Buffer Overflow Attack: Preventing and mitigation methods. Part 2
Beginning of article a previous post
Detecting buffer overwriting vulnerabilities is extremely critical and valuable. However, their removal from codes requires regular recognition as well as understanding secure buffer practices. The most feasible and easiest way to detect vulnerabilities is to use languages that do not allow them to be used. Language like C programming allows for such vulnerabilities through direct access to memory spaces and the lack of strong object types. Languages that do not share these symptoms are usually immune. Java, Python, and .NET, among other languages and platforms, do not require special checks or changes to mitigate overflow vulnerabilities.

Of course, it is not always possible to completely change the language of development. In this case, use safe practices to handle buffers. Regarding wire handling functions, there is a lot of debate about the available methods that are safe to use and should be avoided.
Where an unsafe feature deserves an open option, not everything is lost. During compilation and execution, progress is being made in detecting these vulnerabilities. When running a program, compilers often generate random values called canaries and place them on the stack after each buffer. Like so-called coal mining birds, these canary values are a threat. By comparing the canary value with the original value, it is possible to determine whether there is a buffer overflow. If you change the value, the program may stop or go into error mode instead of continuing with the return address which may have changed.
Some operating systems today provide additional protection in the form of non-executable batches and address space layout (ASLR) randomization. Non-executable batches (i.e., Data Execution Prevention (DEP)) mark steel and, in some cases, other structures as areas where code cannot be executed. This means that an attacker cannot exploit the code that can be used on the stack and cannot expect it to run successfully.
Sometimes the vulnerability cracks through the cracks and remains under attack despite controls in place at the development, compiler, or operating system level. Sometimes successful cultivation can be the first sign of buffer overflow. In this case, two critical tasks need to be performed. You need to first identify the vulnerability and change the base of the code to resolve the issue. Secondly, we will aim to replace all vulnerable versions of the code with the new enhanced version. Ideally, this starts with an automatic update that reaches all Internet-connected systems running the software.
However, it cannot be assumed that such an update will provide adequate coverage. The software may be used by organizations or individuals on systems with limited Internet access. These cases require a manual update. This means that news about the update should be distributed to any administrator who may be using the software, and the patch should be readily available for download. The creation and distribution of the patch should be as close as possible to the detection of vulnerability. Therefore, minimizing the vulnerable time of users and systems.
Secure buffer management features, as well as compiler security features and appropriate operating systems, provide robust protection against buffer overflow. Despite these steps, consistent identification of these errors is a key step in preventing exploitation. Comb lines of the source code after a buffer overflow can be tedious. In addition, there is always the possibility that the human eye can sometimes miss something.
Address Space Layout Randomization (ASLR)
Memory corruption vulnerabilities occur when a program incorrectly writes attacker-controlled data outside the intended memory area or the intended memory scope. This could destroy the program or, even worse, give the attacker complete control over the system. Memory corruption vulnerabilities have plagued software for years, even though big companies like Apple, Google, and Microsoft are working to eliminate it.
Because these errors are difficult to detect and can only compromise the system, security professionals have designed error protection mechanisms to prevent software exploitation and limit damage when a memory corruption error is exploited. The “money ball” would be a mechanism that makes exploitation so trivial and unreliable that the faulty code remains in place, giving developers the years they need to fix or rewrite the code in memory-safe languages. Unfortunately, nothing is perfect, but Launch Layout Randomization (ASLR) is one of the best buffers available.
Address Space Layout Randomization (ASLR) is a memory protection measure for OS that secures buffer overflow attacks by haphazardly choosing where framework executable records are put away in memory. ASLR random memory addresses tend to imply that the malicious actor no longer realizes which address the necessary code, (for example, ROP capacities or modules) is found. In this way, rather than eliminating the vulnerability from the framework, ASLR tries to take on a more prominent challenge to misuse existing vulnerabilities.
The success of many cyber-attacks, especially zero benefits, is based on the hacker’s ability to know or figure out the state of the processes and functions contained in memory. ASLR can place address spaces in unpredictable locations. If an attacker tries to exploit the wrong address space, the target application crashes, stops the attack, and alerts the system.
The Pax Project created ASLR as a Linux patch in 2001 and has been integrated with the Windows operating system since 2007, starting with Vista. Before ASLR, file and application memory locations were known or easily identifiable.
When ASLR was added to Vista the number of potential address space locations increased to 256, meaning that attackers had only a 1/256 chance of finding the right place to execute the code.
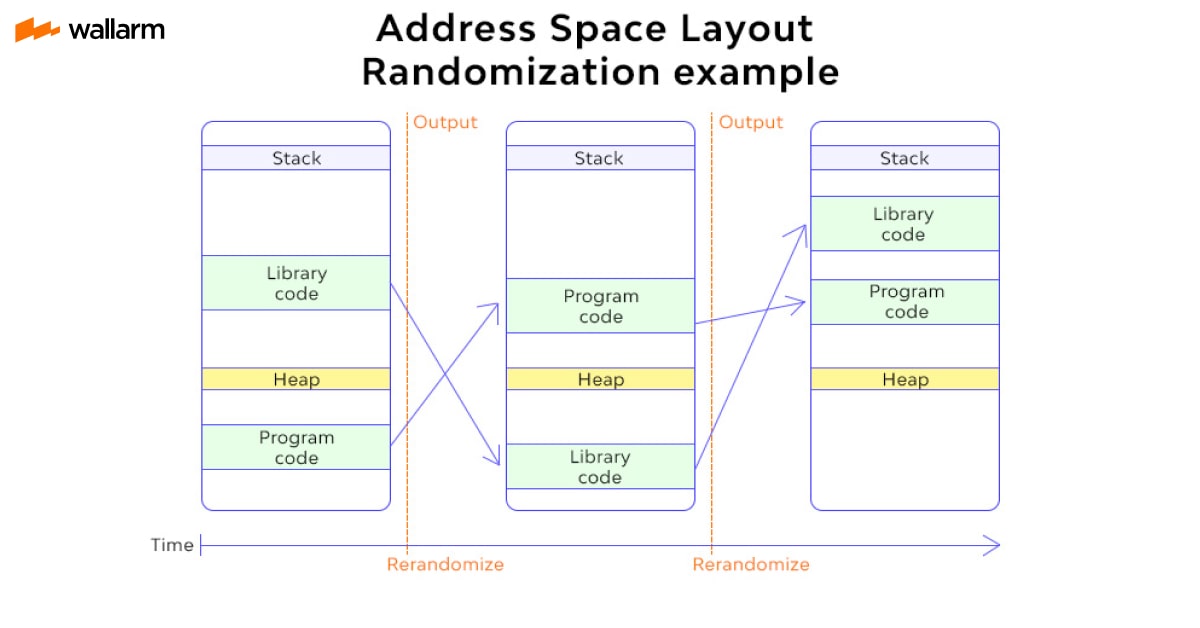
How ASLR Works:
ASLR works by breaking down assumptions that developers might otherwise make about where programs and directories are located in memory at runtime. A common example of this is the location of the modules used in Return Oriented Registration (ROP), which are often used to breach Data Execution Prevention (DEP) protection. ASLR confuses the address space of a vulnerable process - the main program, dynamic directories, stacking and pile, files mapped to memory, and so on - so the payload must be customized despite the address space of the victim process at the time sin. Write a worm that blindly sends memory addresses and hardware encoded memory addresses to every machine it finds. As far as the ASLR target process is enabled, the exploited memory deviations are different from those selected by ASLR. This is not pursued, but the fragile program fell.
Shortcoming Of ASLR
By randomizing the layout of the address space, the default addresses of DLLs are based on the randomness of the startup. In practice, this means that the basic addresses of the directories are randomized on the next reboot. This is an Achilles heel that can be exploited by attackers, by combining vulnerabilities such as memory exposure or brute force attacks.
The purpose of address space randomization is to prevent an attack from reliably reaching the target memory address. The ASLR does not focus on capturing the attack but on making the attack unlikely. Once the shell jumps to the wrong address during cultivation (due to memory randomization), the behavior of the program is not defined. The process could lead to an exception, an accident, jam, or inconsistent behavior.
Forensic intelligence on assault, exploitation, and shellcode is essential for any serious forensic investigation. Exploited processes, memory areas, and call rounds can be used to identify exploitation, fingerprinting, and tagging. The ASLR cannot provide this information because it does not know if an attack is taking place or when it was stopped.
Since randomizing the layout of the address space into the Windows operating system, real benefits and attacks have been bypassed. Attackers are constantly developing new techniques to repel ASLR defenses. Bypass techniques include the use of the ROP chain in non-ASLR modules (e.g. CVE 2013-1347), JIT / NOP spraying (e.g., CVE-2013-3346), and memory exposure vulnerabilities and other techniques.
Data Execution Prevention:
The easiest way to prevent vulnerabilities that could exploit buffer overflows is for programmers to keep their code secure. This is not an automated process, it requires a lot of work to revise the code to ensure the code integrity of the program, and as the number of lines of code increases, so does the time required. Realistically, we need other forms of protection. To do this, Microsoft has created a feature called Data Execution Prevention (DEP).
Data Execution Prevention (DEP) is a security feature that helps prevent damage to your computer from viruses and other security threats. Malicious programs can attempt to attack the operating system by attempting to run code (also known as execution) from system memory locations reserved for OS and other authorized programs. These types of attacks can damage programs and files.
DEP can help protect your computer by monitoring programs to make sure they are using system memory safely. If DEP detects a program on your computer that is using memory incorrectly, it closes the program and notifies you.
DEP is available in both hardware-based and software-based configurations.
- Hardware-Based DEP:
The use of hardware-based DEP is considered to be the safest implementation of DEP. In this application, the processor marks all memory locations as "non-executable" unless the site already contains explicit executable code. DEP’s goal is to try to run code in non-executable fields.
The main problem with using hardware-based DEP is that it only supports a minimum number of processes. The processor function that allows this is called the NX service on AMD processors and the XD service on Intel processors.
- Software Bases DEP
If a hardware-based DEP is not available, a software-based DEP should be used. This form of DEP is built into the Windows operating system. Software-based DEP works by detecting the exceptions that a program raises and ensuring that those exceptions are valid parts of the program before it is allowed to proceed.
Structured Exception Handling Overwrite Protection (SEHOP)
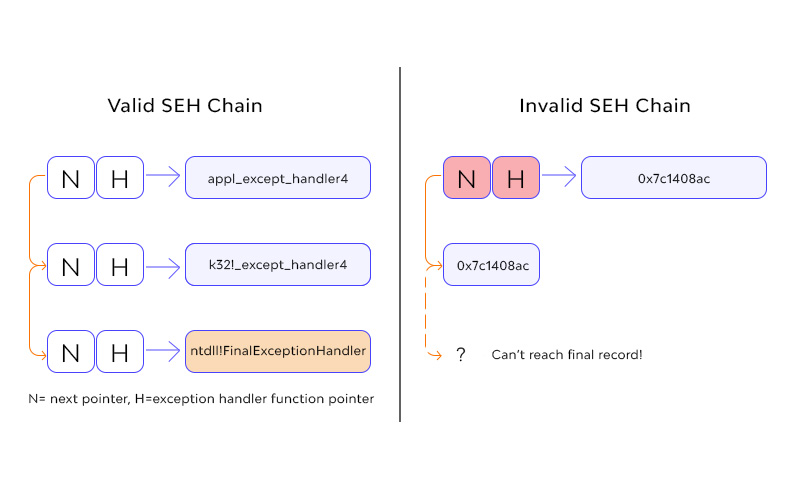
Structural Exception Handling (SEHOP) Anti-Transcription Protection prevents abuse through the Structural Exceptions Override strategy, which is a typical buffer overflow attack. The reason for modifying SEHOP is to prevent malicious actors from using the Structural Exceptions Management (SEH) abuse procedure. This exploitation method was distributed by David Litchfield, NGS Software in September 2003. Since its distribution, the SEH guarantee method has become a standard weapon in the Army Arsenal. About 20% of the latest form of the Metasploit system uses the SEH encryption innovation. SEH breach investigations are often used to increase the number of browser-based vulnerabilities.
SEH encryption technology exploits software vulnerabilities to execute arbitrary code by taking advantage of Windows' 32-bit exceptional sending capabilities. On a practical level, SEH is typically compensated by using steel-based buffer overflows to overcome the exception recording record stored in the threaded steel.
Mitigating SEHOP:
Two general approaches can be considered when mitigating the SEHOP technique. The first approach is to change the reverse version of the code so that the executable files contain metadata that the platform should modify according to the technique. Microsoft followed this approach and released a functional buffer with Visual Studio 2003. This buffer was in the form of a new contact flag called SAFESEH. Unfortunately, due to the need to rebuild executable files and the inability to fully handle cases when the exceptional handler points outside the image file, the SafeSEH approach is less attractive.
The second approach involves adding dynamic controls to the exceptional sender that does not rely on the possession of binary metadata. SEHOP uses this approach. At a high level, SEHOP prevents attackers from using the SEH breach technique before verifying that the list of thread exception handlers is secure before invoking registered exception handlers. This mitigation technique was feasible due to the implied side effect of SEH violation. When the vast majority of the steel-based buffer overflow occurs, the attacker implicitly records the next pointer in the exception registration record before the pointer overrides the pointer exception override function. Because the next pointer is corrupted, the integrity of the exception handler chain is broken. This insight, together with the ASLR, will enable SEHOP to effectively mitigate SEH violations.
Other techniques to prevent or mitigate buffer overflow attacks and vulnerabilities include:
- Writing secure code: The best way to prevent vulnerabilities that can cause buffer overflows is to write secure code. When writing programs in languages that are exposed to buffer overflow vulnerabilities, developers need to be aware of risk factors and avoid them where possible. For example, avoid finding and using features like seizures, which allow the developer to determine how many buffers would be expected. While this is the best way to avoid buffer overflow, it can be difficult to change legacy applications and applications that only work on legacy operating systems. Because of these challenges, we may have to rely on other protections offered by compilers and operating systems.
- Making use of compiler warnings: When developing new software with vulnerable features, translators often warn and recommend that safe alternative to the features used to be used. Developers can make these changes quickly during the development phase.
- Stack canaries: As stack-based buffer overflows became very popular, compilers introduced new ways to protect important data in the stack, such as folding addresses. These canaries are random values that are generated each time the program is run; they are stacked and usually checked just before they return to call functions. If there is a stacked overflow and the canary is overwritten with user-specified input, program execution stops and an error occurs.
It’s been almost 20 years since the day came over with a buffer, and some safeguards are in place that prevents them from working as well as they did then. Some of these protections include stacked canaries, address space layout randomization (ASLR), compiler warnings, and hardware changes that prevent code from running on the stack.
First, the best protection against stack-based overflow attacks is to use secure encryption practices - in particular by stopping the use of features that allow unlimited memory access and thorough calculation of utilization to attackers. Prevent modifying adjacent values in memory. Simply put, if attackers only have access to the memory of the variable they are trying to change, they cannot influence code execution beyond the expectations of the developer and the architect.
Unfortunately, there are thousands of programs that have implemented insecure, unlimited functions to access memory, and it is not possible to encrypt all of them according to secure encryption practices. Operating system manufacturers have implemented a number of mitigations for these old programs to prevent bad coding practices that result in arbitrary code execution. At the beginning of software development, however, protection is the best solution to protect and mitigate buffer overflow attacks.
The term buffer overflow is thrown around very loosely, but it is a more serious threat to the security of the system than almost any other type of threat. Eventually, the attackers will follow this bait and switch, allowing the systems to operate. These attacks progress a few steps faster than what good people can follow.
FAQ
References
Subscribe for the latest news

.png "AWS with Wallarm")