See Wallarm's AI Control Platform In Action
Apache Beam vs Flink Stream Processing

Introduction to Stream Processing
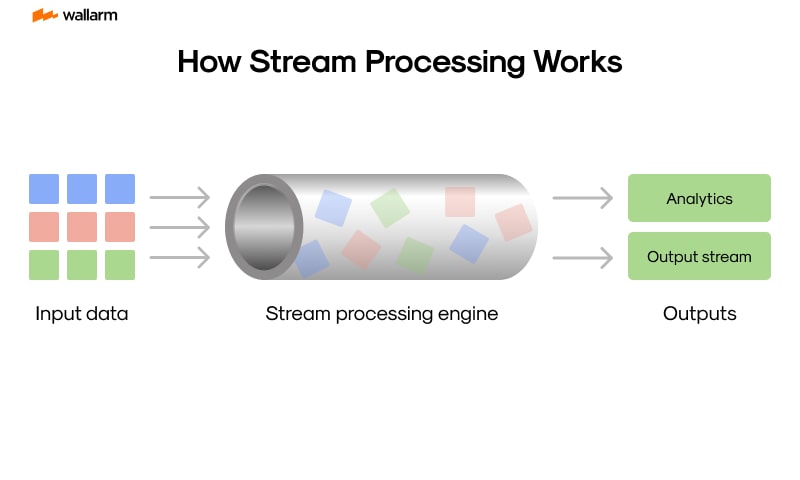
Navigating the Arena of Datastream Manipulation
Massive strides in the field of datastream manipulation, also widely known as realtime event computing, have triggered a seismic shift in the technological space. This dynamic model propels ahead by seamlessly processing endless, real-time data streams, thereby equipping firms with actionable insights that critically steer their decision-making.
Dissecting Datastream Manipulation
At the core, datastream manipulation is an organized approach to data management where incoming informations are instantly scrutinized, weighted, and decoded, almost concurrently with their generation. For this process, data sets could be obtained from varied sources such as digital user interactions, devices powered by the Internet of Things (IoT), social media platforms, or financial operations. This relentless influx of data is swiftly processed, and corresponding measures are taken rooted in the gleaned insights - a feature that sets it apart from traditional methodologies.
Contrary to the traditional batch processing approach, which accumulates data over fixed periods before processing them as a consolidated lot, datastream manipulation stands out due to its capability to process data concurrently with their generation. This makes it an ideal solution for contexts demanding immediate response and actionable intelligence.
Integral Facets of Datastream Manipulation
Few critical components together constitute datastream manipulation:
- Data Acquisition: The first step entails gathering and channelling data from diverse sources into the datastream processing mechanism. Despite differing attributes or origins, any material can be transformed into a datastream.
- Data Handling: Once data is acquired, instantaneous data operations are performed. This involves steps like data filtering, amalgamation, transformation, or enhancement.
- Data Scrutiny: The curated data is then inspected to discern valuable insights. This can involve intricate event scrutiny, machine learning algorithm applications, or other modified data analysis schemas.
- Action Initiation: Based on the insights derived from the data scrutiny, appropriate countersteps are put into action. It could range from generating alerts, updating dashboards, triggering data workflows, or porting the data to another system for more in-depth analysis.
Highlighting Datastream Manipulation Systems: Contrasting Apache Beam and Flink
Today, the market offers a variety of datastream processing systems, each with its distinct pros and cons. Among the variety, Apache Beam and Apache Flink garner a lot of attention. Both are part of the open-source community and tailored specifically to cater to extensive, real-time data processing tasks. Nevertheless, they differ in terms of architectural blueprint, operational features, and user experience. Conducting a thorough exploration and contrast of these two systems would help in selecting the most compatible solution for particular requirements regarding datastream manipulation.
The Crucial Impact of Datastream Manipulation within the Big Data Framework
Conclusively, datastream manipulation commands a pivotal role within the big data domain, endowing businesses with the power to process and dissect data at an unprecedented pace, derive consequential information, and respond expeditiously. Armed with an apt datastream manipulation mechanism, corporations can unlock the latent potential hidden in their data, forging a path towards insightful decision-making, augmenting operational efficacy, and carving an edge in the progressively data-bound business landscape.
Unveiling Apache Beam
The pioneering system coined as Apache Beam, initiated under the credible umbrella of Apache Software Foundation, operates as an ingenious mechanism to manage concurrent information processing systems. The distinguishing aspect of this technology is its well-integrated blend of batch and real time processing capabilities, which bestow significant control over large sets of data. Moreover, it permits the creation of processing pipelines across a range of computational ecosystems.
Detailed Examination of Apache Beam
One must appreciate the fact that Apache Beam stands apart in its architectural model because of its unfaltering capability to switch between finite (termed as bounded) and eternal (termed as unbounded) data modules. Limited data could comprise of filtered datasets such as a particular file or resultant of a database query. Contrarily, unbounded data would be continuous such as a nonstop stream of system logs or minute-by-minute updates from the world of finance.
The principal components of Apache Beam are PTransforms (Parallel Transforms), essentially elements that metamorphose a conglomerate of data, labeled as PCollection. Tasks performed by PTransforms can range from simple functions like mapping or filtering to complex operations involving multiple steps.
To deal with unending datasets, Apache Beam has perfected a system of windowing and triggers. In this context, windowing helps partition data into practical, temporal compartments while triggers help determine the timing for the results of each window to be disclosed.
Fundamental Traits of Apache Beam
- Multi-faceted Architecture: Beam presents a composite model that caters to the simultaneous demands of batch and instantaneous data processing, facilitating unified coding for both types of data tasks.
- Versatility: Pipelines conceived with Beam can be initiated on numerous platforms such as Apache Flink, Apache Samza, and Google Cloud Dataflow. This versatile operating system ensures that developers can conceive their pipeline once and deploy it universally.
- Windowing and Triggers: Beam amalgamates cutting-edge methods of windowing and triggering, augmenting the ability to manage both finite and infinite data feeds.
- Software Development Kits (SDKs): Beam's cater to developers' preference for coding languages by providing SDKs in multiple languages such as Java, Python, and Go.
The piece of code above reflects a Beam pipeline that sifts through a text document, isolating and extracting interesting lines, and forwards the output to a separate file.
Operating Principle of Apache Beam
The operational tenet of Apache Beam is best explained by its pipeline model. This structure interconnects the transformations (PTransforms) applied on a data group (PCollection). A runner organizes and oversees the execution of the pipeline, transmuting the pipeline into a malleable procedure and instigating it on a scattered data processing platform.
The working mechanism of Beam divorces the pipeline drawing board from its execution, facilitating operational agility and broad-spectrum application. Consequently, a preset pipeline can function on varied platforms without the need to tweak the code.
To summarise, Apache Beam introduces a sturdy and adaptable framework equipped to manage high-capacity data processing requirements. Its singular design, operational dynamism, and avant-garde features make it an attractive contender in the comprehensive environment of batch and real-time data processing.
Delving into Apache Flink
Apache Flink, available to all as a cost-free, open-sourced resource, has become a game-changer in handling copious data streams with finesse and efficiency. A sharp rise in its user-base attests to Flink's exceptional capacity for scrutinizing hefty data volumes, offering a platform for prompt analytics and data-driven observations. By interacting with constant data flows, it contributes to swift and precise data dispatch and distribution.
Flink's Integral Components
Flink's functionality is deeply rooted in a dataflow programming paradigm, where data streams flow continuously through a multitude of operations, making it proficient in grappling with high-volume data traffic.
Key elements that construct Flink's groundwork include:
- DataStream API: The primary tool of Flink overseeing data stream administration. It offers an abstract layer for outlining alterations to the data streams.
- DataSet API: While DataStream API focuses on ceaseless data streams, DataSet API caters to the requirement of working on data batches.
- Table API and SQL: Beyond clamping down on stream regulation, Flink proficiently extends its role in performing relational data operations using its Table API and SQL port. This paves the way for elaborate analytical computations on the manipulated data.
- State and Fault Tolerance: Flink ensures steadfast state maintenance coupled with hardy fault resistance. This mitigates data loss during system glitches and retains result accuracy.
Flink's System Architecture
Renowned for its flexible, performance-oriented design, Flink's architecture is tailored specifically for resilient stream management. It comprises a few vital components:
- JobManager: The crucial controller supervising task performance, governing everything from task programming, resource allotment to failure rectification.
- TaskManager: These sub-units carry out the actual task executions. They multitask actively, juggling numerous tasks simultaneously.
- Flink Runtime: This integral part provides the crucial runtime environment overseeing task execution and controlling data flow.
- Flink Cluster: This refers to a cluster of systems executing Flink tasks. It accommodates several platforms, like standalone, YARN, Mesos, and Kubernetes, adding to its adaptability.
Flink's Command Over Stream Processing
Flink takes pride in its superior prowess in handling data streams. It can supervise event time processing, windowing, and intricate event processing. Flink houses a diverse operator selection for data stream modifications like map, filter, reduce, and join.
It adopts a "stream transformations" strategy where it uses one or more input streams and delivers one or more output streams. These transformations are strung together to generate a dataflow diagram, visually representing the computation process.
Consider this modest example of a Flink data stream task:
Flink's Performance Scalability
Flink was developed with a focus on delivering exceptional performance and scalability. It claims the ability to process countless events per second with minimal lags. Flink can amplify its scale to thousands of nodes, thereby allowing the manipulation of vast data quantities.
This is courtesy of the deliberate memory management technique, a streamlined method of implementation, and built-in support for recursive algorithms. Its scalability is primarily attributed to its distributed design and adjustable execution options.
In a nutshell, Apache Flink is a robust, adaptable solution for administering data streams, boasting a suite of notable features and capabilities. It ascends as a first-rate option for applications revolving around real-time data operations.
Detailed Comparison: Apache Beam vs Flink- Stream Processing Showdown
In the vast domain of data stream management, platforms such as Apache Beam and Apache Flink have definitively staked their claims. Their impenetrable open-source infrastructures, unrivaled resilience, and varied implementations make them standouts. However, these two platforms exhibit unique attributes in several significant spheres, as this comprehensive review reveals.
Data Management Techniques
With reference to processing models, Apache Beam employs a human-like versatility. It skilfully handles both real-time and batch data processing. The essence of Beam's model is a construct called PCollection or Parallel Collection, depicting a distributed, static data set. This allows Beam to flexibly handle assorted data sources, independent of whether their boundaries are defined or undefined.
On the other hand, Flink operates principally on the basis of stream processing, interpreting batch data management as an instance of real-time processing with a defined beginning and end point. The model of Flink is embodied in the concepts of DataStream and DataSet, representations for unrestricted and restricted data streams, respectively.
Sequencing and Marking Exemplar
Apache Beam and Apache Flink employ systems of windowing and watermarking, essential components for handling non-sequential data in stream processing. Yet, their application methods differ materially.
Apache Beam manifests a nuanced set of foundation elements for windowing and watermarking. It offers users the ability to construct tailored windowing techniques. Beam's marking scheme exhibits remarkable flexibility, enabling the handling of backward-looking data and possible result revisions even after a window is marked as complete.
In contrast, Apache Flink uses windowing and watermarking systems in a more conventional manner. While it allows custom windowing techniques, it doesn't share Beam's level of flexibility. Flink's marking system is more rigid and doesn't handle late data as efficiently.
Data Security and Consistency Standards
The principles of data protection and consistency are critical in any stream management system. This is recognized by both Apache Beam and Apache Flink.
Beam's data protection strategy operates behind the scenes. The user is presented with basic data protection elements, with the core data protection managed by the runner. Likewise, Beam's approach to consistency is runner-based.
Flink, by contrast, has built-in data protection and consistency mechanisms. It provides a sophisticated set of data protection foundational units and facilitates comprehensive control over data protection. The consistency of Flink originates from the use of distributed snapshots, bolstering its reliability.
Execution Techniques and Scalability
Apache Beam is formulated to be autonomous from the runner. It offers an API that obscures the underlying execution engine, permitting users to toggle between various runners without changing their coding.
Flink, on the other hand, functions as both a structure and an execution engine. It offers its runtime environment and does not need external runners for operation. This autonomy makes Flink self-reliant, but it limits flexibility when considering scalability options.
Support Base and Integration Capacity
With robust and growing supporter networks, both Apache Beam and Apache Flink continue to gain momentum. However, Flink has a larger following due to a more developed user base and a broader range of third-party integrations. Although Beam’s supporter network is smaller, it is growing rapidly and has robust backing from Google.
In summary, while both Apache Beam and Apache Flink are prominent players in the domain of stream processing, their advantages and disadvantages set them apart. Beam’s adaptability makes it the go-to choice for users looking for flexibility, whereas Flink with its inherent data management and strong integrity measures is favored by users seeking a reliable and all-encompassing solution.
Understanding the Architecture: Apache Beam
Apache Beam represents a robust mechanism designed to enable efficient and adaptable data processing pathways. The project thrives under the wings of Apache Software Foundation and serves as an open-source platform. The architecture of Apache Beam is meticulously curated to handle batch as well as real-time data processing.
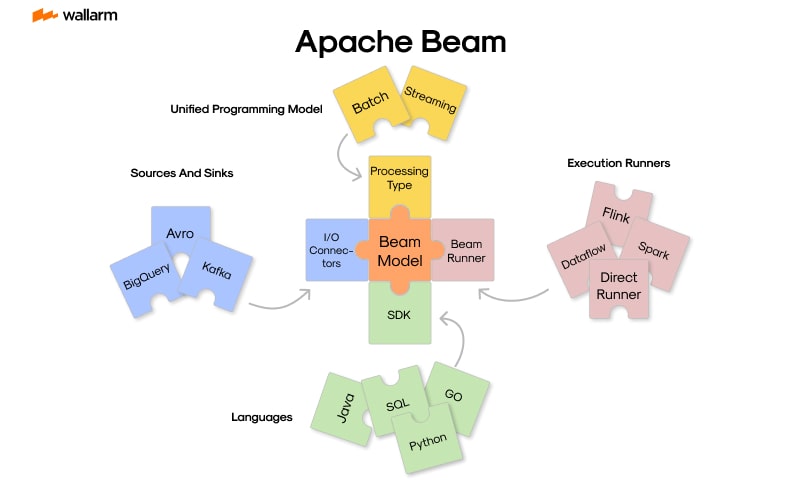
Core Components of Apache Beam’s Framework
Apache Beam operates on an intricate infrastructure that comprises several essential building blocks:
- Pipeline: The pipeline signifies the core theoretical construct within the Apache Beam framework. It encapsulates the entire data processing endeavor, starting from the initial steps of data ingestion to the final stages of data dispatch.
- PCollection: Representing a distributed data collection, a PCollection is what the pipeline works on. Remarkably versatile, PCollections can accommodate both finite and infinite data volumes.
- PTransform: This signifies an individual data manipulation step within the pipeline. Notably, a PTransform processes input data received in the form of PCollections and subsequently produces output in the same format.
- Runner: The runner takes charge of implementing the pipeline across a designated operational environment. Apache Beam is compatible with a variety of runners, including but not restricted to Apache Flink, Apache Samza, and Google Cloud Dataflow.
Stages of Pipeline Operation within Apache Beam
The pipeline process in Apache Beam follows the pattern below:
- Outline the pipeline: This stage requires defining the data source, the transformations applied to the data, and the final data receptacle.
- Implement the pipeline: In this step, the selected runner executes the pipeline, translating it into an API suited to the target operation environment.
- Managing the pipeline: Tools provided by the runner enable careful watch over the pipeline’s progress and facilitate problem detection and resolution.
Capacity for Cross-Execution Environment Operation
The flexibility of Apache Beam in handling different operational scenarios comes from two key components: the Beam model and Beam SDKs. The former maps out the specifications for the fundamental Beam entities (PCollections, PTransforms, etc.) while the latter provides a foundation for constructing pipelines compatible with Beam model norms.
The language-independent nature of the Beam model allows Beam pipelines to be constructed in any language supported by a Beam SDK. Currently, Apache Beam offers SDK support for Java, Python, and Go.
The Role of Runner Architecture within Apache Beam
Designed with the purpose of turning Beam pipelines into the respective API of the execution setting, the runner structure within Apache Beam plays several vital roles in the pipeline execution process:
- Distributing data amid several workers
- Coordinating the execution of PTransforms
- Allocating resources
- Addressing pipeline failures
Thanks to its sophisticated runner structure, Apache Beam is capable of accommodating various operation settings, ranging from local runners used for testing and development to distributed runners geared for handling large-scale data processing operations.
Advanced Techniques of Windowing and Watermarking in Apache Beam
Apache Beam’s architecture supports refined windowing and watermarking techniques. Windowing allows the split of data into separate sections according to the data elements’ timestamps while watermarking provides a framework for tracking time progress in a data stream.
In summary, Apache Beam’s architectural design furnishes a flexible, powerful, and transportable platform for data processing, making it a prime choice for executing both batch and real-time processing operations.
Understanding the Architecture: Apache Flink
Apache Flink, a remarkable tool in the open-source category, demonstrates distinct dominance in regulating and overseeing substantial, ongoing data waveforms. This capability originates from its superior knack to supervise and alter a broad array of data coursing through varied ecosystems. Flink's inherent features place it in an advantageous position to handle massive amounts of data in real-time and conduct complex computations with barely noticeable latency.
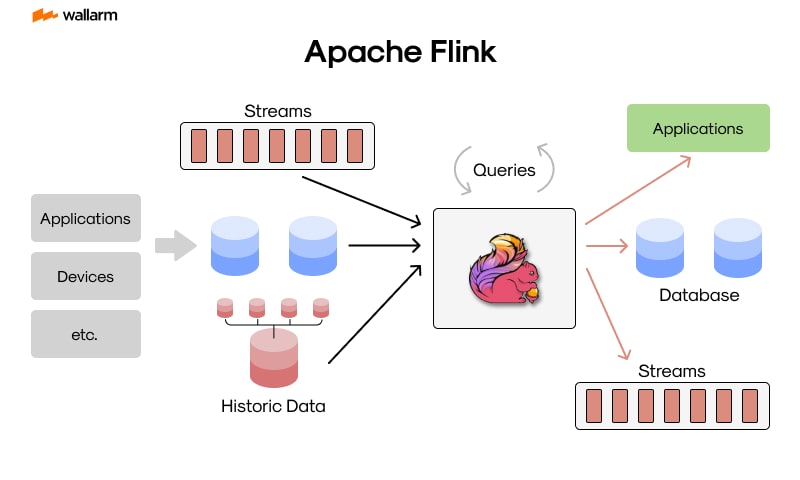
The Infrastructure of Flink
There are various integral elements that form the framework of Apache Flink, making data streaming seamless. These main elements encompass:
- JobManager: Functioning as the central coordination organ, JobManager governs Flink's mission accomplishment across the distributed network. It holds accountability for duty appointment, checkpoint oversight, and administering rectifying steps during system malfunctions.
- TaskManager: Acting as the workers, these nodes carry out the duties designated by the JobManager. Each TaskManager is equipped with various task slots, permitting parallel task execution.
- Flink Runtime: Recognized as the chief handler, this module establishes the execution roadmap for Flink duties. It presents a stable platform for Flink application advancement, offering support to both real-time and batch processing.
- Flink APIs: Flink furnishes multiple APIs which stimulate sturdy application fabrication. These APIs encompass the DataStream API for instantaneous data alteration, DataSet API for batch handling, and Table API accommodating SQL-like features.
Astute Data Examination by Flink
Apache Fink employs the principles of 'streams' and 'transformations' to steer data handling. Here, a stream symbolizes an unending data downpour while a transformation signifies a procedure that utilizes one or more input streams to generate output streams.
Through various transformation opportunities like map, filter, reduce, and join, Flink facilitates simple assembly of intricate data processing conduits, which are termed as Flink jobs.
Checkpoint Scheme by Flink
One of the standout features of Apache Flink's structure lies in its potent checkpoint infrastructure. In Flink vocabulary, a checkpoint is a reliable snapshot that logs the status of a Flink job at a specific instance.
Formulated to provide superior effectiveness, scalability, and minimum task performance disruption, Flink's checkpoints offer thorough and adjustable checkpoint creation with customizable schemes.
Flink's Method for Stability
Apache Flink's framework has been carefully crafted to effortlessly handle system faults. When a system failure occurs, Flink invokes the most recent successful checkpoint to recover the job status and restarts its operations from that instant, drastically reducing data loss and downtime.
Scalability Characteristics of Flink
The exceptional scalability of Apache Flink's framework can regulate massive data waveforms with unequalled throughput and barely perceptible latency. In addition, it is structured to increase its capacity across thousands of nodes to accommodate intricate and resource-intensive tasks.
In summary, the potency, flexibility, and scalability of Apache Flink's infrastructure make it a standout performer in managing data stream processing. Its main elements, astute data examination methods, checkpoint strategies, system stability and scalability boost its stature as a reputable solution for processing large quantities of real-time data streams.
Enterprise Use-Cases: Apache Beam
Apache Beam has become a formidable toolkit for creating and managing data processing structures, adept at dealing with a wide array of data forms, from static units to dynamically changing streams. Enterprises grappling with data-related hurdles benefit greatly from this tool, as it promises unfettered scalability, adaptability for changes, and competence to tackle combined data resources.
Accelerated Data Operation
One main advantage brought by Apache Beam is its capability to swiftly handle substantial data quantities. Fields such as e-commerce or digital platforms, where swift scrutiny of large pockets of data is crucial, appreciate Beam's expertise in both scenario-specific and instantaneous contexts. To illustrate, a digital media firm could use Beam to swiftly check out user interaction metrics, and deliver tailored content that aligns with the viewers' consumption tendencies.
Data Mutation and Enhancement
On many occasions, Apache Beam is utilized for data modification and enhancement. This operation entails transforming crude data units into a layout that better fits the client's needs or operational goals. Consider a corporation harnessing Beam to morph disordered log notes into a simplified, systematic format, easing data review and visualization. Also, Beam can be wielded to complement datasets by combining them with different data streams. For example, merging customer profiles with demographic data offers a comprehensive insight into consumer predilections.
Event-Driven Data Functions
Activities triggered by particular events or instances form another significant sector where Apache Beam is applied. This covers data transformations in response to unique triggers or situations. Think of a financial institution employing Beam to promptly treat monetary transactions and generate notifications echoing specific transactional tendencies.
Predictive Analysis and Machine Learning
The potency of Apache Beam in simultaneously handling massive data units enhances machine learning, and unravels potential future trends. Firms can harness Beam's strength to educate machine learning models on vast data quantities, promoting data-backed educated estimations and decisions. An application scenario would involve a business utilizing Beam to predict potential customer attrition based on historical user behavior data.
Interpreting IoT Data
Amid the ascending Internet of Things (IoT) trend, Apache Beam also facilitates understanding IoT data. Firms can dispatch Beam to quickly decode data received from IoT devices, revealing crucial insights for informed decision making. For a specific instance, a manufacturing facility might depend on Beam for expedited scrutiny of machine-related data, mitigating the risk of severe equipment failures.
In a nutshell, the flexible nature, limitless scalability, and capacity to oversee various data forms make Apache Beam a prime tool for a range of business landscapes. Whether for hastened data operations, data refashioning and enrichment, event-powered data functions, machine-assisted learning, predictive examination, or unraveling IoT data; Apache Beam sets itself as the critical tool for enterprises dealing with voluminous data piles.
Enterprise Use-Cases: Apache Flink
Apache Flink is known among data processing platforms for its marked performance in handling data streams—a reason it resonates within diverse global industries. This platform is heralded for its unique ways of addressing complex business situations. Below, we'll delve into several specific applications of Flink, highlighting its value in various fields.
Flink: An Ally in Accelerated Fraud Prevention
In sectors like finance, real-time surveillance of voluminous data is critical, especially when it comes to identifying and stopping fraudulent transactions promptly. Classic systems often lack effectiveness, primarily because they heavily depend on group computations, which can be inefficient in real-time applications.
One outstanding example is Alibaba, the Chinese trading titan. They harness the power of Flink within their advanced system for detecting fraud in real-time. This system scans through millions of transactions each day to find and tackle any unusual transactions. With Flink, Alibaba has considerably lowered the financial impact resulting from fraud, thus enhancing users' confidence substantially.
Streamlining Data Flow Analytics in Telecommunications
Industries like telecommunications produce immense data in microseconds, putting Flink's capabilities to test. Real-time analysis is mandatory here for tasks that range from improving networks and proactive system maintenance to building robust customer rapport.
Take the case of Bouygues Telecom—a top-notch telecom service provider in France. They utilize Flink to support real-time network monitoring and optimization. Equipped with Flink, they can quickly decipher network traffic patterns, identify potential faults, and resolve them instantly. This strategy considerably boosts their network performance and subsequently improves customer satisfaction.
Customizing Shopping Experiences with High-Speed Data Analysis
The e-commerce sector can benefit from quick analytics for personalizing product offers and enhancing client engagement. Flink stands as a star player here for its efficiency in handling large datasets nimbly.
A leading online apparel portal from Europe, Zalando, offers a prime example. They use Fink to power their on-the-fly analytics that processes millions of customer behaviors every second, providing immediate insights into customer trends. This prompt understanding allows Zalando to design individualized shopping experiences that can boost customer appeal, driving sales up.
Real-Time Data Processing for Improved IoT Data Governance
In IoT applications, the sheer volume of data that gets generated needs high-speed analysis for informed decision-making. Flink, skilled at data stream processing, offers the perfect solution to meet these challenges.
Take Uber as an example. This renowned ride-sharing app uses Flink for its real-time offerings. By managing real-time GPS data received from many riders and drivers, Flink enables Uber to effectively pair riders with suitable drivers. This Flink-driven measure has significantly improved Uber's ride-booking service efficiency.
To sum it up, Flink's robustness in processing data streams addresses diverse business requirements. From providing swift fraud detection in finance and network enhancements in telecom, to on-the-fly analysis in e-commerce and efficient data governance in IoT applications, Flink persistently manifests its value as a proficient and reliable tool.
Runtime Environment Considerations: Beam vs Flink
When examining stream computing ecosystems, we must shine a light on Apache Beam and Apache Flink. By delving into their functionalities and comparing their distinctive features, we can provide valuable insight on their selection.
The World of Apache Beam
Apache Beam serves as a dynamic scaffold that harmonizes with any chosen computational engine. This flexibility makes it a “universal translator” among different data processing architectures. Not only compatible with Flink, but it also operates in conjunction with Google Cloud Dataflow, Apache Samza, Spark, and others.
A great strength of Beam is its versatile environment. It maneuvers smoothly around batch and stream calculations, offering tools for real-time data processing through event-based capabilities and deferred data caterings.
Among the many hats that Beam wears, one that stands out is its ability to process data continuously (unbounded data) and data with defined parameters (bounded data). Beam comfortably handles both types of data.
The Realm of Apache Flink
On the flip side, stands Apache Flink, a stream computing design with an integrated runtime ecosystem, inherently a complete processing engine, rather than a mere universal translator like Beam. Flink is the go-to choice for swift processing of voluminous data.
While Flink interfaces with both batch and stream calculations, it majorly tilts towards the latter. It comes armed with features such as event-time metrics and watermark capabilities, crucial for managing out-of-sync conditions in a streaming scenario.
One of Flink's unique strengths is its capacity to continue computations despite interruptions, thanks to its resilience by adopting a technique called 'checkpointing, which preserves the ongoing state of a data processing journey at regular intervals.
Comparison: Apache Beam vs Apache Flink Operation Environment
In conclusion, both Apache Beam and Flink provide us with formidable environments for stream computations. Beam has a more placement-agnostic approach, making it adaptable across various computation backend systems. Nevertheless, Flink offers an inherently resilient, high-performance environment, offering built-in resilience features. Your choice between the two should hinge on your specific needs and data set properties.
Ease of Use and Flexibility: Apache Beam or Flink?
Stream processing instruments are constructed to skillfully decipher and steer clear of fresh data; yet, their simplicity and adaptability potential can influence their enactment and productivity. Let's examine and compare two such instruments, Apache Beam and Apache Flink, considering their simplicity and adaptability.
Simplicity
Apache Beam
The programming blueprints of Apache Beam provides both efficiency and simplicity, showcasing a collective architecture that enables the construction of applications to process real-time or batch data. Beam's structure provides the developers an edge to contrive intricate assignments with minimal effort by manipulating alterations to datasets.
Beyond this, Beam provides Software Development Kits (SDKs) fitting many popular programming languages such as Java, Python, and Go. This grants developers autonomy to employ their favourite language, rendering Beam more attractive.
However, one might regard the elevated abstraction in Beam as its Achilles heel. Despite expediting the formation of complex assignments, it could potentially cause hindrances when attempting to comprehend or troubleshoot the underlying execution tasks.
Apache Flink
Based on a more conventional track towards real-time data handling, Flink offers user-friendly interfaces that enhance the developer's understanding of the backend procedures.
Its compatibility extends to Java and Scala for real-time processing, enriched with an SQL API for structured data. This extends its utility to developers with a wide spectrum of experience, ranging from conventional database systems to big data situations.
Nevertheless, Flink's emphasis on raw command might escalate its complexities, primarily for newcomers. It demands profound understanding of the elementary principles and methods in stream processing.
Adaptability
Apache Beam
Beam flexes its muscles in adaptability, owing to its unified structure. This design allows the developers to construct applications competently dealing with both batch and real-time data. Thus, the same code can cater to both database models, optimising development time and energy.
Furthermore, Beam has competencies of dealing with event times and late data, vital for several real-time data scrutiny situations. An array of options for windowing and triggering is also offered, further escalating the control developers have over data management.
Apache Flink
Flink stands tall with its commendable adaptability. It possesses attributes for dealing with event time and late data, paired with an array of windowing options. Adding to that, Flink's architecture permits stateful calculations that could prove beneficial for complex processing assignments.
However, unlike Beam, Flink does not offer a unified architecture for batch and real-time data handling. Even though it presents batch processing capabilities, it demands different interfaces, possibly amplifying the time and energy needed for development.
Comparison Chart
In conclusion, both Apache Beam and Apache Flink offer substantial ease of use and adaptability, albeit in distinct manners. Beam's advanced level of abstraction paired with a unified model simplifies the process of constructing complex tasks but could also obfuscate understanding and troubleshooting these tasks. On the contrary, Flink's simplified route and comprehensible interfaces amplify its digestibility but could complicate matters for beginners. In terms of adaptability, Beam's combined model for handling both types of data (batch and streaming) gives it the upper hand, while Flink's support for stateful calculations benefits complex tasks.
Implementing Stream Processing with Apache Beam: A Hands-On Guide
Stream manipulation is a potent resource that enables companies to manage enormous quantities of data instantaneously. Apache Beam stands as a premier solution in this domain, furnishing a consolidated paradigm for developing and executing data manipulation schemes. This section will navigate you in integrating stream manipulation using Apache Beam.
Configuration of the Work Area
Prior to jumping into the technical nitty-gritty, it's crucial to orchestrate your work area. Apache Beam is proficient in several programming languages like Java, Python, and Go. We'll stick to Java for this manual.
- Deploy Java Development Kit (JDK) 8 or a newer version.
- Embed Apache Maven, an effective tool for software project administration.
- Construct a fresh Maven project and peppering the below dependencies in your pom.xml file:
Fabricating a Pipeline
The crux of any Apache Beam software is the pipeline. In essence, a pipeline is a chain of data manipulations. Here's the method to conceive a rudimentary pipeline:
Employing Transformations
Transformations constitute actions performed on data within the pipeline. The fundamental pair of transformations consists of PTransforms and DoFns.
A PTransform is a manipulation that can be employed to an input to yield an output. Below we have an instance of a PTransform that retrieves from a text file:
A DoFn is a function that deals with elements within a PCollection. Here's a prototype of a DoFn that bifurcates a line of text into words:
Executing the Pipeline
When the pipeline's designation is concluded, a runner can be utilized for its execution. Apache Beam is compatible with multiple runners, though for this manual, we'll utilize the DirectRunner, which performs pipelines on your local machine:
Summing Up
This manual delivered a fundamental tutorial on integrating stream manipulation using Apache Beam. While Beam might seem overwhelming initially, it delivers a strong, adaptable model for controlling enormous volumes of data on the fly. With consistent exercise, you can harness Beam's power to tackle intricate data manipulation chores effortlessly.
Implementing Stream Processing with Flink: A Step-by-Step Guide
Stream computing signifies a cutting-edge technique of handling and examining information instantly. A prominent and easily accessible tool for this function is Apache Flink. This manual aims to familiarize you with Apache Flink’s stream processing capabilities.
Initiate the Setup Process
Before you get started, ensure your system runs Java version 8 or above. Considering Apache Flink's built on Java and Scala, execution calls for a Java Runtime Environment (JRE). The latest Apache Flink release is obtainable directly from its official site. After the download is complete, uncompress the zip file and park it in a directory of your choice.
Kickstart Your Inaugural Flink Endeavor
The immediate task is to lay the foundation for a fresh Flink project. Feel free to utilize any Java IDE for this. This tutorial will demonstrate with IntelliJ IDEA. Kick things off by setting up a new Maven Project and incorporate the dependencies below into your pom.xml file:
Constructing Your Flink Craft
Moving on, let's fashion a simple Flink program. Create a new Java class and insert the following code:
This code generates a data stream from a fixed array of strings, uppercases each string via the map function, and finally displays the altered stream on the console.
Setting the Flink Code in Motion
To bring the application into action, simply right-click on the class in IntelliJ IDEA and select 'Run'. The console should then shoot up the results.
Implementing Complex Stream Processing Operations
The precursor example is quite elementary. In reality, data is often extracted from sources like Kafka, undergoes intensive transformations, and then the outcomes are committed to a destination like a database. Flink provides a thorough API for these tasks. For instance, the FlinkKafkaConsumer class can pull data from Kafka. For etching data into a database, a sink functionality can be utilized.
In summary, Apache Flink proves to be a robust tool for stream processing, with a clear API for shaping and evaluating data in real-time. This comprehensive tutorial equips you to handle stream-processing tasks using Apache Flink.
SDKs and Developer Tools: Beam vs Flink
In the sphere of stream data treatment, Apache Beam and Apache Flink stand out by providing extensive Software Development Kits (SDKs) and production tools. These aid in designing, scrutinizing, and initiating data handling schemes. We'll scrutinize the individual attributes of these services in this article, drawing comparisons to shed light on their utility.
Insight on Apache Beam's SDKs and Production Tools
Apache Beam boasts SDKs in assorted languages such as Java, Python, and Go. This benefit of language variety enables developers to select the language with which they're most proficient or best fits their project blueprint.
The Java SDK of Apache Beam is the most advanced, offering a spectrum of transformations and connectors. While the Python SDK is not as all-encompassing as the Java SDK, it nonetheless provides an impressive set of capabilities and is subject to continual enhancement. The Go SDK, being the most recent addition, is currently under trial.
For local testing and development, Apache Beam furnishes a Direct Runner. This runner operates pipelines on the developer's personal computer, providing a superb tool for development and debugging. Runner compatibility with Apache Flink, Apache Samza, and Google Cloud Dataflow enables developers to run their pipelines on different processing backends sans code modification.
Delving into Apache Flink's SDKs and Production Tools
In contrast, Apache Flink is primarily equipped with a Java/Scala SDK. This SDK is feature-packed, offering a broad scope of transformations, connectors, and windowing capabilities. Although Flink lacks native Python support, it compensates by offering PyFlink, a Python API. However, PyFlink is less extensive than the Java/Scala SDK and is ideal for straightforward data transformations.
A local execution environment is also offered by Flink for development and scrutiny. This environment enables local run of Flink applications, similar to Beam's Direct Runner. Furthermore, Flink’s web-based user platform provides in-depth analysis into running jobs, encompassing task execution, throughput rates, and data latency.
Java, Python & Go SDKs: Beam vs Flink
Apache Beam: Java SDK – Yes; Python SDK – Yes; Go SDK – In trial; Local Execution Environment – Yes (Direct Runner); Web-based UI – Absent
Apache Flink: Java SDK – Yes; Python SDK – Limited (available via PyFlink); Go SDK – Absent; Local Execution Environment – Yes; Web-based UI – Present
Production Tools: Beam vs Flink
Apache Beam: Local Testing and Debugging – Yes; Multiple Runner Support – Yes; In-depth Job Insight – Absent Apache Flink: Local Testing and Debugging – Yes; Multiple Runner Support – Absent; In-depth Job Insight – Yes (Web-based UI)
To recap, Apache Beam and Apache Flink both offer potent SDKs and production tools, each possessing unique merits and demerits. With its multi-language support and numerous runner capacities, Beam offers flexibility and versatility. Conversely, with its formidable Java/Scala SDK and insightful web-based UI, Flink stands as a powerful and easy-to-use option. The choice between these two depends on individual needs and preferences.
Performance Analysis: Beam and Flink's Stream Processing Speed
In the sphere of data stream manipulation, the efficiency of a software system depends heavily on its performance. In our analysis, we've decided to focus on Apache Beam and Apache Flink. These two software tools are among the most frequently adopted platforms for stream processing.
Evaluative Criteria
It's crucial to know the basis upon which we're comparing Apache Beam and Apache Flink. Our verdict is primarily centered on the following criteria:
- Data Processing Speed: The capacity of handling events per unit of time is measured in this metric. Greater processing speed implies superior performance.
- Processing Delay: Reflects the duration from the point an event is registered in the system to when it's processed. Lower time delays suggest more efficient system performance.
- Hardware Resources Recruitment: This embodies the volume of hardware assets–CPU, memory, and disk I/O–the system employs. The lesser the need for hardware resources, the better the system's performance.
Data Processing Speed Evaluation
The processing speed of Apache Beam noticeably varies based on the supporting runner it's using. When operated using Flink runner, Apache Beam's processing capacity rivals that of Flink’s native runner. Nevertheless, when used with Dataflow runner, Beam’s processing speed may drop due to Dataflow service's overheads.
Contrarily, Apache Flink has a reputation for its brisk processing speed. This edge is gained by incorporating a strategy known as pipelining, where data flows without disruption through the system, eliminating the necessity for temporary storage and hence bolsters throughput.
Processing Delay Evaluation
As with processing speed, Apache Beam's processing delay is contingent on the running software. With a Flink runner, it achieves a low delay, equaling native Flink. But the delay can increase if used with a Dataflow runner due to the overheads it generates.
Apache Flink was tailor-made to ensure minimal processing delays. Its first-stream approach substantiates this feature, where incoming data is immediately processed, meaning it doesn't accumulate within the system.
Hardware Resources Recruitment
Resource recruitment has a significant impact on performance. The resources employed by Apache Beam hinge upon the runner and the precise tasks at hand. In broad terms, Beam is designed for efficiency, though some runners can have a pronounced overhead.
Apache Flink is lauded for its conservative use of resources. It can achieve this thanks to an architectural design, which does away with the need for in-between storage, thus lightening the load on CPU and memory.
Real-World Performance
In pragmatic applications, Apache Beam and Apache Flink deliver remarkable performance. But the decision between these two usually hinges on the precise demands of the task at hand.
When high processing speeds and low delays are top priorities and you're fine with maintaining your infrastructure, Apache Flink might just be the answer. However, if you'd prefer a managed service, with a little trade-off in performance, then Apache Beam using the Dataflow runner can serve as a useful tool.
To sum it all up, Apache Beam and Apache Flink both offer impressive performance in stream processing tasks. Though, the decision between them will be shaped by your specific needs and constraints.
Fault Tolerance in Apache Beam and Flink
In the realm of stream processing operations, an ability to maintain functionality amidst system failures ranks as a crucial component. Crashes, network disconnections, or other mishaps do not need to halt important processes, thanks effectiveness of fault tolerance mechanisms. In the following discussion, we'll scrutinize the fault-tolerance strategies of Apache Beam and Apache Flink, delineating their principles and highlighting their comparative efficiency.
Resilience in Apache Beam: The Strategy
Apache Beam offers its durable functionality through a distinct pipeline framework. With a proclivity to process both batch and stream data, the resiliency of this system lies within its model's inherent capacity for data recovery post any system mishap.
Key to Beam's durability is its unique abstraction stratum. The advantages of this layer is twofold: The ability to function seamlessly across diverse execution environments, and the added fortification of employing the native protective measures of each engine. A classic illustration of this advantage is seen with Google Cloud Dataflow, where Beam capitalizes on inherent Dataflow's resilience features.
Moreover, Apache Beam maintains data uniformity with its 'exactly-once' processing concept: a system fail does not lead to data duplication or omission. Despite potential processing hiccups, Beam always carries out operations from the last consistent state.
Resilience in Apache Flink: The Method
Unlike Apache Beam, Apache Flink tackles system resilience through a technique known as 'checkpointing'. Here, computation states are periodically archived in a reliable storage medium, which could be revived to continue computation during system outage.
Flink's checkpointing method isn't just reliable; it's efficient too: The technique is both asynchronous and incremental—only amendments post the preceding checkpoint are archived. As a result, both data storage requirements and checkpoint creation duration are significantly reduced.
Flink also subscribes to the 'exactly-once' data processing axiom, but its implementation deviates from Beam's strategy. It instills 'barriers' within the data stream, essentially flags marking computation advancements. When system disruptions occur, these barriers facilitate the restoration of a consistent state and resumption of operations.
Beam versus Flink: Resilience Face-off
In sum, Apache Beam and Apache Flink exhibit strong system resilience capabilities. Beam's resilience hinges on the capabilities of the execution engine utilized, while Flink utilizes its native checkpointing system. Both systems ensure data uniformity through 'exactly-once' processing. Selecting between Beam and Flink though, would largely depend on certain specifics associated with a project—execution engine compatibility, recovery speed and processing efficiency paramount among them.
Scalability: Comparing Apache Beam and Flink
A Deep Dive into Apache Beam's Data Handling Prowess
Apache Beam stands tall due to its impressive ability to execute a broad spectrum of data procedures like static and dynamic data adjustments. With its inherent flexibility and functionality, Beam's influence continues to widen in the tech arena.
Rather than operating independently, Apache Beam harnesses a plethora of scattered computational assets including Google's Cloud Dataflow, Apache Flink, Apache Samza, and more. This partnership enhances its flexibility in handling diverse data control dilemmas. It accomplishes this effectiveness by utilizing distinctive system 'runners' to steer its algorithm procession.
For example, when Beam aligns with Apache Flink as its runner, it mirrors Flink's commendable chore distribution melodiousness. Similarly, while using Google's Cloud Dataflow, Beam profits from the auto-expansion capacity valuable in tackling massive data scales.
A Closer Look at Apache Flink's Data Administration Techniques
Apache Flink sets itself apart with an impressive range of data control techniques, placing it as a dominant player in the tech sphere. Its proficiency in chore distribution is outstanding, elegantly manipulating an excess of data by assigning chores across multiple nodes within interlinked data grids.
A unique quality of Flink lies in its dynamic chore slot modification feature. This capability provides a proactive solution for controlling unstable data flows with its ability to grow with the scale of incoming information.
Furthermore, Flink adopts the event-time principle and watermark strategies to ensure a reliable control mechanism amid unforeseen events and data spikes. This proves highly valuable when managing real-time data streams prone to regular changes and fluctuations.
A Comparative Analysis: Data Handling Techniques of Apache Beam and Apache Flink
Investigating the data adjustment proficiencies of Apache Beam and Apache Flink, taking into account diverse deployment scenarios and selected Beam runners, we can deduce the following:
This analysis illustrates that both Beam and Flink possess inherent abilities to manage batch and real-time data, showcase instantaneous expansion capability, and conform to the event time protocol. However, Beam's data management prowess largely hinges on the runner chosen. Fundamentally, Beam's processing power closely correlates with the capabilities of its appointed runner.
In conclusion, both Apache Beam and Apache Flink garner recognition for their distinctive data adjustment traits. Yet, Beam's operations greatly depend on its chosen runner, while Flink operates independently due to its innate data administration proficiencies. Hence, the deciding factor between selecting Beam or Flink rests majorly on unique project needs and the data handling efficiency of the Beam's chosen runner.
Cost Efficiency: Beam vs Flink in Stream Processing
Upon reviewing stream processing choices, managing expenses can greatly influence the decision between various frameworks. This write-up is designed to delve into the cost-benefits of Apache Beam and Apache Flink, two of the forerunners in the domain of stream processing.
Stream Processing: Economically-Savvy Approach
The nature of stream processing revolves around dealing with a continuous flow of data. Exceptionally resilient and scalable systems are needed to manage the colossal size and velocity of the provided data. Keeping budget constraints in mind, the economical viability of any stream processing system depends upon its ability to swiftly process sizeable data loads without overly draining computational resources.
Apache Beam: Prudent Spending
Apache Beam's laudable reputation primarily comes from its flexibility. It offers a user interface allowing developers to create data processing tasks adaptable to any execution platform. Such versatility gives rise to substantial financial advantages as it enables enterprises to opt for the most economically suitable execution platform.
Furthermore, Beam's competency in handling batch and stream processing collectively boosts its cost-effectiveness. Its harmonizing methodology towards these different types of processing eliminates the demand for multiple tools or independent infrastructure, thereby curtailing costs.
Beam's cost-benefit aspect significantly depends on the specific runner chosen. Each runner possesses distinct cost structures, necessitating careful selection of a runner that aligns with your financial and performance goals.
Apache Flink: Savvy Investments
On the contrary, Apache Flink features swift operation and minimal latencies. Its strong architectural design efficiently manages vast data without substantial resource utilization. Companies dealing with an abundance of data can reap significant cost savings from this feature.
Flink’s real-time data processing capacity further amplifies its cost advantage. Swift insights lead to immediate action, enhancing business outputs while reducing costs.
However, the cost benefits of Flink can vary depending upon the complexity of the data processing tasks at hand. More intricate tasks could potentially increase resource demands, leading to cost hikes.
Beam & Flink: A Cost-Aware Evaluation
When comparing Beam and Flink, both direct and indirect costs must be accounted for. Direct costs pertain to infrastructure and resources while indirect costs include expenses related to development, maintenance, and potential business implications.
In conclusion, Apache Beam and Apache Flink offer varying degrees of cost-effectiveness, each presenting unique advantages and restrictions. Opting for one over the other hinges on your specific use case, the complexity of processing your data, and cost-performance requirements.
Community Support and Future Updates: Apache Beam and Flink
When discussing the corporative individuals participating in the open-source projects of Apache Beam and Apache Flink, it's undeniable that their influence is significant and far-reaching. These two projects actively benefit from the dedicated participation of a committed and diverse group of developers and contributors.
Proactive Cooperation in Apache Beam
The synergy within the Apache Beam collaborators holds a noteworthy reputation due to its dynamism and vitality. They infuse life into the project through ceaseless developments, advancements, and revisions, making Apache Beam an all-embracing sphere for enthusiasts of all capacities and expertise levels.
Communication within the community is steadfast and inclusive, enabled by a frequently used electronic mailing tool alongside a specific message-based platform named Slack for knowledge exchange, collaboration and problem-solving. Frequently scheduled gatherings and conventions are an integral part of the Beam community, providing opportunities for face-to-face interaction, learning, and project enhancement discussion.
Anticipating the trajectory of prospective updates, these Beam contributors have shared a comprehensive plan manifesting the anticipated technological advances and newly injected capabilities in the public domain. They aim to fortify the Beam schema's operational efficiency and flexibility, sophisticate Beam SDKs, and widen compatibility for fresh and diverse coding languages.
Collaborative Strength in Apache Flink
Apache Flink also takes pride in an active community of devoted developers and contributors, who are recognized for their cooperative spirit. Contributors spanning the globe actively invest their time and expertise into refining Flink's features and functionality.
Staying connected via a utilized electronic mailing tool and a dedicated Slack platform, these collaborators can source answers to questions, generate new ideas, and work together on various Flink projects. The Flink community also architects regular interactive events to encourage participation, updates sharing and progression dissemination.
In the future-forward strategy, the Flink community has shared an elaborate plan for augmenting the platform with potential enhancements and functional add-ons. This allows broader contributions to the project trend. Key goals include heightening the efficacious factors of the Flink blueprint, the sophistication of Flink SDKs, and promoting compatibility for a broad range of programming languages.
Collective Analysis on Community Engagement and Evolution
To encapsulate, the dynamic communities of both Apache Beam and Flink demonstrate high resourcefulness and clear future development strategies. The selection between these two would pivot around the definitive stipulations of the project and the favored development team strategies.
Real World Case Studies: Apache Beam or Flink?
In the vast universe of complex data, tangible examples offer crucial understanding into the real-world usage and effectiveness of various data flow systems. In this segment, we will explore some prominent instances of how the Apache Beam and Apache Flink programs have been applied across different sectors, emphasizing their advantages and limitations under different conditions.
Illustration 1: PayPal's Association with Apache Beam
As a leading figure in the digital payment landscape, PayPal required a fortified and expansible solution to manage their immense flow of data. Their path led them to Apache Beam, appreciated for its capacity to deliver dual functioning – batch and stream processing – within a singular framework.
PayPal's data management requirements take a complex turn, with varied sources of data, diverse formats and different processing needs. With Apache Beam, they managed to construct a cohesive data handling pipeline capable of managing real-time and batch data. This not just made their data structure simpler, but also enhanced efficiency by abolishing the necessity for separate processing systems.
The quality of portability that Apache Beam possesses marked another decisive factor for PayPal. With Beam, they could script their data processing pipelines once and execute them on any operational engine, including Apache Flink, Apache Spark and Google Cloud Dataflow. This adaptability enabled them to pick the most suitable execution engine for each distinct scenario, optimizing performance and cost-effectiveness.
Illustration 2: Alibaba's Nexus with Apache Flink
Alibaba, holding the title of China's largest e-commerce entity, deals with billions of events per day. To handle this colossal volume of data in real-time, they approached Apache Flink.
The primary struggle for Alibaba was preserving low latency while dealing with high-volume data flows. Apache Flink, with its focus on data stream processing and adept windowing system, allowed Alibaba to handle data real-time with minimal delay.
The robust consistency assurances provided by Flink held crucial importance for Alibaba. The platform ensured Alibaba could maintain accurate outcomes even when faced with failures, which is critical for their real-time analytics and decision-making processes.
Plus, Flink's expansibility allowed Alibaba to deal with their increasing data volumes without any dip in performance. They could conveniently size their Flink clusters up or down according to need, ensuring efficient use of resources.
Comparative Examination
PayPal and Alibaba experienced significant benefits from their chosen data stream processing frameworks, however, the decisive factors behind their choices varied.
PayPal was attracted by the cohesive model and flexibility of Apache Beam, which helped them in simplifying their data structure and in selecting the most suitable execution engine per scenario. In contrast, Alibaba favored Apache Flink for its low-latency processing, solid consistency assurances, and adjustability. These attributes allowed Alibaba to deal with their substantial data flows promptly and correctly.
These instances underline the necessity for comprehending your distinctive data processing requisites and selecting an appropriate data flow system. Whether you lean towards Apache Beam or Apache Flink, both offer potent features and competencies that can assist you in efficiently managing your intricate data challenges.
Conclusion: Choosing between Apache Beam and Flink for Stream Processing
The field of data flow supervision, you will often find Apache Beam and Apache Flink fighting for the crown. However, pinning down the best option is not as easy as black and white; several factors need to be factored in. This ultimate handbook is built to guide you along the journey of selecting the perfectly tailored solution, aligning with your project's unique demands.
Decoding Project Specifications
The inaugural step to identify whether Apache Beam or Flink should be the data flow supervision tool for your mission, involves a deep dive into your project's exceptional stipulations. As an example, if you have a taxing task of tackling both on-demand and live data, Apache Beam's all-encompassing capabilities may hold the key. It's appreciated in our industry for seamlessly managing multiple data forms, negating the need for separate coding, thus keeping complexity at bay.
Flip the coin, and if your enterprise hinges on real-time data interpretation and cries out for nominal latency, Flink could be the ticket. It's tendency for speedily handling streaming data ensures almost instantaneous detection.
Estimating Protocol Understandability
A principle influencer in your decision-making should be the complexity level of each tool’s protocols. Apache Beam's paradigm can be deemed to be comparatively abstract, potentially erecting a steeper learning gradient, particularly for novices in the data flow supervision sphere. However, the initial struggle pays off in a formidable way, unveiling notable flexibility and control once mastered.
In contrast, Apache Flink acts as a welcoming doorway with its user-friendly API. Consequently, it stands as a worthy contender for squads who value quick deployment.
Gauging Performance and Adaptability
Each contender stands strong when it comes to performance and adaptability. Despite this, some subtleties persist. Apache Beam's performance is largely hinged on the efficiency of the supporting runner — superior runners like Flink or Google Cloud Dataflow ensure high quality execution and adaptability.
Meanwhile, Apache Flink basks in glory for its impressive quick data transmission and slim latency. This sets the stage for Flink to be an unbeatable choice for applications harping on live data processing. Additionally, Flink's linearity in adaptability ensures smooth sailing when handling bulky data volumes.
Considering Community Endorsement and Future Expansions
The final consideration is the extent of community endorsement and the pace of likely improvements. Apache Beam and Flink both boast bustling communities and relentless platform upgrades. Yet, Flink claims the upper hand with a more engaged community, making it a likely frontrunner if community endorsement is a deal-breaker for you.
To conclude, both Apache Beam and Flink demonstrate noticeable capabilities in data flow supervision, each offering unique strengths and weaknesses. The ultimate decision should focus on your project's specific demands, your squad’s prowess, and the nature of your project. By focusing on these criteria, you can confidently choose a method that will effectively exploit the possibilities of data flow management, maximizing effectiveness and competency.
FAQ
Subscribe for the latest news




















































.jpeg)


