See Wallarm's AI Control Platform In Action
etcd Explained: The Database at the Core of Kubernetes
In today’s cloud-native world, distributed systems are the backbone of modern applications. These systems are designed to scale, self-heal, and operate across multiple nodes and environments. But with this complexity comes a critical need: a reliable way to store and manage configuration data, service discovery information, and cluster state. This is where etcd becomes essential. It is not just another key-value store—it is the heartbeat of many cloud-native platforms, especially Kubernetes. Understanding why etcd matters in modern cloud systems requires a deep dive into its role, reliability, and how it supports the very fabric of distributed computing.

What is etcd? A Beginner-Friendly Definition
etcd Core Principles and Architecture
etcd is engineered to act as a fault-tolerant, consistency-focused, minimalistic key-value registry distributed across a cluster of machines. Unlike general-purpose databases, it’s streamlined for real-time coordination tasks in distributed systems, particularly for synchronizing states and sharing lightweight configuration elements.
Data within etcd is structured as key-value pairs, supporting string and JSON formats. These entries are regularly accessed and updated by nodes in a system that demands agreement on the exact values at any given time. Performance is optimized for numerous small transactions rather than handling bulk or complex datasets.
All write operations in etcd are routed through a cluster-elected leader node, which guarantees consistency by sequentially applying changes through the Raft consensus protocol. This governance model means any write operation must be acknowledged by a quorum before it’s committed, preventing divergent data states and ensuring strong consistency.
Nodes form clusters with odd numbers to simplify consensus resolution. If the leader fails or becomes unreachable, the remaining healthy members autonomously vote to appoint a new one without interrupting service continuity.
Data Structure and Keyspace Organization
The storage framework uses a single-layer keyspace where key naming mimics directory nesting through slash separators. Internally, there’s no tree hierarchy; paths are for logical clarity. For instance:
This logical labeling groups configurations naturally while still using a sequential key registry underneath.
Interaction and API Design
etcd exposes a REST-compatible API accessible over HTTP with JSON payloads. Standard HTTP methods are used to manipulate keys:
This interface is platform-agnostic and integrates easily with scripts, service discovery tools, and orchestration workflows.
Behavior Monitoring and Notifications
Clients can subscribe to key changes using the built-in watch feature. Once a flag or setting is altered, all subscribed consumers instantly receive update notifications. This supports real-time configuration reloads and responsive behavior in dependent systems.
Internally, etcd captures historical state revisions of every key modification. Each mutation gets a unique revision index that lets clients retrieve data snapshots or subscribe to updates from a given version onward.
Example payload for a data fetch:
Security and Access Control
etcd enforces encrypted transport using TLS between servers and clients. Authentication mechanisms allow integration with RBAC (role-based access control), enabling granularity in terms of who can read, write, or delete specific keys.
Activities across the system can be logged for audit trails. This enables traceability for operations, ensuring that changes to sensitive settings are recorded and reviewable.
Resilience and Redundancy
Clusters are composed of 3, 5, or 7 members so a majority can always be present to make decisions. Operations continue uninterrupted if a minority of nodes go offline. This setup minimizes service disruption while ensuring data integrity even during outages or maintenance.
Each node can serve read requests, but fault-tolerant writing requires consensus alignment. If the leader node is unreachable, no writes are processed until a new leader is elected, preserving consistency.
Cluster state visualization example:
Use-Case Scenarios
Often paired with orchestrators or cluster managers, etcd holds critical values such as:
- Service Registry: Services advertise themselves here so others can locate them dynamically.
- Live Configuration Store: Updated environment parameters without redeploying software.
- Coordination Locks: Distributed locking to manage race-sensitive operations.
- Leadership Negotiation: Backing high-availability patterns that choose leaders among instances.
Comparison: etcd vs Relational Storage Systems
etcd restricts itself to precise, high-speed updates and synchronized reads where data correctness is more critical than advanced querying. For business logic, reporting, or archival storage, general-purpose databases remain more appropriate.
Storage Engine and Performance Notes
Internally, etcd stores its records using BoltDB—a file-based, transaction-safe key-value backend implemented in Go. This ensures ACID compliance and keeps all data resident within a single file structure on disk.
Read-heavy tasks can be scaled as all nodes handle queries. However, write throughput is constrained by the single-leader architecture. Large payloads or oversized serialized data (e.g., binary files or large JSON documents) should be avoided to sustain optimal speed and reliability.
Language Bindings and SDKs
Developers working in ecosystems that demand native integrations can rely on official SDKs and community-maintained libraries:
- Go:
go.etcd.io/etcd/client/v3 - Python:
etcd3,python-etcd - Java:
jetcd - Node.js:
node-etcd
These SDKs simplify retries, error parsing, and watch subscriptions with APIs tailored to the language runtime, avoiding repetitive boilerplate code.
Boundaries and Constraints
etcd was not built for storing multi-megabyte payloads or binary blobs. The leader-based write model introduces throughput limitations as every mutation must travel through the cluster head. High-latency connections among members can impair responsiveness.
When used for the wrong roles—such as storing logs or user data—etcd’s performance bottlenecks become evident. Proper partitioning of concerns is essential for maximizing its strengths in state coordination, not primary data hosting.
Characteristic Summary
etcd remains a vital layer in modern control plane infrastructure, tuned for precision, repeatability, and operational consistency within clustered deployments.
How etcd Works: The Raft Consensus Algorithm Made Simple
Raft Consensus Mechanics in etcd
Raft drives etcd’s consistency by coordinating replicas to behave as one reliable unit. Every node plays a specific role in maintaining this coordinated state, using timeouts, log replication, elections, and snapshots to guard against failures and inconsistencies.
Node Responsibilities: Leader, Follower, Candidate
In a Raft-based cluster, nodes cycle through three distinct states:
- Leader: Central command under normal operations. Handles write operations, replicates logs, and manages client requests.
- Follower: Actively listens, acknowledges incoming instructions from the leader, and stays synchronized by copying logs.
- Candidate: Emerges when a follower experiences silence long enough to believe the leader is down. Initiates a leadership contest.
Nodes begin as followers. They switch to candidate mode upon missing expected updates from the leader. Elections run when these candidates broadcast vote requests. A candidate achieving majority support assumes leadership.
Update Propagation: Replicating Logs Across the Cluster
Each change to etcd’s internal state starts at the leader. Upon receiving a request, the leader:
- Records the command in its own in-memory log.
- Notifies followers by transmitting new entry proposals.
- Waits until a majority acknowledges the new log item.
- Marks the entry as committed and applies it locally.
- Instructs followers to follow suit with application.
This flow forces all active nodes to reach agreement before any state change becomes visible.
Example:
- A client issues
PUT /feature/enabled true. - Leader registers this in its log at index 120, term 8.
- Followers receive the item, confirm acceptance.
- Once three of five nodes confirm, entry 120 commits.
- The command updates each node’s state machine safely.
Fallback logic ensures a lagging follower fetches the missed entries to restore synchronization.
Dynamic Leadership: Reassigning Control When Failure Occurs
When the leader’s presence diminishes—due to crash, disconnection, or delay—remaining nodes detect the timeout individually. Upon suspicion of vacancy:
- A follower escalates to candidate.
- It bumps the term counter.
- Broadcasts vote solicitations.
- Votes for itself.
Candidates receiving the highest number of votes (more than half of the cluster) assume leadership. If no guard wins, the voting epoch repeats, using staggered timeouts to prevent vote deadlocks.
Staggering is vital. Random delays between 150–300 milliseconds reduce the likelihood that multiple nodes nominate themselves simultaneously, decreasing tied outcomes and accelerating convergence.
Timeline and Accuracy: Term Increments, Log Indexes
Two identifiers ensure ordering and leader legitimacy:
- Term: Election counter, incremented whenever leadership passes.
- Index: Position of an operation in the persistent log.
Each log item is encoded with both fields. During elections or recovery, followers evaluate a candidate’s logs: a node with the higher term or log completeness gets preference. This process avoids promoting outdated data.
If a candidate has fewer or earlier entries compared to voters, it fails to obtain majority support, avoiding accidental regressions.
Handling Partial Failures: Quorums and Redundancy
Raft maintains progress even when some nodes fail by requiring only a majority to agree on operations. In an N-node setup, it tolerates up to (N-1)/2 failures.
This guarantees fault-tolerance by preventing scenarios in which a minority of potentially inconsistent nodes take control.
Space Efficiency: Snapshots and Log Compaction
For long-running clusters, the log can become unmanageably large. etcd addresses this via:
- Snapshot: Captures the current full application state.
- Compaction: Deletes confirmed log entries preceding a snapshot.
Suppose log entries span from index 1 to 25,000. Taking a snapshot after index 24,000 allows safe deletion of the earlier entries, reducing I/O and memory use.
When a new replica joins, it downloads the snapshot and unreconciled entries, bringing it completely in sync without going through every historic operation.
Health Checks: Heartbeats Prevent Leadership Drift
The leader periodically transmits minimal messages—called heartbeats—at short intervals (e.g., 100ms). These messages signal continuity of leadership.
Followers use an election timeout (e.g., randomly picked between 150ms–300ms) to expect incoming heartbeats. A missed interval triggers the election sequence.
This guarantees constant monitoring, ensuring that a leader failure doesn’t go unnoticed and that response to failure begins promptly.
Structured Simplicity: Raft vs Paxos
Raft’s architecture differs significantly from traditional consensus models like Paxos. Raft is algorithmically structured around clarity and modular operation.
etcd leverages Raft because it better supports real-world production needs where clarity and reliability override theoretical compactness.
Code Example: Appending New Entries in a Raft Node
A simplified Raft update handler in Go might resemble:
This is abstracted but illustrates the basic pattern: construct log, store locally, replicate outward.
Internal Details in etcd's Implementation
etcd runs its own Raft engine (etcd/raft), a production-hardened component handling:
- Persistent entry storage and applied snapshots
- Controlled leadership turnover via term tracking
- Majority-driven coordination of commits
- Repair routines for failed or lagging members
This engine operates independently of etcd's business logic, allowing it to serve as a reusable module within other distributed platforms.
Behavior Matrix: Raft Components Inside etcd
These elements contribute to the robustness required for infrastructure backbones like Kubernetes.
Key Advantages of etcd for Secure and Scalable Clusters
High Availability and Fault Tolerance Built-In
One of the most critical advantages of etcd is its built-in high availability and fault tolerance. In distributed systems, especially in Kubernetes clusters, maintaining availability even when some nodes fail is essential. etcd achieves this through its use of the Raft consensus algorithm, which ensures that the data remains consistent across all nodes, even in the event of hardware failures, network partitions, or other disruptions.
etcd requires a majority (quorum) of nodes to agree on any changes to the data. This means that even if some nodes go offline, as long as a quorum is maintained, the cluster continues to function correctly. For example, in a 5-node etcd cluster, any 3 nodes form a quorum. If 2 nodes fail, the remaining 3 can still make decisions and serve requests.
This fault tolerance is crucial for Kubernetes, where etcd stores all cluster state data. If etcd becomes unavailable or inconsistent, the entire Kubernetes control plane can become unstable. By using etcd, organizations ensure that their clusters remain resilient and operational under stress.
Strong Consistency Guarantees
etcd provides strong consistency, which means that every read returns the most recent write for a given key. This is a key advantage over eventually consistent systems, where reads might return stale data. In Kubernetes, where components like the scheduler, controller manager, and API server rely on accurate and up-to-date information, strong consistency is non-negotiable.
This consistency is achieved through the Raft algorithm, which ensures that all changes to the data are agreed upon by a majority of nodes before being committed. Once a change is committed, it is guaranteed to be durable and visible to all future reads.
For example, if a Kubernetes user updates a deployment, that change is written to etcd. Thanks to strong consistency, any subsequent read of that deployment will reflect the updated state, regardless of which etcd node is queried.
Lightweight and Fast Key-Value Store
Unlike traditional databases, etcd is a lightweight key-value store optimized for speed and simplicity. It is designed to handle small, frequent reads and writes with low latency. This makes it ideal for storing configuration data, service discovery information, and metadata in distributed systems.
etcd uses a flat key space, where keys are organized in a directory-like structure. This allows for efficient lookups and updates. For example:
This simplicity allows etcd to perform well even under heavy load. It can handle thousands of requests per second with minimal resource usage, making it suitable for large-scale Kubernetes clusters.
Secure by Design
Security is a top priority in modern cloud-native environments, and etcd is built with security in mind. It supports Transport Layer Security (TLS) for all communication between clients and peers. This ensures that data in transit is encrypted and protected from eavesdropping or tampering.
etcd also supports role-based access control (RBAC), allowing administrators to define fine-grained permissions for different users and applications. This prevents unauthorized access to sensitive data stored in etcd.
For example, you can create a role that only allows read access to a specific key prefix:
This level of control is essential for securing the control plane of Kubernetes and ensuring that only trusted components can modify cluster state.
Horizontal Scalability for Large Clusters
While etcd is not designed for massive horizontal scaling like some NoSQL databases, it supports clustering and can scale to meet the needs of large Kubernetes deployments. A typical etcd cluster consists of 3, 5, or 7 nodes, which provides a balance between performance and fault tolerance.
Each node in the cluster participates in the Raft consensus process, and the cluster can handle a high volume of concurrent reads and writes. For read-heavy workloads, etcd supports linearizable and serializable reads, allowing clients to choose between consistency and performance.
In large Kubernetes clusters with thousands of nodes and workloads, etcd remains performant and reliable. Administrators can monitor etcd performance using built-in metrics and adjust cluster size or tuning parameters as needed.
Easy Backup and Disaster Recovery
etcd provides built-in tools for creating consistent snapshots of the data store. These snapshots can be used for backup and disaster recovery, ensuring that critical cluster state can be restored in the event of data loss or corruption.
Creating a snapshot is as simple as running a command:
Restoring from a snapshot is also straightforward:
This simplicity makes it easy for DevOps teams to implement regular backup schedules and recovery plans. In regulated industries where data durability and auditability are required, etcd’s snapshot feature is a major advantage.
Minimal Operational Overhead
etcd is designed to be easy to deploy, configure, and maintain. It has a small binary footprint and minimal dependencies, making it suitable for containerized environments and automated deployment pipelines.
Configuration is done via command-line flags or environment variables, and etcd integrates well with systemd, Kubernetes, and other orchestration tools. Health checks, metrics, and logging are built-in, allowing for seamless integration with monitoring systems like Prometheus and Grafana.
Here’s an example of a simple etcd systemd service file:
This low operational overhead allows teams to focus on building and scaling applications rather than managing infrastructure.
Comparison Table: etcd vs. Other Key-Value Stores
Real-Time Watch and Event Notification
etcd supports a powerful watch mechanism that allows clients to subscribe to changes in specific keys or key prefixes. This is essential for building reactive systems where components need to respond to configuration changes or service discovery updates in real time.
For example, a Kubernetes controller can watch for changes in pod definitions and take action immediately when a new pod is scheduled or deleted.
This feature enables dynamic and event-driven architectures, reducing the need for polling and improving system responsiveness.
Transaction Support for Atomic Operations
etcd supports transactions, allowing multiple operations to be executed atomically. This is useful for ensuring data integrity when performing complex updates or conditional writes.
A transaction in etcd consists of a set of compare, then, and else operations. For example:
This ensures that updates only occur if certain conditions are met, preventing race conditions and inconsistent state.
Summary of Key Advantages
- High Availability: Survives node failures with quorum-based consensus.
- Strong Consistency: Guarantees up-to-date reads across the cluster.
- Security: TLS encryption and RBAC for secure access control.
- Performance: Fast, lightweight, and optimized for frequent updates.
- Scalability: Supports large clusters with efficient read/write handling.
- Ease of Use: Simple deployment, configuration, and maintenance.
- Backup and Recovery: Built-in snapshot and restore tools.
- Event-Driven: Real-time watch support for reactive systems.
- Atomic Transactions: Ensures data integrity with conditional operations.
These features make etcd a foundational component for secure and scalable Kubernetes clusters, enabling reliable orchestration of modern cloud-native applications.
etcd in Practice: A Practical Example
In a real-world Kubernetes environment, etcd plays a silent but critical role. It acts as the single source of truth for all cluster data. Every time you create a pod, deploy a service, or scale an application, the configuration and state of that action are stored in etcd. Let’s walk through a practical example of how etcd operates behind the scenes in a Kubernetes cluster, and how it ensures consistency, availability, and reliability.
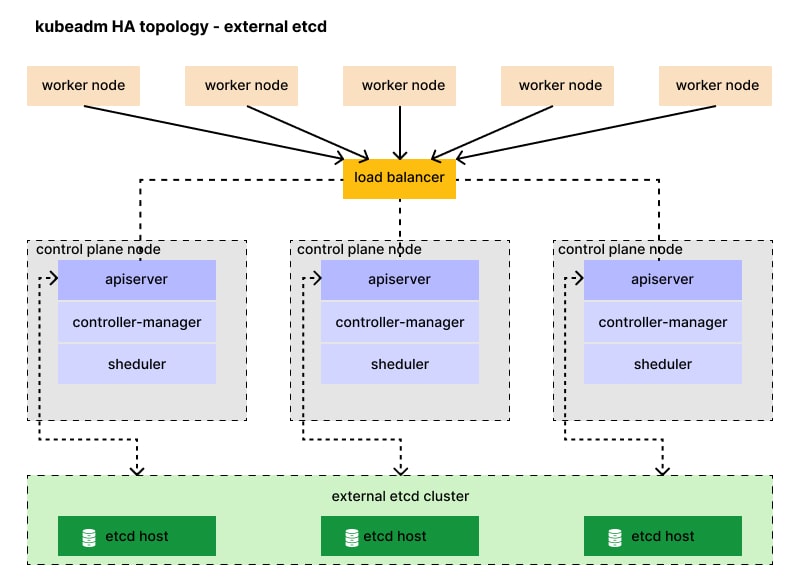
Kubernetes Cluster Architecture with etcd
In a typical Kubernetes cluster, the control plane is made up of several components:
- kube-apiserver: The front-end for the Kubernetes control plane.
- kube-controller-manager: Handles background tasks like node health checks and replication.
- kube-scheduler: Assigns workloads to nodes.
- etcd: Stores all cluster data.
etcd is not just a database; it is the backbone of the Kubernetes control plane. Every component in the control plane interacts with etcd to read or write cluster state.
Here’s a simplified diagram of how etcd fits into the Kubernetes control plane:
A Practical Workflow: Deploying an Application
Let’s say you want to deploy a simple NGINX web server in your Kubernetes cluster. You use a YAML file like this:
You apply this configuration using kubectl:
Here’s what happens step-by-step:
- kubectl sends the request to kube-apiserver.
- kube-apiserver validates the request and writes the desired state (3 replicas of NGINX) to etcd.
- etcd stores this state as a key-value pair. The key might look like
/registry/deployments/default/nginx-deployment. - kube-controller-manager watches etcd for changes. It sees the new deployment and starts creating pods.
- Pods are scheduled by kube-scheduler, and their details are also stored in etcd.
- If a pod crashes, the controller notices the difference between the desired state (3 pods) and the current state (2 pods), and creates a new one.
This entire process is powered by etcd’s ability to store, watch, and update the cluster state in real time.
etcd Key Structure in Kubernetes
etcd stores data in a hierarchical key-value format. Here’s a simplified view of how Kubernetes stores data in etcd:
Each key holds a serialized object in JSON or Protobuf format. These objects represent the current state of the cluster.
Watching etcd in Action
You can observe etcd’s behavior by watching changes in real time. For example, if you have access to the etcd cluster, you can use the etcdctl command-line tool:
This will show you the keys related to your deployment.
To watch changes:
This command will stream updates as new pods are created, deleted, or modified.
etcd Snapshots and Disaster Recovery
In production environments, backing up etcd is essential. If etcd data is lost, the entire cluster state is gone. Kubernetes provides tools to take snapshots of etcd.
Here’s how you might take a snapshot:
To restore from a snapshot:
This is critical for disaster recovery scenarios.
High Availability Setup for etcd in Kubernetes
In production, etcd should be deployed in a highly available configuration. This typically means running an odd number of etcd nodes (3, 5, or 7) to maintain quorum.
Kubernetes clusters often run etcd as static pods on control plane nodes. These pods are defined in /etc/kubernetes/manifests/etcd.yaml.
Example etcd pod manifest snippet:
etcd Failure Scenarios in Kubernetes
Let’s explore what happens when etcd fails in a Kubernetes cluster.
Scenario 1: etcd is down, but kube-apiserver is running
- You can’t make any changes to the cluster.
- Existing workloads continue to run.
- New pods can’t be scheduled.
- Cluster state is frozen.
Scenario 2: etcd data is corrupted
- The cluster may enter a degraded state.
- You must restore from a snapshot.
- If no backup exists, the cluster must be rebuilt.
Scenario 3: etcd loses quorum
- Writes are rejected.
- Reads may still work (depending on configuration).
- Cluster becomes read-only.
etcd Security in Kubernetes
etcd stores sensitive data, including secrets and service account tokens. Securing etcd is non-negotiable.
Best practices include:
- Enable TLS encryption for client and peer communication.
- Use role-based access control (RBAC) to limit who can access etcd.
- Encrypt secrets at rest using Kubernetes encryption providers.
- Restrict access to etcd ports (default: 2379 for client, 2380 for peer).
Example: Enabling encryption at rest in Kubernetes
Apply this configuration by updating the --encryption-provider-config flag in the kube-apiserver manifest.
etcd Metrics and Monitoring
Monitoring etcd is essential for maintaining cluster health. etcd exposes metrics on a dedicated endpoint (/metrics) that can be scraped by Prometheus.
Key metrics to watch:
etcd_server_has_leader: Should always be 1.etcd_server_leader_changes_seen_total: High values may indicate instability.etcd_disk_backend_commit_duration_seconds: Measures disk I/O performance.etcd_mvcc_db_total_size_in_bytes: Size of the database.
Example Prometheus query:
This alerts you if the etcd cluster has lost its leader.
Summary Table: etcd in Kubernetes Use Cases
etcdctl vs. kubectl: When to Use What
Use kubectl for day-to-day operations. Use etcdctl for low-level troubleshooting, backups, and restores.
Real-World Example: etcd Outage in Production
A financial services company ran a 5-node Kubernetes cluster with a 3-node etcd setup. During a routine upgrade, two etcd nodes were accidentally rebooted at the same time. The remaining node could not form a quorum. The cluster became read-only. No new deployments could be made. Fortunately, the team had recent etcd snapshots and restored the cluster within 30 minutes.
Lessons learned:
- Always maintain an odd number of etcd nodes.
- Automate etcd backups.
- Monitor etcd quorum status.
This example-driven breakdown shows how deeply integrated etcd is in Kubernetes operations. From pod scheduling to disaster recovery, etcd is the invisible engine that keeps your cluster running smoothly.
etcd vs. ZooKeeper, Consul, and Redis: A Head-to-Head Comparison
Purpose and Architectural Intent
Consensus and Data Synchronization Mechanisms
Raft centralizes updates through a chosen leader. Followers duplicate entries only after the leader has committed, ensuring high data integrity with binary log replication.
Zab, implemented by ZooKeeper, emphasizes synchronized transaction ordering across participants. During failures, uncommitted transactions are rolled back and quorum reestablishment ensures full cluster restoration.
Redis, in standalone or cluster mode, replicates primary node data to replicas asynchronously. Cluster setups use hash ranges to load-balance keys, and automatic failover can happen via built-in cluster coordination or Redis Sentinel.
Execution Efficiency and Expandability
etcd and ZooKeeper favor smaller cluster topologies that avoid quorum split risk. Both enforce consistency but sacrifice scalability. Consul tolerates wider deployments across zones. Redis reacts the fastest under heavy workloads and demands stronger external orchestration for full durability.
Operational Footprint and Flexibility
Setting up etcd or Consul is aided by extensive tooling and observability hooks. ZooKeeper relies on Java legacy conventions and lacks built-in metrics integration. Redis prioritizes speed and simplicity with tooling delegated to companion services.
Role Assignments and Scenarios
Commands and Examples
Matrix of Technical Priorities
etcd and Kubernetes: A Core Relationship
etcd’s Role in Kubernetes State Persistence
etcd functions as the authoritative key-value database behind Kubernetes orchestration. It retains all metadata, live status, and configuration definitions essential to construct and maintain the cluster’s desired behavior. Without etcd’s entries, Kubernetes loses awareness of infrastructure composition and control logic.
etcd's data acts as the real-time mirror of cluster topology. The API server is the only access point to this data and serves as a validation proxy. Controllers and other state managers listen for record deltas and continuously align the actual environment with the expected specification.
Cluster State Reconciliation Engine
Definitions pushed via kubectl initiate full-cycle workflows that revolve around etcd. Kubernetes acts as a control loop system: the declarative config becomes the source of truth, stored in etcd, while control layers reconfigure live systems to eliminate mismatches.
Example propagation sequence:
- YAML describing a Deployment is submitted via
kubectl. - Kubernetes API server verifies the request and registers the object in etcd.
- Controller Manager scans etcd changes, then provisions ReplicaSets or scales active ones.
- The Scheduler receives pending pod metadata and selects optimal nodes.
- Pod-node bindings are recorded in etcd, visible to Kubelets.
- Kubelets act upon bindings by pulling artifacts, launching containers, and reporting status.
All operations pass through etcd—asylum where both cluster intent and cluster condition converge. Even a scale-down or deletion action results in a state update back into this core store.
Safeguards Through Distributed Agreement
Kubernetes clusters depend on durable etcd lifecycles to remain operable. If etcd becomes inconsistent or unavailable, Kubernetes loses its coordination ability. For redundancy, etcd runs in a cluster model: numerous instances reach consensus before entries become persistent.
The system uses the Raft consensus protocol to maintain consistency. Control plane nodes synchronize updates, minimize conflicts, and allow leadership re-election without downtime. Hosting etcd leaders across failure domains—zones, racks, or data centers—helps tolerate local disruptions.
etcd Snapshotting and Data Resilience
Cluster recovery workflows rely on stored snapshots of etcd’s keyspace. These backups preserve runtime data and declarative configurations at a given moment. If disaster strikes—data corruption, node loss, or accident—an admin can restore from stored snapshots.
Command to capture an etcd backup image:
Command to recover from an existing snapshot:
After restoration, services must be pointed at the new data directory. Once etcd resumes syncing, Kubernetes reads historical objects and resumes normal operations.
Locking Down etcd From Untrusted Access
Secrets, tokens, and user roles live inside etcd, making its security posture critical. Every transaction must be wrapped with mutual TLS and verified with signed certificates. Kubernetes supports encrypting sensitive kinds like secrets before they leave the apiserver.
Encryption policy manifest for secret obfuscation:
Only the API server has decryption access. Exposure of disk files storing etcd payloads does not compromise content confidentiality unless private keys are also leaked.
Communication Pathways to etcd Within the Control Plane
Interaction with etcd is isolated to select control plane layers to enforce consistency and protect write integrity. Not every Kubernetes agent talks directly to etcd.
This strict layering shields etcd from accidental writes or malformed queries, preserving object integrity across controllers and clients.
Performance Optimization and Lifecycle Vitality
Heavy use of the Kubernetes API results in rapid etcd growth across minor revisions. Without clean-up, this leads to disk bloat and degraded memory efficiency. Regular maintenance keeps access latency down.
Clear out old history:
Compress files and reclaim space:
Ensure SSD-class storage for etcd volumes and cap node sprawl in a single cluster to avoid performance ceilings.
Behavior Patterns When etcd Malfunctions
If etcd is no longer reachable or becomes corrupted, Kubernetes control logic halts. Already-running workloads keep executing, but no new pods are scheduled, scaled, or modified until connectivity returns.
Administrators monitor for degraded leader election times, replication lags, and high memory pressure to prevent silent drift or impending crashes in etcd.
The History and Maintenance of etcd: Who Builds and Supports It?
Origins of etcd: A Solution Born from Real Infrastructure Needs
etcd was not created in a vacuum. It was born out of a growing need for a reliable, distributed key-value store that could serve as the backbone of modern cloud-native systems. The project was initiated by CoreOS in 2013, a company that focused on building lightweight, secure operating systems for containerized environments. At the time, CoreOS was working on a new kind of Linux distribution optimized for running containers at scale. They needed a way to manage configuration data and coordinate distributed systems reliably. Existing tools like ZooKeeper were either too complex or not well-suited for container-native environments.
The name "etcd" is a play on Unix’s /etc directory, which traditionally stores configuration files. The "d" stands for "distributed," reflecting its purpose as a distributed configuration store. From the beginning, etcd was designed to be simple, secure, and consistent. It was written in Go, a language known for its concurrency support and performance, making it ideal for distributed systems.
The Role of CoreOS and the Transition to CNCF
CoreOS maintained etcd actively and used it as a core component in their Tectonic Kubernetes platform. As Kubernetes gained popularity, etcd became more critical. Kubernetes needed a consistent and highly available store for all its cluster state data—etcd was the perfect fit.
In 2018, Red Hat acquired CoreOS, and shortly after, Red Hat itself was acquired by IBM. During this transition, the future of etcd could have become uncertain. However, recognizing its importance to the Kubernetes ecosystem, the project was donated to the Cloud Native Computing Foundation (CNCF) in December 2018. This move ensured that etcd would remain vendor-neutral and community-driven.
The CNCF is a part of the Linux Foundation and hosts many of the most important open-source projects in cloud-native computing, including Kubernetes, Prometheus, and Envoy. By joining CNCF, etcd gained access to a broader community of contributors, better governance, and long-term sustainability.
Governance and Maintenance: Who Keeps etcd Running?
etcd is maintained by a group of core maintainers and contributors from various companies, not just Red Hat or IBM. These maintainers are responsible for reviewing code, managing releases, fixing bugs, and ensuring the project adheres to its security and performance standards.
The governance model follows the CNCF’s guidelines, which emphasize transparency, meritocracy, and community involvement. Decisions are made through open discussions on GitHub and mailing lists. Anyone can propose changes, but only maintainers can approve them.
The current list of maintainers includes engineers from companies like Google, Alibaba, Red Hat, and independent contributors. This diversity helps ensure that no single company controls the project, which is crucial for long-term trust and adoption.
Maintenance Workflow
The maintenance process for etcd is rigorous and well-documented. Here's a simplified overview of how it works:
- Issue Reporting: Users report bugs or request features via GitHub issues.
- Triage: Maintainers triage issues, label them, and prioritize based on severity and impact.
- Development: Contributors submit pull requests (PRs) to address issues or add features.
- Review: PRs undergo code review by at least one maintainer.
- Testing: Automated tests run on every PR. Manual testing is done for complex changes.
- Merge: Once approved and tested, the PR is merged into the main branch.
- Release: New versions are tagged and released following semantic versioning.
This process ensures that etcd remains stable, secure, and performant.
Release Cadence and Versioning
etcd follows a regular release schedule that aligns closely with Kubernetes. Typically, a new minor version of etcd is released every three to four months. Each release includes new features, bug fixes, and performance improvements. Security patches are released as needed.
etcd uses semantic versioning (SemVer), which means:
- Major versions introduce breaking changes.
- Minor versions add features in a backward-compatible manner.
- Patch versions fix bugs without changing the API.
For example:
This predictable versioning helps developers plan upgrades and integrations more effectively.
Security Practices and CVE Management
Security is a top priority for the etcd maintainers. The project has a dedicated security team that handles vulnerability reports. If a security issue is discovered, it is reported privately to the security team, who then work on a fix before disclosing the issue publicly.
etcd follows the CNCF’s security disclosure guidelines. Once a fix is ready, a new release is made, and a Common Vulnerabilities and Exposures (CVE) ID is assigned. This process ensures that users can patch their systems quickly and safely.
Security features built into etcd include:
- TLS encryption for all client-server and peer-to-peer communication.
- Authentication and role-based access control (RBAC).
- Audit logging to track access and changes.
- Snapshot and backup tools to recover from data loss or corruption.
Community Contributions and Ecosystem Support
etcd has a vibrant community of contributors. As of 2024, the GitHub repository has over 10,000 stars, 300+ contributors, and thousands of commits. Contributions come from individuals, startups, and large enterprises alike.
The project also benefits from a rich ecosystem of tools and libraries. For example:
- etcdctl: A command-line tool for interacting with etcd.
- etcd-operator: Automates deployment and management of etcd clusters on Kubernetes.
- Client libraries: Available in Go, Python, Java, and other languages.
These tools make it easier for developers and DevOps teams to integrate etcd into their workflows.
Comparison Table: etcd vs. Other CNCF Projects in Terms of Governance
This table shows that etcd is on par with other critical cloud-native projects in terms of governance and maturity.
Long-Term Support and Stability Guarantees
etcd maintainers provide long-term support (LTS) for major versions that are widely adopted. For example, etcd 3.5 is expected to receive bug fixes and security updates for several years. This stability is essential for enterprises that need to plan infrastructure upgrades carefully.
The Kubernetes project also specifies which etcd versions are compatible with each Kubernetes release. This tight integration ensures that users can upgrade both components smoothly.
Funding and Sponsorship
While etcd is open-source, it benefits from financial and infrastructure support through the CNCF. Sponsors of CNCF include major cloud providers like AWS, Google Cloud, Microsoft Azure, and Alibaba Cloud. These companies contribute not just money but also engineering resources to maintain and improve etcd.
This backing ensures that etcd remains free to use while still receiving the attention and resources needed to evolve.
Code Quality and Testing Infrastructure
etcd has a comprehensive testing infrastructure that includes:
- Unit tests for individual components.
- Integration tests for end-to-end scenarios.
- Fuzz testing to discover edge-case bugs.
- Performance benchmarks to track regressions.
All tests run automatically on every pull request using continuous integration (CI) pipelines. This ensures that new code doesn’t break existing functionality.
Here’s a simplified example of a test case in Go:
This test ensures that a key-value pair can be written and read correctly, a basic but essential function of etcd.
Documentation and Developer Support
etcd offers extensive documentation, including:
- Getting started guides
- API references
- Operational best practices
- Security hardening tips
The documentation is hosted on the official etcd website and is regularly updated by the community. There are also community forums, Slack channels, and GitHub Discussions where users can ask questions and share knowledge.
Summary Table: Key Maintenance Features of etcd
This table highlights the robust maintenance ecosystem that keeps etcd reliable and secure for production use.
Final Thoughts: Why API Security Teams Should Care About etcd
In the world of cloud-native infrastructure, API security teams often focus on the obvious: securing endpoints, validating tokens, encrypting traffic, and monitoring for anomalies. But there’s a critical component that often flies under the radar—etcd, the distributed key-value store that powers Kubernetes. While it may seem like a backend concern for DevOps or platform engineers, etcd is a goldmine of sensitive data and a potential attack vector that API security teams cannot afford to ignore.
etcd: The Hidden API Security Risk
etcd is not just a configuration store. It holds the entire state of a Kubernetes cluster, including:
- Secrets (if not encrypted at rest)
- Service discovery data
- Network policies
- Role-based access control (RBAC) configurations
- Pod and container metadata
- TLS certificates and keys
If an attacker gains access to etcd, they can potentially extract all of this information, manipulate cluster behavior, or even escalate privileges. This makes etcd a high-value target in any Kubernetes environment.
Real-World Attack Scenarios Involving etcd
Let’s break down a few scenarios where an insecure etcd instance can lead to serious API security breaches:
These are not theoretical risks. Misconfigured etcd instances have been found in the wild, often indexed by search engines like Shodan. Once discovered, attackers can exploit them within minutes.
Why API Security Teams Must Monitor etcd
API security is not just about protecting the surface—it’s about protecting the entire stack. Here’s why etcd should be on every API security team’s radar:
1. etcd Stores API Tokens and Secrets
Many Kubernetes workloads use secrets to authenticate with external APIs. These secrets are stored in etcd. If etcd is compromised, so are the APIs those secrets access.
2. etcd Reflects the API Attack Surface
etcd contains metadata about services, endpoints, and ingress configurations. This metadata can be used to map the API attack surface, including internal APIs not exposed externally.
3. etcd Can Be Used to Inject Malicious API Behavior
By modifying service definitions or ingress rules in etcd, an attacker can redirect traffic, inject malicious middleware, or expose internal APIs to the public internet.
4. etcd is a Single Point of Failure
Because etcd holds the entire cluster state, any compromise can affect every API running in the cluster. This makes it a critical component for maintaining API integrity and availability.
Best Practices for Securing etcd in API-Driven Environments
API security teams should work closely with DevOps and platform engineers to ensure etcd is properly secured. Here are some concrete steps:
- Enable encryption at rest: Encrypt all data stored in etcd, especially secrets and tokens.
- Use mutual TLS (mTLS): Require client and server certificates for all etcd communication.
- Restrict access: Only allow access to etcd from trusted IPs and authenticated users.
- Audit etcd access logs: Monitor for unusual access patterns or unauthorized queries.
- Backup securely: Ensure etcd backups are encrypted and stored securely.
- Rotate secrets regularly: Even if etcd is compromised, rotating secrets limits the damage.
API Security Monitoring: etcd as a Data Source
API security tools often focus on traffic analysis, but etcd can serve as a powerful data source for understanding the internal API landscape. By analyzing etcd, security teams can:
- Discover undocumented APIs
- Identify deprecated or vulnerable services
- Detect configuration drift
- Monitor for unauthorized changes to API routing or access controls
This makes etcd not just a risk, but also a resource for proactive API security.
Comparison: etcd vs. Traditional API Security Tools
As shown, etcd complements traditional API security tools by offering a configuration-level view of the API environment.
Integrating etcd Monitoring into API Security Workflows
To fully leverage etcd for API security, teams should integrate etcd monitoring into their CI/CD and runtime workflows. This can include:
- Pre-deployment checks: Validate etcd configurations before applying them.
- Runtime monitoring: Continuously watch for changes in etcd that affect API behavior.
- Incident response: Use etcd logs and snapshots to investigate API-related incidents.
This integration ensures that API security is not just reactive but also proactive and configuration-aware.
Try Wallarm AASM: Discover and Secure Your API Ecosystem
If you’re looking to take your API security to the next level, consider trying Wallarm API Attack Surface Management (AASM). This agentless solution is designed specifically for the API ecosystem and offers:
- Discovery of external hosts and their APIs: Map your entire API landscape, including shadow APIs.
- Identification of missing WAF/WAAP protections: Find gaps in your API perimeter defenses.
- Vulnerability detection: Spot misconfigurations and known CVEs in your API stack.
- API leak mitigation: Detect and respond to exposed secrets, tokens, and sensitive data.
Wallarm AASM doesn’t require agents or invasive instrumentation. It works seamlessly with your existing infrastructure, including Kubernetes and etcd, to provide a complete view of your API attack surface.
Engage to try this product for free at https://www.wallarm.com/product/aasm-sign-up?internal_utm_source=whats and start securing your APIs from the inside out.
FAQ
Subscribe for the latest news





















































.jpeg)

