidity can be beneficial.
Prominent tools consist of:
- Amazon CloudWatch: Designed exclusively for Amazon Web Services (AWS), CloudWatch diligently manages different applications and AWS resources.
- Google Stackdriver: Notable for its monitoring and logging capabilities, Stackdriver is suitable for both Google Cloud and AWS configurations.
- Microsoft Azure Monitor: Azure Monitor caters to all surveillance requirements within Azure networks, covering various strata from infrastructure to applications.
In Conclusion
In conclusion, ongoing surveillance of cloud environments is indispensable for maintaining a resilient, secure, and efficient cloud framework. Acknowledging its relevance, the associated hindrances, and operational strategies can pave the way for flawless execution of cloud operations.
Conclusion: The Vital Role of Infrastructure Monitoring for Business Success
Digital evolutions have revolutionized the commercial landscape, with IT surveillance acting as the key linchpin in these shifts. It serves as the heartbeat of a company's tech ecosystem, keeping every component functioning. Its essential service to ensuring top-notch productivity, soaring efficiency, and burgeoning profitability cannot be understated.
Unleashing Business Efficiency
IT surveillance is a business tool like no other for achieving peak productivity. It vigilantly monitors the performance levels of various IT elements. The strategy of anticipating and addressing issues before they snowball is invaluable, guaranteeing uninterrupted operation of systems and invigorating productivity.
Boosting Operation Effectiveness
IT surveillance function brings the performance of IT assets into scrutiny, enhancing business operational effectiveness. It delivers real-time performance metrics that aid in smart resource distribution decisions. This optimization of resources sidesteps misuse and catalyzes the success of all operations.
Impact on Revenue Generation
The influence of IT surveillance on a company's bottom line is unquestionable. It slims down operating costs by warding off extended system downtime, propelling efficiency, and ensuring prudent resource utilization. When all systems function in synchrony, customer satisfaction rises, resulting in an inevitable upsurge in revenue.
Essential for Risk Mitigation
IT surveillance shines in the realm of risk management. Undertaking regular IT checks, it signals to businesses about impending dangers and vulnerabilities. Early risk mitigation strategies can be implemented, thereby ensuring essential data and systems are safe from possible security breaches.
Role in Ensuring Regulatory Compliance
In a landscape where strict regulatory scrutiny is the norm, compliance is a tricky hurdle. IT surveillance lends a clear vision of the business's technology environment. This clear picture is instrumental in showcasing compliance with the required norms, thereby bypassing severe penalties and preserving the organization's reputation.
Future Outlook
Algorithm-driven technologies, such as AI and machine learning, are set to enhance the importance of IT surveillance even further. They will refine IT surveillance by enabling predictive analysis and proactive measures.
In essence, IT surveillance guarantees the smooth functioning of all tech operations, taking a company's productivity, efficiency, and profitability to new heights. It also serves to fend off risks and ensure regulatory compatibility, providing businesses a shield against both threats and penalties. Its significance is poised to magnify in the coming years, cementing its position as an invaluable asset for every business.
FAQ
References
Subscribe for the latest news