Data Masking
Keeping data safe is the first priority of businesses around the world. Organizations adopt various methods to protect the data and this list includes data masking best practices. The technique is said to drive impressive results.
A technique to safeguard crucial data from intrusion, data masking keeps data safe and secured. If you want to adopt it for your organization or needs, we have covered all details related to the subject in this write-up. So, read, understand and implement it for your good.

What is Data Masking?
It functions the same way as a person hiding his identity or face using a face mask in real life. Data security experts fabricate a dummy version of actual data while following this cybersecurity strategy. As it hides the real data value, it’s often known as data obfuscation.
Structure-wise, the fake version is almost identical to actual data. But, it doesn't feature any mission-critical details. This version is placed at the front of a real database to fool the hackers. Even if a hacker manages to hack this version, no important information will be compromised.
This way, critical data remained protected. Not only is this method useful for data protection, but it also helps in creating result-driven employee training programs and performing extensive system performance tests.
Why is it Preferred?
Data masking, when done correctly, can be of great significance and bring a lot to the table. Here is why every security-concerned organization should invest in it:
Reason #1: With data masking, it’s easy to keep sensitive data/information safe from dangers: like data theft, data filtration, data manipulation, and many more. All these threats hold the potential to corrupt the crucial data and cause severe operational, financial, and reputational loss to the impacted businesses.
Reason #2: Employee training and software testing are essential for an organization. However, performing these two actions with useful data is not a wise decision as it puts the growth-focused data at risk. Data masking is an easy way to create a database that matches a lot with the actual database but comprises no important information.
Reason #3: Fooling hackers is easy with data masking. While they invest effort and energy in the hacking masked database, the owner organization/individual can move the crucial data to a safer destination.
Types of data masking
- Static
It involves creating a sanitized version of actual data. Very commonly used in the industry, the process starts with generating a backup version of data at work or in production, uploading it to a different ecosystem, removing all the unwanted information, and finally doing masking of the data. The final output, i.e. a masked version of data, is then forwarded to the intended destination.
- Dynamic
It’s an on-demand solution. Masked data is directly/dynamically pushed/sent to the production unit allowing the dev/test ecosystem to use it. It is used during the run-time and is highly attribute-based. Also, a set of pre-designed policies are driving dynamic data masking.
- On the fly
This technique is useful for businesses that perform software testing extensively. Using this technique, such organizations can make the data flow into the testing platforms, as soon as it is produces, in the form of a small masked data set. This data delivery happens as and when required.
- Deterministic
A less secure version of data masking, it requires replacing one data string/set with another. For instance, ‘Wallarm for Cybersecurity’ will always be replaced with ‘API Safety Platform’ in a data stream.
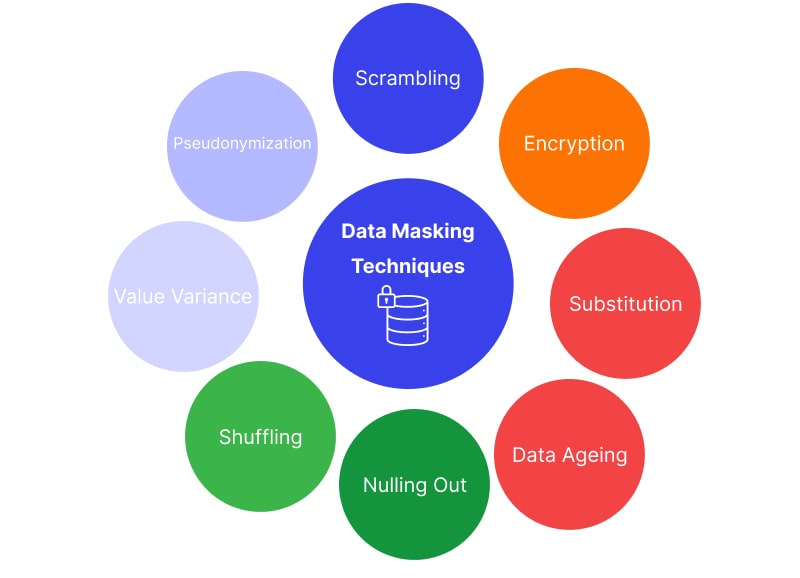
Masking techniques
As you are aware of types of data masking now, let’s talk about how it is done practically. Common methods, organizations use presently for it, are:
- Scrambling
As the name suggests, it refers to data juggling or scrambling. For instance, ‘code’ can be jumbled with ‘dice’ in the database everywhere.
It’s easy and less secure.
Think of the scenario where ‘dice’ is already present in the raw data. During processing, it will be replaced with ‘code’, which is incorrect. So, it’s applicable in certain scenarios only because jumbling may make the data inconsistent.
- Encryption
In this method, an algorithm is created to work upon the database in order to make the data inaccessible. It’s complex and demands high-end understanding, but also, most secure and advanced.
If you are confused about data masking vs encryption, think of the former as a method that works fine for static & dynamic datasets. On the contrary, the latter changes the actual value of data, so it is more suitable for static data or data at rest.
- Substitution
To secure the organizational data, its values are exchanged with fake values to misguide the hacker or unauthorized users.
- Nulling Out
It is, kind of, the last resort for a business when other methods didn’t work. Mostly, the purpose of this nulling out maintains integrity of the database. It’s also known as deletion. No data value is displayed when the unauthorized user accesses a sensitive database.
- Shuffling
Data values are not replaced but shuffled with another data value, residing in the same database.
- Value Variance
It shares its working methodology with substitution masking, but in actual, its processing and output are very different. In this technique, raw data is replaced using the functions, not directly with another value.
- Pseudonymization
It is adopted to ensure that no data value is used/usable for identification. Mostly, it involves deleting direct identifiers or preventing adding various identifiers that will make identification easy.
- Data Ageing
Mostly used for numeric data, data averaging involved replacing the data with the average of that specific column.
Data masking problems
Despite the effectiveness of the method in cybersecurity deployment, we have seen many organizations hesitate in adopting it. The reason being is the complexities involved. Here are the key problems that one might face during data masking implementation:
- Original data must be protected well through the process against threats and distortion. If that’s not happening, organizations will end up harming the data on their own.
- When data replacement is happening, the process should be aware of gender preservation. For instance, John Mill, a male, should be replaced by a male name only. It shouldn’t be replaced with Sofia Smiths, which is a female name. Such rules can simplify the interpretation of the data later on.
- During the data masking, data uniqueness must persevere. A unique data value should be replaced by unique dummy data. A non-unique dummy data value that matches with another dummy value or a value in main data set will add inconsistency to the final masked dataset.
Recommendations for data masking
When you’re trying to adopt data masking into practice then keep in mind it’s you who adopt the best data masking standards. Here are data masking best practices to follow.
- Data discovery has to be perfect; it lays the foundation for success in the entire process. During the data discovery, you have to make sure that the assorted information is categorized properly. Exhaustive record maintenance should be done.
- Data surveillance, for the presence of any security loopholes, must be done. Anyone who is responsible for data surveillance must be aware of best data overseeing practices and keep a watch over the places where sensitive data is stored and managed. Also, it’s important that separate surveillance and concealing approaches should be adopted for the different datasets. Unified solutions for diverse datasets cause hassles.
- When you’re adopting data masking in a large organization, it’s important to use a mix and match of techniques. The single technique isn’t very much viable. So, try bringing multiple strategies into action.
- Data veiling processes should be tested before they are implemented. It reduces the odds of failure. During the testing, the team must check out whether or not the implemented process can drive the expected results. In case the technique is not meeting the predetermined expectations, restoring the original database should be the priority.
- Protecting the algorithm that creates masked data is non-negotiable while one is using data masking. When the masking algorithm is protected, only authorized personnel are able to access data. Also, when the used algorithm is protected, it's impossible for hackers to trace which technique is used and find its alternative.
Wallarm Data Security: What must you know
Data masking is a breeze with the help of the Wallarm data security platform. With its advanced solutions such as Cloud WAF and API Security Platform, Wallarm assists an organization to bring various data masking techniques into action, preventing unauthorized access, and safeguarding at data-at-rest and in-transit with the same perfection.
Both the solutions, Cloud WAF and API Security Platform, are utterly advanced and capable of early threat detection. The accuracy is unquestionable. To know more about the capabilities of these two solutions, availing a demo is the best bet. They have a team of AppSec security experts that will design a data masking program as per your organizational requirements. Try it once and you’ll be able to learn about its utility.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")