See Wallarm's AI Control Platform In Action
Namespace in Kubernetes
In previous installments of this series, various Kube objects such as Pods, Placements, and Services were established on a Cluster without any structure. These items will increase rapidly in size and complexity if you keep doing what you're doing. So, it is appropriate to offer an idea that will lessen this impact now. Kube NAMESPACE functions as a digital cluster for arranging and classifying K8s items for streamlined operations and streamlined project management.
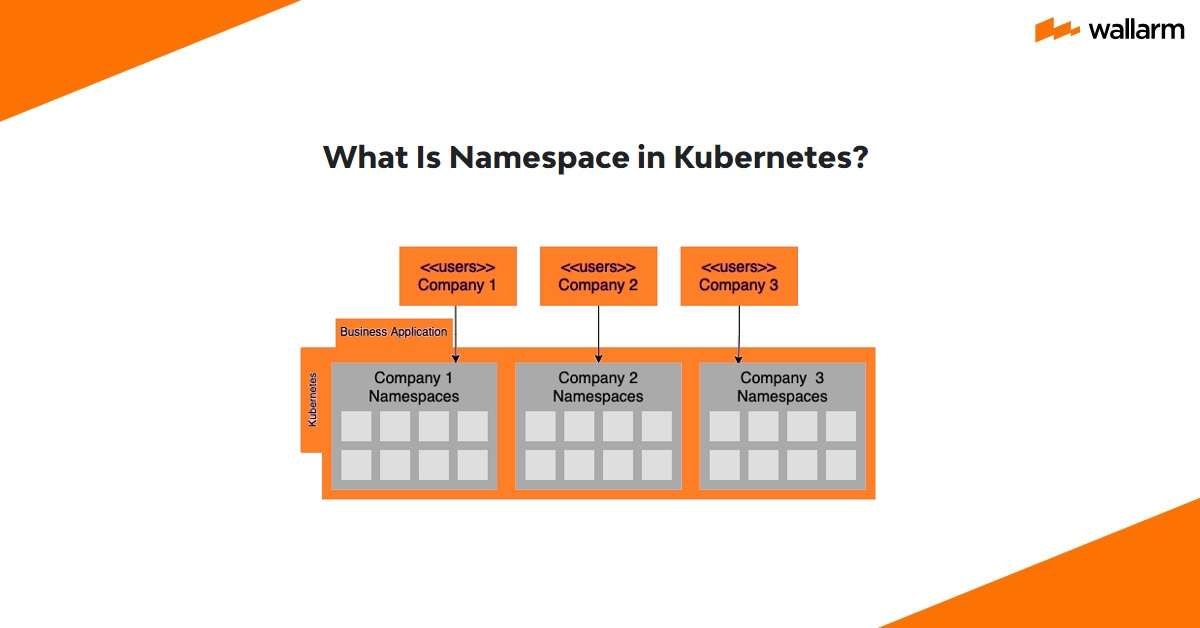
What Is Kubernetes Namespace?
If multiple groups or projects need to share the same K8s cluster, then using namespaces to divide the cluster into virtual sub-clusters is a good idea. A cluster can have an arbitrary number of namespaces, which are rationally independent of one another but are nonetheless able to exchange data with one another. It is not imaginable to nest namespaces within each other.
Any K8s resource can be found in either the system-wide default schema or a user-created namespace. There are no resources lower than bulges and tenacious storage volumes outside of the function, and these are always reachable to all namespaces in the bunch.
Why Use the Kubernetes Namespace?
K8s namespaces can be used for a wide variety of purposes, such as:
- Teams and projects can now have their own isolated virtual clusters without interfering with one other.
- Restricting users and processes to certain namespaces is a great way to improve role-based access controls.
- Allowing different teams and users to share a cluster's resources within predetermined limits.
- Containers make it possible to run the full application lifecycle on a single cluster, from creation to testing to deployment, without disrupting the workflow at any stage.
Default Namespace in Kubernetes
By presets, kubernetes create namespace which provides access to three separate functions. This list includes:
- Presets: As the title suggests, this is the namespace that is addressed by default for every Kubernetes operation and where every Kubernetes resource is stored by definition. It is the preset namespace that the entire cluster uses unless additional schemas are made.
- Kube-system: This term is used for Kubernetes components and should be avoided.
- Kube-public: For use with public properties. Definitely not something you should try out on your own.
When Should I Use Multiple Kubernetes Namespaces?
The default namespace may be adequate for use by smaller groups or companies. Because there is no requirement to keep developers and users apart, this becomes very important. Having numerous namespaces, however, has many practical advantages.
- Isolation: Schemas are a great way for large or expanding teams to separate their various projects and microservices. It is not a problem for teams to utilize the same resource names across several workstations. Virtual desktops are completely isolated from one another, and actions taken on items in one workstation never propagate to the others.
- Organization: Entities that utilize a combined collection for all segments of evolution, coding, and presentation can use schemas to detach settings for experimenting and creating new things from live data. Using distinct schemas for each stage of the program lifecycle keeps production code safe from modifications made by innovators and coders.
- Authorizations: Using a set of signs, teams may leverage Kube RBAC to construct characters that compile sets of consents and/or capabilities into more manageable chunks. This helps limit access to a schema’s resource to those with consent to use them.
- Data Supervision: It can have CPU and storage usage capped according to policy. That way, you can ensure that no single schema is using up all the system help while different schemes struggle to get by.
- Effectiveness: If a grouping makes use of KN, its performance may enhance. The K8s API will have fewer entries to search through if a nest is divided into plentiful schemas for distinct tasks. This has the potential to enhance the functioning of all applications sharing the collection by lowering latency and increasing throughput.
Basic Kubectl Commands That Relate to The Unique Identifier
- Creating and deleting name scope
To make a new schema, just type the below code:
Namespace creation with kubectl
The creation of such an identifier is just another K8s resource that may be done with a YAML file:
newspace.yaml:
And with the command “kubectl delete namespaces,” the schemas are erased.
Due to the asynchronous nature of the deletion sequence, the Kubernetes delete namespace and
will be marked as "terminating" until it is successfully removed.
- Creating, listing, and deleting resources inside unique identifier
You can ensure that your command is run within the relevant prerequisites by using the filesystem flag, even if the context that is currently being used does not imply that this is the case.
- The first thing you need to do is create a new application within the test domain.
- You are able to instruct the system on where the deployment and any associated data or pods should be located by using the metadata section of the Kubernetes namespace yaml file.
- Get all of the pods that are associated with the test namenode, such as: $ kubectl get pods --namespace=test
- To get an extensive listing of all chaincode pods: $ kubectl get pods --all-namespaces
- Unique Identifier and Resource Quotas
You may ensure that the cluster's resources are divided up in the manner that was anticipated by applying Resource Quotas to a schema. Whatever schema you choose can be used to define an object that acts as a resource limit. As just one illustration, this manifest will put a cap on the amount of processing power that the demo can use.
After the quota has been formed, the above requirements and limits will be applied on each and every pod that is generated and is operating within the demo name scope. Once a predetermined quantity of pods has been produced using the demo schemas, there will be no more pods available for production.
Benefits of Kubernetes Namespaces
Although making and maintaining namespaces is a difficult operation, it has many advantages. Advantages include, but are not limited to:
- Effectiveness and Optimization
This is the single greatest benefit of using a namespace. People can focus on their own tasks and coordinate with one another as needed. It makes the entire development process easier to control and more flexible, leading to greater productivity.
- Simple Allocation of Means
Kubernetes set namespace, simplifying the process of allocating resources to multiple containers and pods. The operator may see how many resources are needed at any given time, and how many more are needed if those resources are being used optimally. Moreover, it monitors the microservices' decommissioning timestamp and reassigns the associated resources whenever the service is turned off.
- Crisis Management
When problems or anomalies arise in a system, namespaces can help pinpoint where the issue originated and why it occurred. This facilitates quicker and more accurate diagnosis, mitigation, and resolution by the operators.
- Enhanced Mobility
As necessary, operators and cluster administrators can quickly and easily increase or decrease the system's resources. This occurs because namespaces function as virtual containers. When the need for a resource outstrips the available supply, an additional namespace can be purchased for a small charge to accommodate the growing demand. Scaling the system has minimal impact on current operations.
FAQ
Subscribe for the latest news





















































.jpeg)


