Understanding Data Anonymization: Techniques, Benefits, and Future Directions
Data anonymization encompasses a range of techniques aimed at safeguarding sensitive information by preventing its association with specific individuals. These methods include approaches like data obfuscation, pseudonym replacement, data aggregation, randomization, generalization, and data swapping.
This handbook explores these various techniques, examining their advantages and limitations, the difficulties encountered during execution, and areas requiring further investigation. It concludes by introducing a new strategy to protect personal privacy, adhere to legal requirements, build trust with customers, and ensure confidentiality.


What is Data Anonymization?
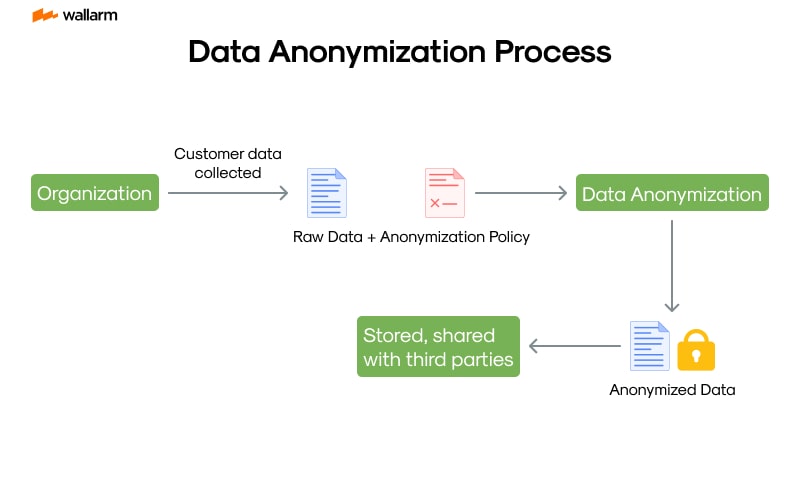
Data anonymization refers to the process of removing or masking personal details from datasets to ensure individual privacy. By anonymizing the information, it ensures that it cannot be linked to any specific person, while still permitting its use for legitimate activities like software development, analytical studies, and other authorized functions.
This method alters confidential data to disconnect it from any individual, thereby lowering the chances of re-identifying someone. The main goal is to adhere to privacy regulations and strengthen security protocols.
The process of anonymizing data generally involves methods such as masking, which hides personal markers like addresses, phone numbers, passport numbers, and Social Security IDs. This is usually achieved by replacing or removing identifying elements through encryption or applying random alterations to maintain the dataset's overall structure.
Although anonymizing data lowers the likelihood of identifying individuals, it does not guarantee full anonymity. Re-identification risks remain, particularly if anonymized data is compared with publicly available sources. As a result, data teams must thoroughly evaluate the risks and limitations of their anonymization approaches when handling sensitive or private information.
Risks Associated with Re-identification
When evaluating de-identification techniques, it's important to consider the strategies used, technological advancements, and the three key risks that must be addressed:
- Isolation Risk: This refers to the potential of extracting one or more records that could identify an individual within a dataset.
- Connection Risk: This involves the ability to associate multiple records related to the same individual or group across different datasets. If an attacker can link records without pinpointing a specific individual, the anonymization technique may protect against isolation but not against connection.
- Deduction Risk: This pertains to the ability to infer an individual’s attributes with high accuracy by analyzing a set of other available data.
A successful anonymization approach must tackle all these issues, making sure that no one can single out an individual, link data across different sources, or infer confidential details. Reaching this level of protection can be difficult, particularly when factoring in the power of contemporary "big data" technologies.
Methods for Data Anonymization

In general, two primary methods are used to anonymize data:
- Randomization Techniques: These methods modify the data's accuracy to break the direct connection between the data and individuals. By introducing uncertainty, the data can no longer be reliably linked to a specific person. While randomization may not reduce the uniqueness of each record, as each one still originates from a single individual, it can help guard against deduction-based risks. To improve privacy, randomization can be combined with generalization techniques. Common randomization methods include:
- Adding noise
- Shuffling data
- Differential privacy
- Broadening Methods: This technique involves expanding or simplifying data attributes by modifying their scope or range (for example, substituting a specific city with a larger region or replacing an exact week with a broader month). Although broadening helps reduce the risk of pinpointing individual records, it may not fully prevent all forms of re-identification. It often necessitates intricate mathematical approaches to ensure both privacy and security against potential linkage or inference risks. Broadening methods include:
- Data aggregation
- K-anonymity
- L-diversity
- T-closeness
Typically, relying on a single technique from either category is not enough to fully anonymize a dataset; combining different methods is often necessary.
How Data Anonymization Safeguards Personal Privacy
Data anonymization is essential in maintaining personal privacy by preventing unauthorized exposure and misuse of sensitive data. As the volume of data being gathered and stored continues to rise, the likelihood that personal details could be accessed or exploited without an individual’s consent grows significantly.
When personal information is compromised, it not only represents a security failure for the organization, but more critically, it erodes customer trust. Such breaches can result in severe privacy infringements, including contract violations, discrimination, and identity theft.
By masking or removing personally identifiable details from datasets, data anonymization significantly reduces the chances of unauthorized parties gaining access to or exploiting sensitive information. Beyond safeguarding privacy and upholding individual rights, anonymization helps businesses comply with various data protection laws, such as APPI, CPRA, DCIA, GDPR, HIPAA, PDP, SOX, and others, which require organizations to implement security measures to protect personal data.
Furthermore, even after data is anonymized, it remains valuable for analysis, generating business insights, supporting decision-making, and conducting research—without ever compromising personal privacy.
The Growing Demand for Data Anonymization
The primary reason for the widespread adoption of data anonymization is the expanding amount of data being gathered and stored by organizations, along with the rising demand to safeguard the privacy of individuals associated with that data.
As the data-driven economy rapidly expands, companies are gathering an ever-growing amount of personal information from diverse sources such as e-commerce platforms, governmental bodies, healthcare systems, and social media channels. This continuously expanding pool of data offers enormous opportunities for analysis and application.
As the data economy rapidly grows, the need for strong privacy protections is escalating. With increasing public concern over privacy and greater pressure to implement stricter safeguards, data masking has become widely accepted. This technique enables data to be utilized in valid contexts, like research and product innovation, while ensuring the privacy of individuals is preserved.
As AI and machine learning continue to evolve, vast datasets are becoming essential for training models and exchanging knowledge across various sectors. Data anonymization is key to reducing privacy concerns by stripping personal details from data, making it virtually impossible to trace back to individuals.
Additionally, with the expansion and tightening of global data protection regulations, companies face growing pressure to implement systems that secure their customers' private and sensitive information. In this environment, data anonymization provides an essential tool for meeting legal requirements and preserving consumer trust.
Emerging trends in data sharing, including decentralized data platforms and federated learning, underscore the increasing need for privacy-enhancing techniques like anonymization. These strategies enable businesses to work together safely, preventing the disclosure of confidential data, promoting creativity, and ensuring adherence to privacy regulations.
Understanding the Types of Data Anonymization
Absolute Anonymity
Absolute anonymity, often referred to as 'genuine anonymity', is the process of totally eradicating any traceable details in a data set. It's an irreversible task that leaves no possibility of linking the anonymised data back to the original source, even if additional data comes into play. Organizations often utilize this form of anonymity in situations that don’t require the individual's identity, such as statistical research.
While offering excellent data security, absolute anonymity presents certain challenges. The procedure is intricate and demands substantial time investment, plus once the data is entirely anonymous, it cannot be reverted. Hence, this data won’t be retrievable for any future requirements.
Semi Anonymity
Semi anonymity involves selectively modifying or deleting some traceable details within a data set, such as replacing associate names with pseudo names or vague timeframes in place of precise dates. The intent behind semi-anonymization is to alleviate the identification risk whilst still preserving the functional value of the data.
Real-life applications of semi-anonymity often happen where some identifiable data is indispensable, but not all. For instance, in a health-associated study, the investigators might require details like the participant's age and gender, but not their address or names.
Semi anonymity, although not as secure as absolute anonymity, provides a compromise solution between data preservation and data utility. Nonetheless, there's an inherent risk of individual identification, particularly when the anonymised data is merged with other data sources.
Pseudo Identification
Pseudo Identification is a subset of semi-anonymization which replaces personal details with fabricated identifiers, also known as pseudonyms. Valuable for securing privacy where data needs to be linked within multiple data sets, allowing data to be unlinked and then re-linked when necessary , it becomes a pliable solution for businesses with multifaceted data usage needs.
However, pseudo-identification comes with its own setbacks. While it doesn't provide security comparable to absolute anonymity, it does expose a potential risk of traceability if the pseudonyms can be connected back to the original data.
Data Concealment
Data concealment is a method that isolates certain data segments while allowing other segments to remain evident. This can be executed through procedures like character shuffling, substitution, and encoding. Data concealment is commonly applied in situations where data is needed for debugging or developmental purposes while ensuring crucial data remains unexposed.
Despite being an effective strategy for protecting essential data, data concealment isn't true anonymity. The root data is still intact, just obscured, posing a risk of exposure if the concealed data is decrypted.
Random Noise Injection
Random noise injection is the practice of incorporating random data, or 'static', into a data set, thereby concealing the original data. Particularly helpful when the data has to be publicized or shared, it can complicate the individual data point identification process.
However, this technique comes with its own disadvantages. Introducing static into the data can compromise its precision and practicality. Also, there is an inherent risk that the original data can be recovered if the static is eliminated.
In essence, data anonymization is multifaceted, with each technique offering specific advantages and bearing unique risks. The most suitable technique for an organization's needs will depend on its particular circumstances. Therefore, it is crucial to understand not only the different methods of data anonymization but to evaluate the benefits and potential risks before arriving at the right technique.
Pseudonymization Explained
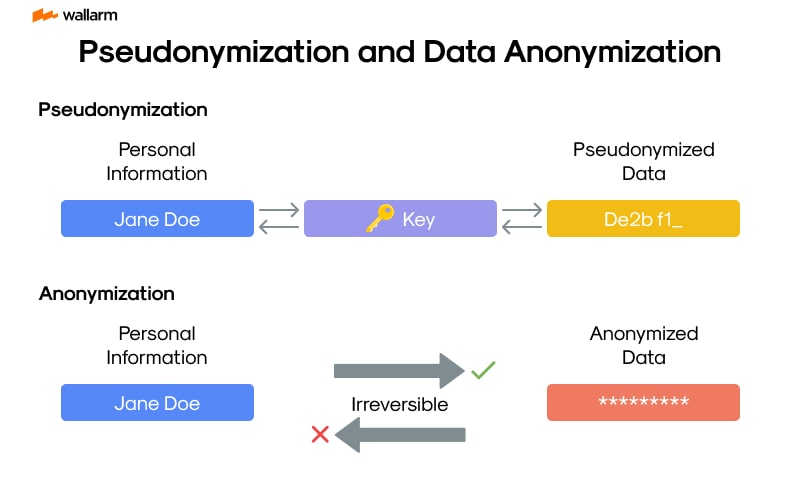
Pseudonymization is a technique that enhances privacy by making data neither fully anonymous nor easily traceable to an individual. It works by replacing direct identifiers in the dataset with alternative identifiers, known as pseudonyms, which disconnect the data from the original identity of a person. Without access to the mapping that links pseudonyms to real identities, it becomes impossible to identify the individual in question. This mapping is usually stored separately and not shared with those handling the data.
While pseudonymized data is not fully anonymous, as it can be re-identified using the reverse mapping, it ensures that individuals cannot be easily recognized without specific access to that information.
To ensure pseudonymization is effective, a sufficient number of direct identifiers must be substituted with pseudonyms, making it impossible for anyone—whether the data controller or an external party—to identify an individual using "any reasonable methods that could be applied."
Mitigating the Risk of Re-identification
When assessing "all methods that are likely to be used," it is crucial to take into account the particular pseudonymization technique applied, the prevailing technological environment, and the three key risks outlined below:
- Isolating Records: Despite pseudonymization, it may still be possible to isolate specific records as individuals remain linked to unique attributes introduced by the pseudonymization process (i.e., the pseudonymized attribute).
- Establishing Links: The connection between records may remain straightforward when the same pseudonymized attribute is used for a single individual. Even if different pseudonyms are assigned to the same person, linkability could still occur through other attributes. Full elimination of cross-referencing between datasets using different pseudonyms only happens if no other identifiers exist in the dataset and if all connections to the original data are removed, including through deletion.
- Making Inferences: Inference risks arise when an attacker can deduce the real identity of an individual from the dataset or from other databases that share the same pseudonymized attribute, or when pseudonyms are not sufficiently obfuscating the original identity of the individual.
Pseudonymization alone is typically inadequate to fully anonymize a dataset. In many cases, it remains just as easy to identify an individual in a pseudonymized dataset as in the original one. Additional precautions—such as removing or generalizing attributes, or deleting original data, or at least reducing it to a highly aggregated state—must be implemented to ensure a dataset is anonymized.
Common Techniques for Pseudonymization
Several methods are commonly used for pseudonymizing data:
- Encryption with a Secret Key: This approach involves encrypting personal data, making it unreadable without the corresponding decryption key. If someone possesses the key, they can easily reverse the process to identify individuals. Only those with the correct key can decrypt the data, assuming strong encryption is in place.
- Hashing: Hash functions generate a fixed-size output from an input of any size (which can be a single attribute or multiple attributes). This process is irreversible, so unlike encryption, there is no direct way to reverse the function. However, if the range of input values is known, it may be possible to generate the original value by applying the hash function to every possible input. Brute force attacks and precomputed hash tables can also facilitate this process, though using a salted hash function (where a random value is added to the attribute) can improve security, though it may still be vulnerable to sophisticated attacks.
- Keyed-Hash Function with Stored Key: This technique involves using a secret key in combination with a hash function. While the hash function can be replayed by those who have the key, without the key, it’s practically impossible for an attacker to reverse the process, as the number of potential combinations is large.
- Deterministic Encryption or Keyed-Hash Function with Key Removal: This approach assigns a random identifier as a pseudonym to each data element and deletes the reference table that connects the pseudonym to the original data. This minimizes the likelihood of associating personal information across multiple datasets. Without access to the decryption key, it becomes practically impossible for an attacker to reverse-engineer the encryption or hashing process.
- Tokenization: Commonly used in industries such as finance, tokenization replaces sensitive data (like credit card numbers) with non-sensitive values that have little value to a potential attacker. It typically relies on one-way encryption or the assignment of random identifiers that are not directly related to the original data.
Advantages and Disadvantages of Data Anonymization
Here is an overview of the benefits and drawbacks of data anonymization:
Advantages
- Makes it difficult, or nearly impossible, to identify individuals within a dataset
- Facilitates lawful data sharing for purposes like research and analysis
- Supports easier and faster compliance with data protection regulations
- Prevents unauthorized access to sensitive personal data
- Reduces the chance of mistakes, such as improper data linkage
- Cuts down on costs by allowing consent-free data reuse and eliminating the need for secure storage
Disadvantages
- May decrease the value of data by altering or removing essential personal details
- Poses a risk of re-identification if attackers can merge data with other available sources
- Can demand specialized skills and tools, increasing complexity and costs
- Does not guarantee complete privacy if re-identification is successful
- May not be effective for highly sensitive or uniquely identifiable data
- Can be time-consuming, resource-demanding, and challenging to scale
Strengths and Weaknesses of Various Techniques
Different techniques come with varying levels of effectiveness in addressing the key concerns of data protection, including the risks of singling out, linkability, and inference. Here's a breakdown of how each method fares:
- Anonymization Techniques:
- Noise Addition: This method still carries a risk of singling out and linkability, but it's less likely to enable inference.
- Permutation: While it still has some risk of singling out, it poses less risk for linkability and inference.
- Differential Privacy: It minimizes both the risk of singling out and linkability, and also reduces the possibility of inference.
- Aggregation and K-anonymity: These methods eliminate the risk of singling out but still leave linkability and inference as potential concerns.
- L-diversity and T-closeness: These techniques prevent singling out, but linkability remains a concern, while inference risk is reduced.
- Pseudonymization: Pseudonymization carries risks in all three categories—singling out, linkability, and inference—making it less secure compared to anonymization techniques.
Best Practices for Reducing Data Subject Identification Risks
To effectively reduce the likelihood of re-identifying individuals, it is important to adopt the following key practices:
General Guidelines
- Avoid adopting a “release and forget” mindset when handling data. Due to the potential for residual identification risks, data controllers should consistently:
- Regularly identify new risks and reassess any remaining risks that could lead to identification.
- Evaluate whether existing protective measures are adequate and make necessary adjustments as needed.
- Continuously monitor and manage these risks to ensure ongoing protection.
Additionally, it’s important to consider the identification risk posed by any non-anonymized data in a dataset, particularly when it is combined with anonymized elements. Special attention should also be given to the potential correlations between different data points, such as linking geographic location with income levels or other identifiable attributes, as these can inadvertently increase the risk of re-identification.
Key Contextual Factors
The intended goals for utilizing the anonymized data must be explicitly outlined, as these objectives significantly influence the risk of identifying individuals.
This is closely tied to evaluating various contextual factors, such as the characteristics of the original data, the security measures in place (including controls to limit access to the data), the sample size (quantitative aspects), the availability of public datasets that might be accessed by users, and how data might be shared with third parties (whether access is restricted, open to the public, or provided under specific conditions).
It's also important to consider potential threats by assessing the attractiveness of the data for malicious actors. The sensitivity and nature of the data will be crucial in evaluating the risk of targeted attacks.
Technical Considerations
Data controllers should clearly state the anonymization or pseudonymization methods they are using, particularly if they intend to release the anonymized dataset.
Uncommon or semi-identifiable attributes, often referred to as quasi-identifiers, should be eliminated from the dataset to reduce risks.
If randomization techniques like noise addition are used, the level of noise applied should be proportionate to the value of the attribute being protected. The noise should be appropriate to the data's scale, considering the impact on the data subjects and the density of the dataset.
When utilizing differential privacy methods, it's important to track queries carefully to identify potentially intrusive ones, as the risk accumulates with each query.
For generalization methods, data controllers must avoid using a single criterion for generalizing attributes, even for the same attribute. They should select varied levels of granularity, such as different geographical regions or time frames. The selection of the generalization technique should depend on how attribute values are distributed across the population, as not every dataset is suitable for uniform generalization. To preserve diversity within equivalence groups, a defined threshold must be established based on contextual elements, such as sample size. If the threshold is not met, the sample should be excluded or a different generalization approach should be applied.
Data Anonymization Use Cases Across Different Sectors
Here’s an overview of how data anonymization is applied in various industries:
Retail and E-commerce
Retailers and online marketplaces use data anonymization to protect customers' personal details while still allowing them to leverage data for improving services, market analysis, and consumer insights. By anonymizing purchase history, customer preferences, and transaction data, businesses can generate insights into trends and behaviors without exposing sensitive information.
For example, anonymized data can be used to analyze shopping patterns, optimize inventory management, or personalize marketing efforts without revealing individual customer identities. It also guarantees adherence to privacy laws like the General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA), which safeguard consumer rights and personal privacy.
Education
Educational institutions and e-learning platforms use data anonymization to protect student information, such as grades, attendance records, and personal details. This ensures privacy while still facilitating meaningful research, performance assessment, and reporting.
For instance, anonymized data can be used to study student performance trends, assess the impact of educational programs, or evaluate the effectiveness of different teaching methods. It also aids in compliance with regulations such as the Family Educational Rights and Privacy Act (FERPA), which safeguards student information.
Manufacturing
In the manufacturing sector, companies apply data anonymization to protect sensitive operational data while still allowing for the optimization of production processes, supply chain management, and quality control. Anonymized production data, sensor readings, and operational logs help identify efficiency improvements and reduce costs without revealing proprietary or personal information.
For example, data anonymization can be used to monitor equipment performance, predict maintenance needs, or improve resource allocation while protecting the identity of factory workers or confidential production methods. It ensures compliance with industry standards and data protection laws.
Transport and Logistics
Transportation companies and logistics firms use data anonymization to safeguard personal details such as driver information, route data, and package delivery records. This allows for the analysis of operational data to enhance service quality, optimize routes, and improve fleet management, all while ensuring privacy.
For example, anonymized data can be used to analyze traffic patterns, assess delivery times, or optimize fuel usage without exposing driver identities or sensitive company data. It adheres to data protection laws such as the GDPR and CCPA, ensuring the safeguarding of individuals' privacy and confidentiality.
By de-identifying sensitive or personal data, businesses in these fields can gain valuable insights, reduce privacy concerns, and comply with data privacy regulations.
Key Obstacles in Data Anonymization
There are several significant hurdles to effective data anonymization, including:
Preventing Re-identification
Even with comprehensive efforts to anonymize data, the risk of re-associating the data with specific individuals remains.
One of the main methods for uncovering identities is through linkage attacks, where anonymized data is cross-referenced with publicly accessible records. For example, an attacker could combine anonymized financial details with information from public voter databases to identify individuals.
Another approach to re-identification is through inference attacks, where attributes like age, gender, or location are used to make educated guesses about a person’s identity. An example of this would be cross-referencing browsing activity with geographical data to deduce who an individual is.
The challenge of re-identification has evolved with technological advancements. Modern machine learning algorithms are now capable of detecting patterns within anonymized datasets. Additionally, sophisticated data mining techniques and linkage methods allow attackers to merge various datasets more easily, increasing the likelihood of re-identifying anonymized data.
Finding the Optimal Balance Between Privacy and Data Usability
Achieving the right balance between maintaining privacy and ensuring the usability of data is a significant challenge in anonymization efforts. A risk-based strategy is essential in aligning the degree of data anonymization with the potential risks tied to the data.
For instance, sensitive medical records typically require a more rigorous level of anonymization compared to less sensitive demographic data. Additional techniques, such as differential privacy or the application of AI/ML-driven generative models (like GANs), are often employed to strike this balance, enhancing both data privacy and its analytical value.
Establishing Global Guidelines and Regulations
As the value of data grows for businesses and research, the need for robust and uniform oversight of data anonymization practices has become increasingly critical. Various standards and regulations for data anonymization are currently in place, each with its advantages and limitations.
For example, although the GDPR provides robust protection for personal data, it can make data sharing for business and research purposes more difficult. A potential solution to these issues is the development of a standardized approach to data anonymization that ensures personal data protection while offering the adaptability to accommodate various data types, legal requirements, and real-world use cases.
Leveraging AI and ML in Data Anonymization
The integration of Artificial Intelligence (AI) and Machine Learning (ML) presents a notable challenge in data anonymization. A popular method involves incorporating AI/ML tools into the anonymization workflow, such as utilizing AI-powered algorithms to identify personally identifiable information (PII) or using Generative Adversarial Networks (GANs) to generate synthetic datasets that maintain the statistical properties of the original data while removing confidential information.
Looking ahead, AI and ML could also play a role in the process of de-anonymization, which includes methods for re-identifying individuals or linking anonymized data back to its original source. Given the potential risks to privacy, AI/ML could assist in identifying weaknesses in anonymization methods and provide solutions to strengthen data protection.
Advancements in Data Anonymization: Future Directions
Future studies in the field of data anonymization could focus on several key areas to enhance its effectiveness and applicability:
- Developing Advanced Techniques: Research could lead to the creation of more secure and robust methods, such as homomorphic encryption, which enables sensitive data to be analyzed without revealing its content in an unprotected form.
- Improving Performance and Scalability: A key focus would be on optimizing anonymization methods to handle large and complex datasets efficiently, ensuring that privacy protections do not slow down data processing.
- Integrating AI and ML: Further research could explore how AI and machine learning models, including generative models and clustering techniques, can be utilized to group similar data points and apply privacy-preserving methods to each cluster, enhancing data anonymization at scale.
- Balancing Privacy with Data Utility: Efforts will likely concentrate on improving the balance between preserving privacy and maintaining the usefulness of the data, ensuring that anonymized datasets are still valuable for analysis.
- Exploring Blockchain Technology: Blockchain’s decentralized, tamper-resistant ledger could be examined as a tool for secure data sharing, ensuring that data integrity is maintained while still protecting privacy.
- Federated Learning Collaboration: Research could look into federated learning models that allow collaboration across different sectors without requiring the sharing of raw data, ensuring privacy while enabling shared insights.
- Applying Differential Privacy to Time-Series Data: There is a need for research on how differential privacy techniques can be adapted for time-series data, especially when there are temporal dependencies between data points, ensuring privacy without compromising the accuracy of the data over time.
- New Approaches for Cross-Industry Data Privacy: Future studies could explore novel privacy-preserving methods that enable safe and efficient data sharing across industries, allowing organizations to collaborate without exposing sensitive information.
Data Anonymization for Business Organizations
Entity-based data masking technology enables organizations to anonymize data more efficiently and effectively. This method consolidates and organizes fragmented data from various source systems into structured data schemas, where each schema is associated with a specific business entity (such as a customer, supplier, or transaction).
The process anonymizes data linked to individual business entities, managing it in a dedicated, encrypted Micro-Database™ that is either stored securely or kept in memory for quick access. This approach ensures that both the relational integrity and semantic accuracy of the anonymized data are preserved.
Companies specializing in data anonymization that offer integrated test data management, data masking, and tokenization software on a unified platform help reduce implementation time and overall operational costs, providing a faster return on investment and lower total cost of ownership.
Conclusion
With the increasing pressure from data privacy regulations, organizations are compelled to anonymize sensitive data related to key business entities such as customers, suppliers, transactions, and invoices.
This document explored the concept of data anonymization, emphasizing its importance and necessity in today's data-driven world. It provided an overview of different types of anonymization, techniques used, real-world applications, challenges faced, and ongoing research efforts in this domain.
The paper concluded by highlighting a business entity-based approach to data anonymization, which offers exceptional performance, scalability, and cost-efficiency. This approach not only addresses compliance requirements but also streamlines data management, ensuring that businesses can protect sensitive information without sacrificing operational effectiveness.
Additional Insights:
- Future advancements in anonymization methods, particularly those leveraging AI and machine learning, could further enhance the accuracy and speed of data de-identification processes.
- Integrating privacy-preserving techniques across industries will help create a unified approach to safeguarding personal and sensitive data.
- Companies can achieve both compliance and operational optimization by adopting an entity-based approach, which allows for seamless integration and minimal disruption to their data workflows.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")