What is a Buffer Overflow Attack? ⚔️ Types, Examples. Part 1
A buffer is a space of physical storage memory used to store temporary data while moving from one place to another. These buffers usually reside in RAM. Computers often use buffers to improve performance; most modern hard drives use the benefits of buffering to access data efficiently, and many online application services also use buffers. For example, buffers are often used during online video streaming to prevent interference. When a video is streamed, the video player simultaneously downloads and stores 20% of the video in a buffer and then streams from that buffer. Therefore, a small reduction in connection speed or rapid service interruption does not affect the performance of the video streaming.

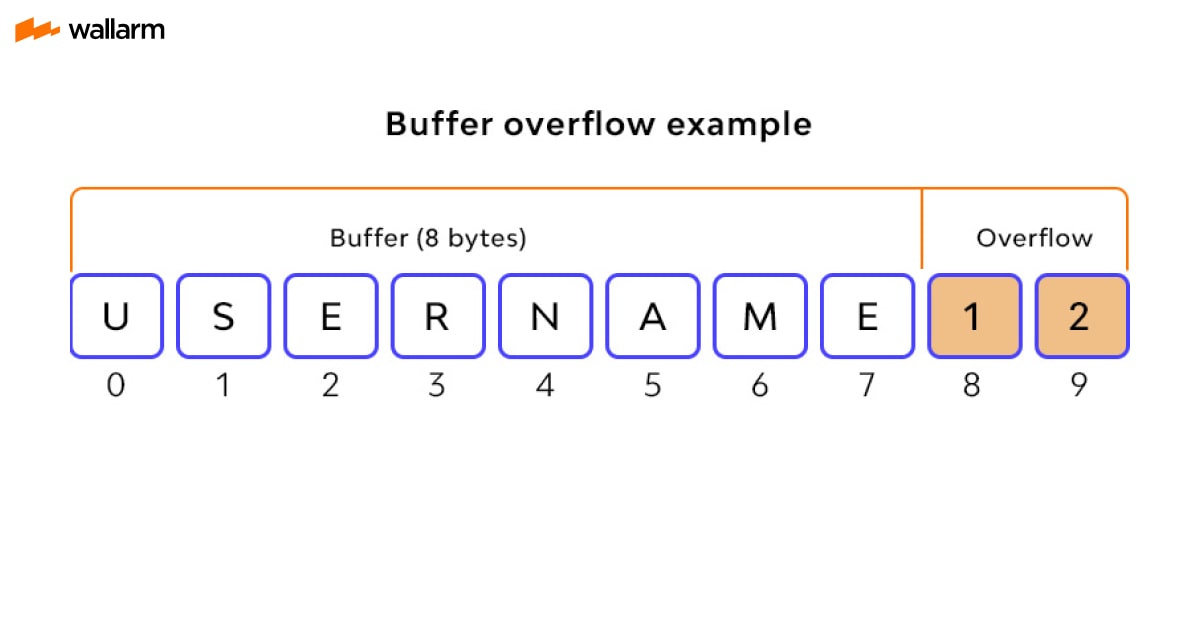
However, buffers contain a certain amount of data that limits it to hold limited data for a limited time as multiple application uses this mechanism of the buffer. Resultantly a situation arrives when further data is pushed into a buffer, such a condition refers to a term called a buffer overflow. It is a flaw that arises when software that writes data to a buffer surpasses the buffer capacity, resulting in overwriting of neighboring memory locations. That is, too much information is transmitted to a repository that does not have enough space, and this information is gradually replaced by neighboring repository data.
Buffer overflows can affect all types of software. These are usually informal inputs or failure to assign sufficient space for the buffer. If the transaction violates the executable code, the program can perform variably and result in false results, memory access location errors, or crashes.
For example, a buffer for login data can be configured to require an 8-byte username and password to be entered, so if a transaction contains 10 bytes (i.e., 2 bytes more than expected) input, the program can write down excess data over the buffer limit.
How do attackers exploit buffer overflows?
A malicious actor can carefully load custom input into a program, initiating the application to try to store the input in a buffer that is not large enough and overwrite the related portions of the memory. If the memory buffer of the program is definite, a hacker may knowingly overwrite spaces that are identified to hold executable code. An attacker could then change this piece of code with its executable piece of code, which could significantly change the way program works.
For instance, if the rewritten part of the memory holds a pointer (an object pointing to another location in the memory), the attacker's code could replace the code that points to the payload. This can shift the control of the entire program to the attacker's code.
Buffer overflow can occur in web application server services providing static and dynamic web structures, or in the application itself. Users of these products are considered to be at high risk due to extensive knowledge of buffer overflows in often server products. The use of archives in various web applications, such as graphics, to generate images increases the potential risk of buffers overflowing.
Buffer overflow can be created in the code of individual web applications, and more are expected because web application scanning is not normal. Buffer overflow errors are less common in some web applications as far fewer malicious actors try to capture and exploit such errors in a particular application. When a particular application detects it, the ability to exploit the error is greatly minimized because the source code of the application and its error messages are not usually available to the hacker.
Who is vulnerable to buffer overflow attacks?
Vulnerabilities of the buffer are overwhelmed in programming languages like C, trade security for efficiency, and do not control memory access. In high-level programming languages like Python, PHP, Perl, Java, or JavaScript which are often used to build Web applications, there should be no buffer overflow attack negligence. You cannot put unnecessary data in the target buffer in these programming languages.
Even programmers who use high-level languages need to be aware of buffer attacks and pay special attention to them. Their programs typically run on operating systems written in C or use a runtime environment with C, and this C code may be vulnerable to such attacks.
The latest operating systems have runtime protection to prevent buffer overflow attacks. However, almost all known Web servers, application servers, and application environments are at risk from buffer overflows, except for environments designed to interpret languages such as Java or Python that are immune to these attacks (except interpreters).
Some coding languages are more sensitive to buffer overflows than others. C and C ++ are two common languages with high vulnerabilities because they do not include built-in protection against access or overwriting of memory data. Code is written in one or both of these languages in Windows, Mac OSX, and Linux. More modern languages like Java, PERL, and C# have built-in features that help reduce the chances of buffer overflow but cannot prevent it altogether.
Types of Buffer Overflow Attack:
Many different buffer overflow attacks use different strategies and target different pieces of code. Below are the best-known buffer overflow attacks:
- Stack overflow attack - This is the most common type of buffer overflow attack and involves buffer overflow in the call stack.
- Heap overflow attack - This type of attack targets data in the open memory pool known as the heap.
- Integer overflow attack - When an integer overflows, an arithmetic operation results in an integer (integer) that is too large to store the integer type; this may result in a buffer overflow.
- Unicode overflow - Unicode overflow creates a buffer overflow by inserting Unicode characters into the expected input of ASCII characters. (ASCII and Unicode encoding standards that allow computers to display text. For example, the ASCII number 97 stands for the letter “a.” Although ASCII codes only cover Western language characters, Unicode is the world in which characters can be created. in almost any written language. If more other characters are available in Unicode, many Unicode characters are larger than most ASCII characters.
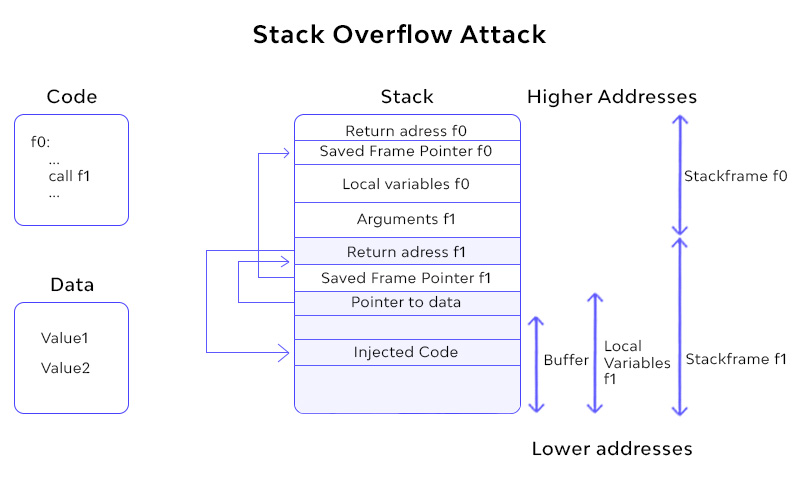
Stack Overflow Attack:
The stack is a LIFO (Last In First Out) data structure. It supports two operations: PUSH and POP. The PUSH operation is used to specify the value of the steel, and the POP operation is used to extract the value of the steel. If the data placed on the stack is corrupted, they will overwrite the adjacent memory location and affect the data or pointer already stored by the other program. Steel overflow is an old vulnerability that uses stacked memory that only exists during runtime. The vulnerability is usually in C or C ++ because we are free to use the pointer in those languages. An attacker or hacker could take advantage of this vulnerability to exploit the system by manipulating data or creating a pointer to run malicious code.
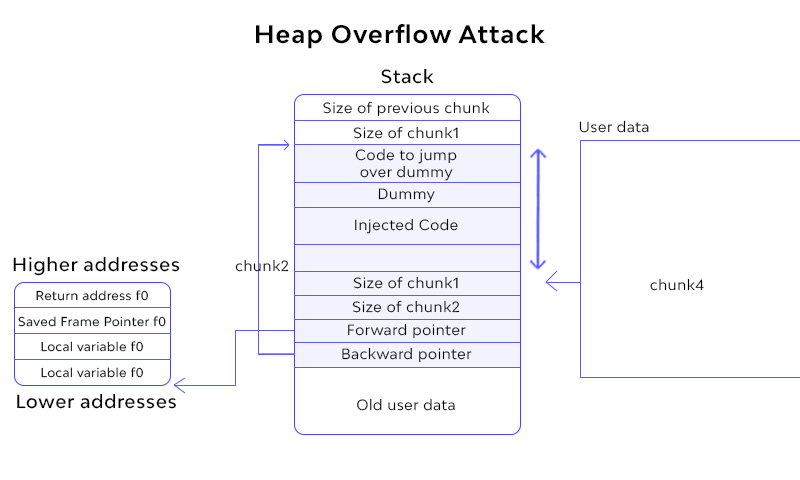
Heap Overflow Attack:
The heap overflow occurs when a piece of memory is assigned to the heap and the data is written to that memory without the data being checked. This may result in some critical data structures in the heap, such as heap headers, or any heap-based data, such as dynamic object pointers, which can overwrite the virtual function table.
Integer Overflow Attack:
Integer overflow is a type of arithmetic overflow error where the result of an integer operation does not lie in the allocated memory space. Instead of a program error, it usually results in an unexpected result. In most programming languages, integer values usually have a certain number of bits in memory.
For example, the space reserved for a 32 - bit integer data type may be an unsigned integer between 0 and 4,294,967,295, or a signed integer between −2,147,483,648 and 2,147,483,647. However, what happens if you calculate 4,294,967,295 + 1 and try to store the result that exceeds the maximum value for the whole type? Because most languages and most compilers make no mistakes at all and only perform a modulo, accept, or truncate operation, it only crashes and puts you at risk of attack.
Most integer overflow conditions simply lead to erroneous program behavior but do not cause any vulnerabilities. However, in some cases, integer overflows may have severe consequences like manipulating financial calculation, causing a customer to receive debit instead of credit or something alike.
Unicode Overflow:
Unicode strings have been created to ensure that all languages from any country can be used without transcription problems. For example, Arabic characters are different from English characters. He realized that such characters could not be converted according to the ASCII codes we know. Any character can be used with Unicode strings. And the Unicode schema allows the user to take advantage of the program by typing Unicode characters in input that expects ASCII characters. It simply provides input that surpasses the maximum limit to make a buffer overflow with uncertain characters of Unicode where the program is expecting ASCII input.
Continued in the second part
FAQ
References
Subscribe for the latest news